




一、前言
上一篇文章【ORACLE】关于dbms_cloud包机制的一些研究
本来想弄腾讯云COS在ORACLE中的使用的,但是遇上了点麻烦,改程序还得等几天,实在憋不住想先搞个成功的案例,就想到了京东云,因为京东云OSS是几乎完全兼容aws的S3的,所以,理论上我只要在ORACLE中新增个京东云OSS的配置,然后套用亚马逊S3的程序即可,马上开干
二、准备工作
1.创建accesskey
也挺简单,进页面自己创建就行了
https://uc.jdcloud.com/account/accesskey
然后会获得“Access Key ID” 和“Access Key Secret”

2.创建OSS空间
这个进京东云自行创建就好了,
https://oss-console.jdcloud.com/space
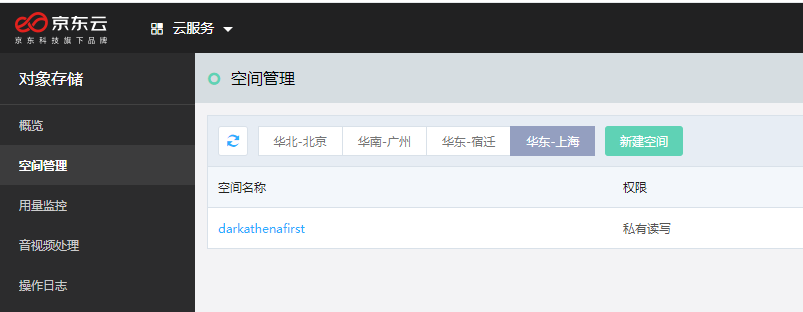
点进去看,可以得到bucket域名,这里根据你自己的情况选择,如果你oracle数据库也在京东云上,就用内网域名,否则就像我一样用外网域名
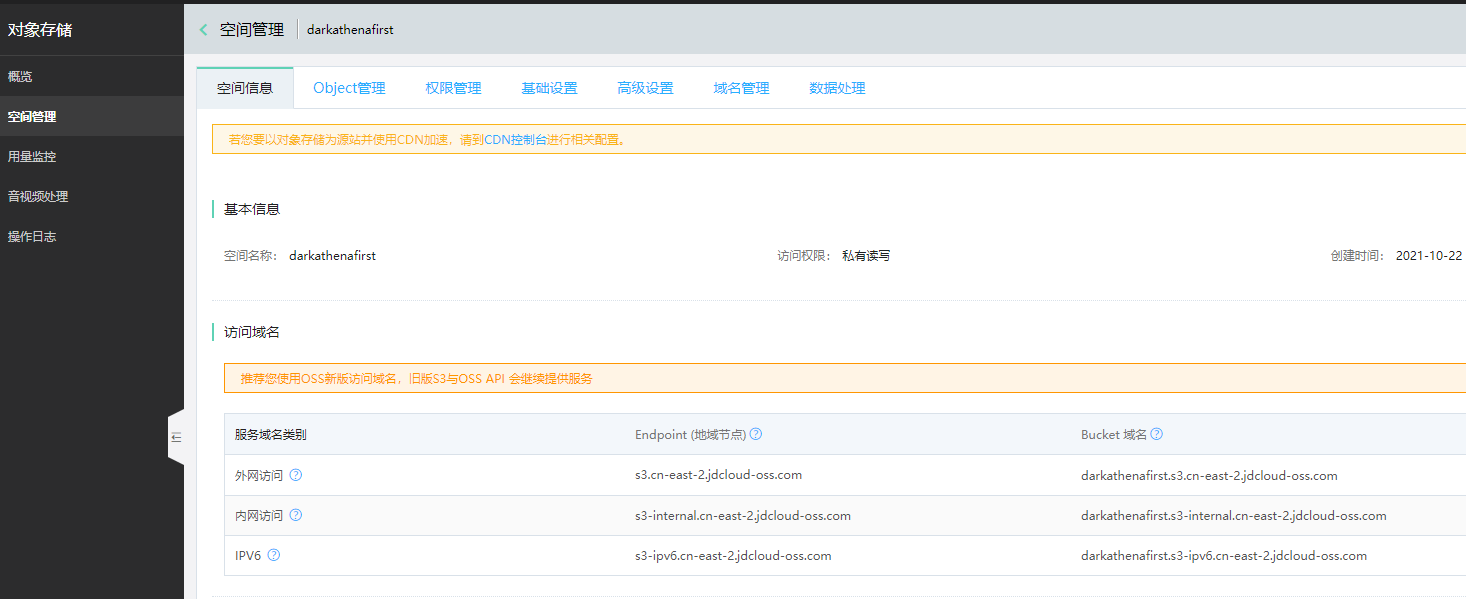
3.制作wallet
这个前面已经说过很多篇了,还不会的可以参考一下上一篇【ORACLE】关于dbms_cloud包机制的一些研究对于https的其实很简单,就用 https://oss-console.jdcloud.com/space 这个地址的证书
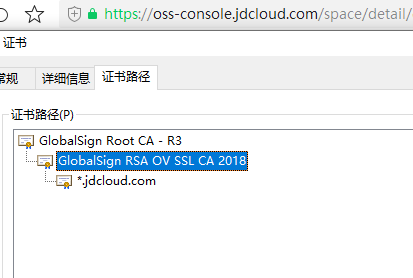
把这两个证书添加到wallet中,保存即可,我是直接用了上一篇保存的wallet,反正oracle已经把这个wallet的路径写进全局参数了。再次提醒,ORACLE12c以后的wallet都不要添加末级证书

4.在oracle中创建认证
begin
dbms_cloud.create_credential (
credential_name => 'obj_store_cred_jd',
username => 'JDC_*************C097',
password => 'E1C7E***************60F2'
);
end;
/
复制这里的“username”和“password”分别就是“Access Key ID” 和“Access Key Secret”
5.在数据库中新增京东云的配置
insert into dbms_cloud_store
(cloud_type, base_uri_pattern, version, status)
values
('AMAZON_S3', '%jdcloud%', '', 1);
commit;
复制三、使用
1.上传文件
我们先在本地创建一个csv文件,我保存在了数据库目录“PY_FILE”对应的操作系统路径下,文件名为“test_upload.csv”,文件内容为
1,aaa,AAAA, 2,bbb,BBBB, 3,ccc,CCCC,复制
然后执行
begin
dbms_cloud.put_object (
credential_name => 'OBJ_STORE_CRED_JD',
object_uri => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
directory_name => 'PY_FILE',
file_name => 'test_upload.csv');
end;
/
复制一次过,进京东云oss,查看object
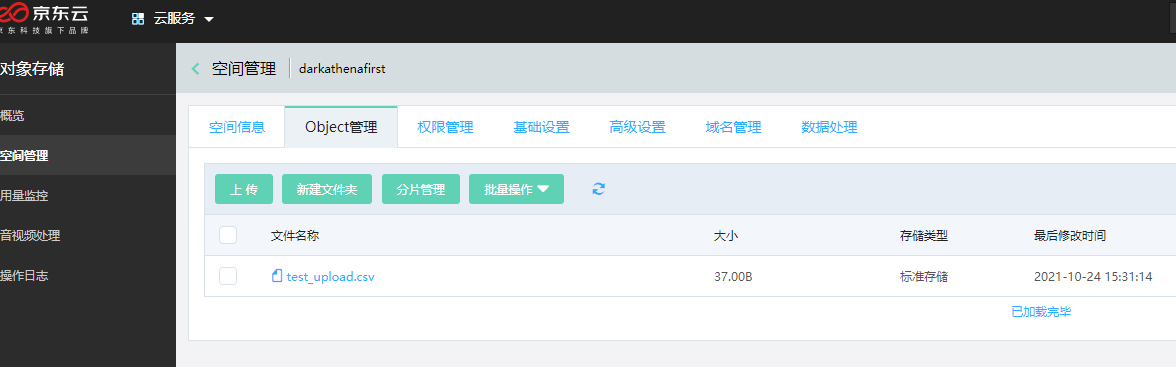
文件已经成功上传了
2.在ORACLE中创建外部表指向京东云OSS
我们假定,云上已经执行好大数据计算得出结果了,结果保存在“test_upload.csv”文件里,那么我们可以在数据库中创建一个外部表
begin
dbms_cloud.create_external_table(
table_name => 'emp_ext_jd',
credential_name => 'OBJ_STORE_CRED_JD',
file_uri_list => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
column_list => 'empno number(4),
ename varchar2(10),
job varchar2(9)',
format => '{"type" : "CSV"}'
);
end;
/
复制注:这里的format,如果要跳过第一行,可以传 {“type” : “CSV”,“skipheaders”:“1”}
查询外部表
select * from emp_ext_jd;
复制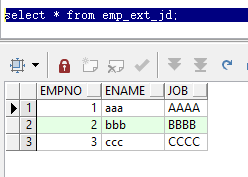
3.列出OSS中所有对象
select *
from dbms_cloud.list_objects(
credential_name => 'OBJ_STORE_CRED_JD',
location_uri => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com');
复制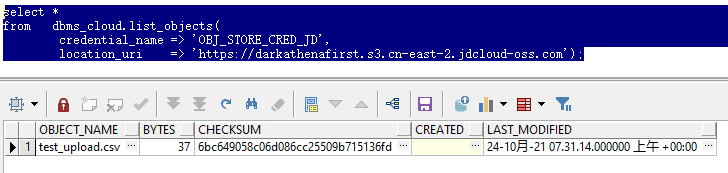
