





全文约3941字,阅读约23分钟







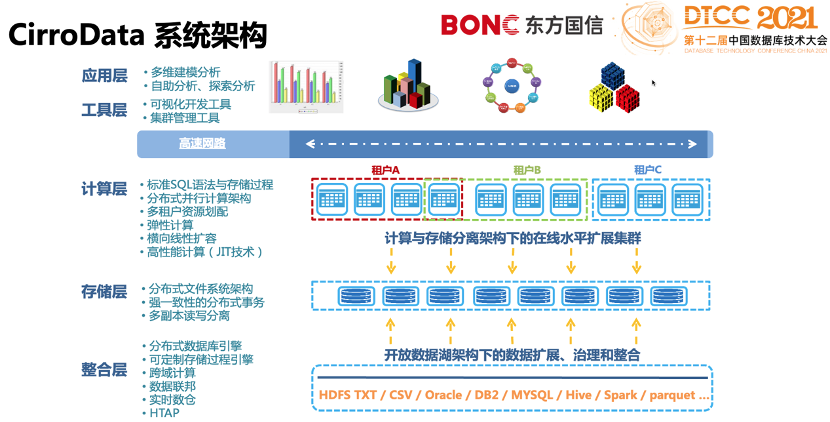
基于分布式数据库引擎的分布式数仓:数仓架构经历了集中式架构、MPP架构,直到现在发展到分布式架构。CirroData数据库遵循分布式中的墨菲定律、CAP原理等,运用数据位置感知、全局冗余策略、MVCC等技术,实现了分布式系统高效、一致、可靠工作。
基于跨域大数据组件的跨域数仓:东方国信一直以来立足于中国做项目,鉴于中国的特点是幅员辽阔,因此, CirroData数据库开发了具有跨域功能的数据库功能,可以实现跨省份的数据中心无感知(DataCenter Agnostic),使得数据分析可以超越空间的限制。
基于实时数仓组件的实时数仓:传统数仓只能分析T+1的数据,CirroData数据库通过对底层数仓结构的优化,可以完整支撑目前流行的实时数仓系统Lamda架构、Kappa架构、甚至是Omega架构等,可以完成对无界的流数据实时对接,使得数据分析可以超越时间的限制。
基于多数据源跨库组件的数据联邦数仓:互联网中有一个理念:不能重复造轮子,这个理念用到数仓中,就是数据复用或融合数仓。因此,CirroData数据库利用大数据中schema-on-read和schema evolution等“惰性计算”思想,开发了融合多种数据源的功能,使得数据分析可以超越系统的限制。
基于插件模块化设计的可定制数仓:从个性化支撑方面,CirroData数据库通过采用插件式模块化设计,可以允许用户实现可定制数仓,包括:数据引擎可定制、系统资源可定制、数仓工具可定制等;
基于融合型组件的全功能融合型数仓(关系型数据、时序数据、图数据):传统数仓中常常面临One size fits all的窘境,因此,东方国信CirroData数据库研发了一系列的产品:关系型数据库、时序数据库、图数据库。相信随着数仓应用不断发展,多模数仓一定会有广阔的发展空间。
计算存储分离架构: 实现分布式集群节点灵活搭配,分布式集群性能线性水平扩展;
分布式对等模型:这种模型超越了主从模型的局限性,可以实现无单点瓶颈,高并发、高可用、高可靠性;
全局弹性计算:分布式系统理论中有“计算移动快过数据移动”的金科定律,基于此定律我们进一步建立了精准的数据库代价模型,以便高效优化使用全局资源完成数据库任务;
在线水平线性扩展:就现在计算机硬件发展水平和发展速度来看,水平扩展架构已经取代了传统的垂直扩展架构,而且,CirroData数据库通过计算负载均衡策略和存储数据平衡等策略,完美地做到了在线和线性;
行列混合存储模式:通过计算和存储的高效配合,在发挥“列式存储”的信息熵更低、聚合性能更好的同时,也发挥“行式存储”的随机处理优势,使得CirroData数据库达到了一个更均衡的性能表现;
多租户集群资源规划:CirroData数据库通过资源隔离、资源纵切/横切、任务优先级等手段,保障了在多租户环境下的资源管理粒度和资源运用灵活度。

某通信运营商跨域协同查询案例:在这个案例中,运用CirroData数据中心无感知、透明数据等跨域技术,支撑我们的用户完成了跨地域的疫情精准防控。
某通信运营商实时数仓案例:在这个案例中,通过采用CirroData的实时数仓基础架构组件,结合整体实时数仓系统分层设计,完成了T+0经营分析的支撑。
某通信运营商跨CPU融合计算案例:在这个案例中,CirroData数据库在中国第一个做到了基于国产服务器和x86服务器构建统一数据库,实现了跨CPU融合计算。这不仅可以降低科技系统性风险,也为我国预防“卡脖子”等问题发生,为我国做到“关后门、堵漏洞、防断供”树立了典范样板,这在世界上也是首屈一指的。
某大型商业银行数据分析平台:银行业一直在使用IT中最先进的技术,纵观金融行业的发展史,它也是一部IT技术的发展史。在这个案例中,不但使用了CirroData数据库,还综合使用了我们多种数仓建设思想,包括:在基于传统银行业以结构化数据为主的特点下,运用了数据湖架构中的分区分池的思想,围绕业务分析应用来构建数据集市,同时使用了东方国信的数据编目、数据治理等方面的数据湖支撑工具,构筑了一个可用、可控、未来可发展的数据分析平台。



CirroData是北京东方国信科技股份有限公司自主研发的一款面向海量数据分析型应用领域的分布式云化数据库。采用了先进的计算和存储分离的技术架构,融合了分布式存储和MPP并行计算的各自优势,不但可以轻松实现云平台上的伸缩扩展能力,而且可以提供随需部署的能力,是新一代云数据仓库的典型代表。
CirroData能满足PB级海量数据的存储和分析,这些数据可以分布在数百台通用服务器上,能够被数千并发用户高速访问,可以满足数据密集型行业日益增大的海量数据存储、高性能加工,在线分析、即席查询和高并发访问的需求。

