




基于代价的优化器(CBO)是很智能的,但是某些情况下也会出现选择错误。
一个SQL使用多列组合过滤,目标表上存在与过滤条件列相关的多个索引,这种情况下,那优化器在选择执行计划时就会面临挑战,有可能会因为估算问题,而选错执行计划。
CBO估算出现估算错误问题通常会因为谓词越界引起,所谓谓词越界就是指目标列指定的where 查询条件的值不在统计信息收集的最大值与最小值之间,如果启用10053跟踪事件,trace文件中会给出selectvity of out-of-range/non-existent value pred提示,但是通常频率直方图、等高直方图对于谓词越界,都有一定的容忍度(在high_value ~(2high_value-low_value)范围之间是逐渐衰减的),不至于超出最值范围,选择性就降为0。
除了谓词越界,也可能与CBO的估算公式缺陷有关。当存在两个列的过滤条件时,那选择率为每列上的选择率的乘积,当一个小于1的数乘以一个小于1的数,这个乘积会以数量级的速度递减。所以使用多列组合过滤通常选择性会估算的很低。
下面举例说明多列过滤下CBO因计算公式缺陷出现选择性错误的问题。
有这样一个t1表
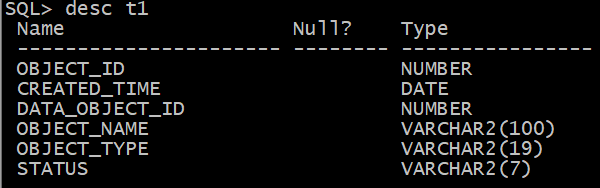
表中列统计信息如下:
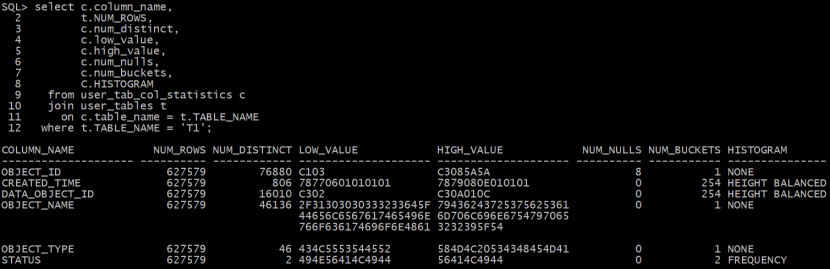
表上索引信息如下:

我们以绑定变量形式执行下面的sql语句
var objectid number;
var dataobjectid number;
var pstart varchar2(20);
var pend varchar2(20);
exec :objectid:=50;
exec :dataobjectid:=90007;
exec :pstart:='2021-08-12';
exec :pend:='2021-08-13';
select *
from t1
where object_id = :objectid
and data_object_id = :dataobjectid
and created_time between to_date(:pstart, 'yyyy-mm-dd') and
to_date(:pend, 'yyyy-mm-dd');
这个语句的过滤条件列涉及两个索引,那么CBO会选择哪一个索引呢?
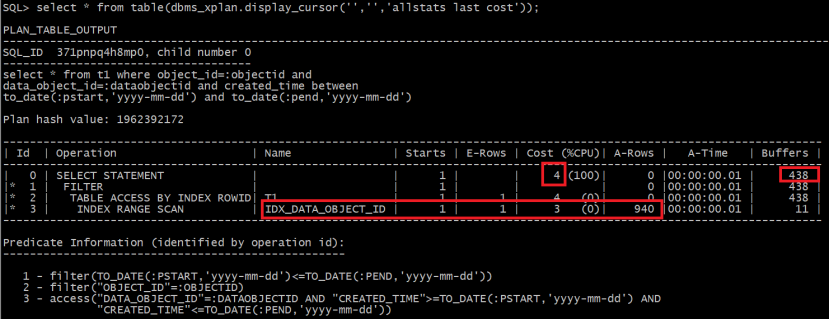
下图为cbo选择的执行计划
使用hint提示,强制cbo选择索引idx_object_id,执行计划如下图所示:
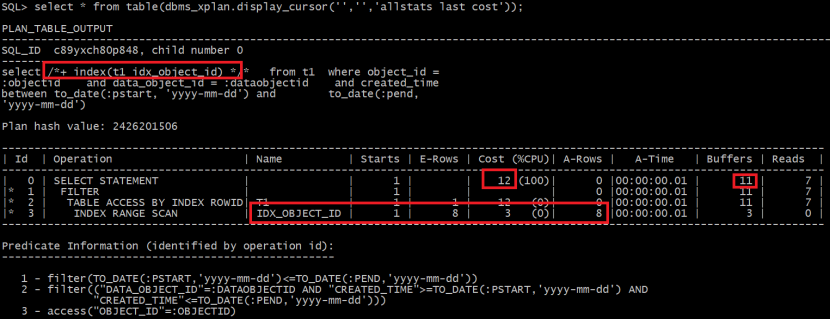
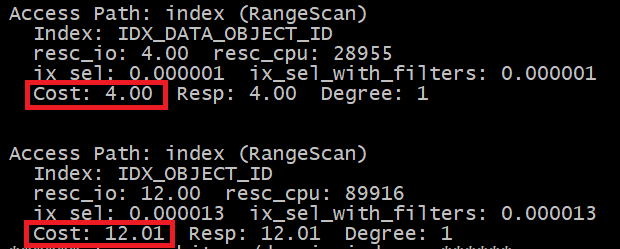
发现使用索引idx_object_id资源消耗buffers更低,但是cbo估算的成本cost却比使用索引idx_data_object_id要高。优化器是基于成本cost来选择执行计划的,索引cbo默认选择走索引idx_data_objejct_id的执行计划。
下面我们看一下10053跟踪cbo选择执行计划的过程,来推算一下CBO是如何估算成本的。
10053数据