4.从OSS下载对象
begin
dbms_cloud.get_object (
credential_name => 'OBJ_STORE_CRED_JD',
object_uri => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
directory_name => 'PY_FILE',
file_name => 'test_download.csv');
end;
/
复制或者不保存文件
declare
l_file blob;
begin
l_file := dbms_cloud.get_object (
credential_name => 'OBJ_STORE_CRED_JD',
object_uri => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv');
end;
/
复制5.删除OSS对象
begin
dbms_cloud.delete_object(
credential_name => 'OBJ_STORE_CRED_JD',
object_uri => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv');
end;
/
复制6.删除本地文件
这个其实就是 UTL_FILE.FREMOVE(directory_name, l_file_name);
begin
dbms_cloud.delete_file(
directory_name => 'PY_FILE',
file_name => 'test_download.csv');
end;
/
复制7.列出本地目录下的文件
这个只能在oracle云上用,本地自治数据库无法使用
select *
from dbms_cloud.list_files(directory_name => 'PY_FILE');
复制8.根据OSS多个对象创建外部分区表
begin
dbms_cloud.create_external_part_table(
table_name => 'emp_ext_part_jd',
credential_name => 'OBJ_STORE_CRED_JD',
format => '{"type" : "CSV"}',
column_list => 'empno number(4),
ename varchar2(10),
job varchar2(9)',
partitioning_clause => q'{partition by range (empno) (
partition p1 values less than (2) location (
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload2.csv'
),
partition p2 values less than (MAXVALUE) location (
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload3.csv',
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload4.csv'
)
)}'
);
end;
/
复制9.创建一个混合本地和云的分区表
begin
dbms_cloud.create_hybrid_part_table(
table_name => 'emp_ext_hy_part_jd',
credential_name => 'OBJ_STORE_CRED_JD',
format => '{"type" : "CSV"}',
column_list => 'empno number(4),
ename varchar2(10),
job varchar2(9)',
partitioning_clause => q'{partition by range (empno) (
partition p1 values less than (2) external location (
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload2.csv'
),
partition p2 values less than (4) external location (
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload3.csv',
'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload4.csv'
),
partition p_max values less than (MAXVALUE)
)}'
);
end;
复制这个表创建后,可以执行插入,只要数据是符合非指定external location的分区,数据即可成功插入,比如
insert into emp_ext_hy_part_jd values(4,'d','D');
commit;
复制然后指定分区查询
select * from emp_ext_hy_part_jd partition (p_max);
复制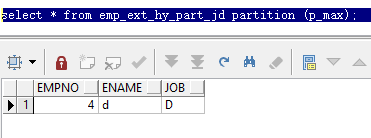
10.从oss里复制数据到本地的表
--先创建个空表
create table emp_ext_jd_copy as select * from emp_ext_jd where 1=2;
--复制数据
begin
dbms_cloud.copy_data(
table_name => 'emp_ext_jd_copy',
credential_name => 'OBJ_STORE_CRED_JD',
file_uri_list => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_upload.csv',
format => '{"type" : "CSV"}'
);
end;
--检查本地数据
select count(1) from emp_ext_jd_copy;
3
复制11.根据sql导出到OSS
begin
dbms_cloud.export_data (
credential_name => 'OBJ_STORE_CRED_JD',
file_uri_list => 'https://darkathenafirst.s3.cn-east-2.jdcloud-oss.com/test_export.csv',
query => 'select * from emp_ext_jd_copy',
format => '{"type" : "CSV"}'
);
end;
复制这个会报错,提示“Missing column list”缺失列清单,但这个参数中好像没有地方制定列清单,就算把sql改成 “select EMPNO, ENAME, JOB from emp_ext_jd_copy”一样会报错,跟踪程序,发现到执行一个动态sql时报的错
DECLARE
l_log_prev_client VARCHAR2(128);
BEGIN
l_log_prev_client := CLOUD_LOGGER.get_client;
CLOUD_LOGGER.set_client('DBMS_CLOUD');
-- Log the JSON object as a clob in the cloud_logger table
CLOUD_LOGGER.info('{"operation":"create_external_table","invoker_schema":"\"SYS\"","table_name":"\"SYS\".\"COPY$GQ2RCD59CUU5B55U79R8\"","base_table_name":null,"base_table_schema":"SYS","credential_name":"OBJ_STORE_CRED_JD","parent_operation":"export_data","client_ip":"127.0.0.1"}
');
CLOUD_LOGGER.set_client(l_log_prev_client);
EXCEPTION
WHEN OTHERS THEN
CLOUD_LOGGER.set_client(l_log_prev_client);
END;
复制但这个“CLOUD_LOGGER”对象在DBA_objects中都找不到,也就是说,CLOUD_LOGGER是个只能在动态sql里用,但完全看不到代码的那种对象,所以暂时没法找原因了。
尝试把类型换成JSON,会提示“Invalid format parameter: Bad value for type”无效的格式参数,类型的值是坏的。
12.读取操作日志
Name Type Nullable Default Comments
----------------- --------------------------- -------- ------- -------------------------------------------------------------------
ID NUMBER ID of the Load operation
TYPE VARCHAR2(128) Type of the Load operation
SID NUMBER Session ID of the session that issued the load operation
SERIAL# NUMBER Serial Number of the session that issued the load operation
START_TIME TIMESTAMP(6) WITH TIME ZONE Y Starting time of the load operation
UPDATE_TIME TIMESTAMP(6) WITH TIME ZONE Y Last update time of the load operation
STATUS VARCHAR2(9) Y Current status of the load operation
OWNER_NAME VARCHAR2(128) Y Owner name for the table specified in load operation