索引范围扫描的成本的计算公式:
cost=blevel + ceil(leaf_blocks * 列的选择性) + ceil(clustoring_factor * 列的选择性)
blevel表示索引的二元高度,等于索引高度-1。leaf_blocks 为索引叶子块个数,clustoring_factor为索引的聚簇因子,这几个值在10053中都能看到,当然也可以通过视图user_indexes查到。

OBJECT_ID列上无直方图,其选择性为(1/列上唯一值个数)乘以空值矫正比例
Object_id列的选择性=(1/num_distinct)*A4NULLS=(1/num_distinct)*((num_rows-num_nulls)/num_rows)
=(1/76880)*((627579 - 8)/627975)=0.000013
Data_object_id列上有等高直方图,非popular值得选择性为密度density乘以空值矫正比例。
Data_object_id列的选择性
=density*A4nulls=0.000062*1=0.000062。
Created_time列的选择性
下图为created_time列的直方图统计信息,绑定变量值开始日期2021-8-12,结束日期为2021-8-13,属于范围过滤,大概占3个桶。
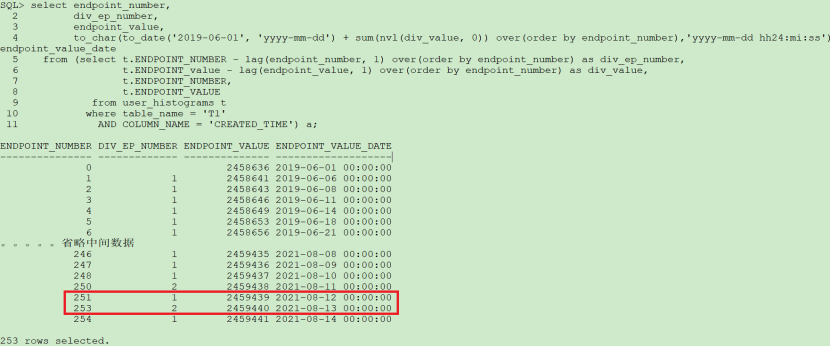
Created_time列的选择性=3/254
使用索引object_id的成本:
Cost(idx_object_id) = blevel + ceil(leaf_blocks * 列的选择性) + ceil(clustoring_factor * 列的选择性)
=2+ceil(4246*0.000013)+ceil(627570*0.000013) = 12
使用索引dataobjectid的成本:
多列的选择性=每一列选择性的乘积
Cost(idx_data_object_id) = 2 + ceil(4286*0.000062*3/254) +ceil(618008*0.000062*3/254) = 4
可以看出根据成本计算公式的计算结果,使用IDX_DATA_OBJECT_ID索引的代价更低,但事实并非如此。
解决办法:
出现这种情况,可以使用hint提示,也可以使用sql profile或SPM来稳定执行计划,如果两个列有一定的依赖关系存在,为了规避使用公式计算的选择性的缺陷问题,也可以收集多列统计信息。