TABLE_NAME VARCHAR2(128) Y Table name specified in the load operation
PARTITION_NAME VARCHAR2(128) Y Partition name specified in the load operation
SUBPARTITION_NAME VARCHAR2(128) Y Subpartition name specified in the load operation
FILE_URI_LIST VARCHAR2(4000) Y List of File URIs specified in the load operation
ROWS_LOADED NUMBER Y Number of rows loaded in the table by the load operation
LOGFILE_TABLE VARCHAR2(128) Y Name of the Logfile table created for the load operation
BADFILE_TABLE VARCHAR2(128) Y Name of the Badfile table created for the load operation
TEMPEXT_TABLE VARCHAR2(128) Y Name of the temporary external table created for the load operation
复制select * from user_load_operations;
复制这个表里面会记录所有操作及其状态、相关对象,还有日志信息表名、错误信息表名,后面这两个表其实是以外部表的形式读取的操作系统上的文件,和普通外部表生成的log及bad文件是同样的东西
13.删除操作日志
传入id,删除对应的日志
begin
dbms_cloud.delete_operation(1);
end;
复制或者删除所有的日志
begin
dbms_cloud.delete_all_operations;
end;
复制处于running状态下的操作不能被删除,如果确认无任何任务在执行仍然为running状态时,则手动更新状态
update dbms_cloud_tasks t set t."STATUS#"=4 where id=6;
commit;
复制让后再调用过程删除
四、后记
整个过程基本都没什么问题,除了那个直接导出到云上的过程,我尝试模拟了oracle官方文档提供的案例,包括json(ORA-20000: Invalid format parameter: Bad value for type)和datapump(ORA-29400: 数据插件错误KUP-06006: 置入模式中不支持 CREDENTIAL 访问参数),都没成功,虽然绕个弯就能实现,但毕竟还是想让原生支持。
然后我检查了dbms_cloud包中的代码,发现它只支持这些格式
-- Values for FORMAT_TYPE JSON Key
FORMAT_TYPE_CSV CONSTANT DBMS_ID := 'CSV';
FORMAT_TYPE_CSV_WITH_EMBEDDED CONSTANT DBMS_ID := 'CSV WITH EMBEDDED';
FORMAT_TYPE_CSV_WITHOUT_EMBEDDED CONSTANT DBMS_ID := FORMAT_TYPE_CSV;
FORMAT_TYPE_AVRO CONSTANT DBMS_ID := 'AVRO';
FORMAT_TYPE_PARQUET CONSTANT DBMS_ID := 'PARQUET';
FORMAT_TYPE_DATAPUMP CONSTANT DBMS_ID := 'DATAPUMP';
复制其实就是CSV/AVRO/PARQUET/DATAPUMP,一共四种,没有json,不确定我19.12版本是不是有问题,不过我检查了21c版本的这个包,这一处的声明是一模一样的,至于包体就看不到了。而且另外这几种全部都报错,其中AVRO和PARQUET应该算成功了一半,因为已经发起http请求了。
这个dbms_cloud在使用时,会经常创建各种外部表,其实从中可以体会到oracle对“融合”或者“传输”的解决方式,即尽量使用数据库来进行管理,很多操作都不是在plsql执行的,日志和数据到操作系统中去了,直接一个外部表再结合进plsql,甚至还会读取外部表文件中的内容来做判断,这算是一种接口处理方式了?但由于oracle外部表用起来并不是那么简单,所以oracle这种“云”解决方式的合理性,还是得考量一下的。当然,不排除oracle云数据库的机制可能会有所区别。
参考文章:
https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/dbms-cloud-subprograms.html
https://oracle-base.com/articles/21c/dbms_cloud-package
- 本文链接: https://www.darkathena.top/archives/dbmscloudjdcloudoss
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处!




