




ElasticSearch在面试架构等岗位中出现的越来越多,本文精选10道ElasticSearch面试题,助你无惧ElasticSearch面试,更多es面试题请关注面试哥公众号。
1. 什么是ElasticSearch?
Elasticsearch是一个基于Lucene的搜索引擎。它提供了具有HTTP Web界面和无架构JSON文档的分布式,多租户能力的全文搜索引擎。Elasticsearch是用Java开发的,根据Apache许可条款作为开源发布。
2. 为什么要使用Elasticsearch?
因为在我们要查询的数据越来越多,所以采用以往的模糊查询,模糊查询前置配置,会放弃索引,导致商品查询是全表扫面,在百万级别的数据库中,效率非常低下,而我们使用ES做一个全文索引,我们将经常查询的商品的某些字段,比如说商品名,描述、价格还有id这些字段我们放入我们索引库里,可以提高查询速度。
3. Elasticsearch是如何实现master选举的?
面试官:想了解ES集群的底层原理,不再只关注业务层面了。
解答:
前置前提:
1)只有候选主节点(master:true)的节点才能成为主节点。
2)最小主节点数(min_master_nodes)的目的是防止脑裂。
这个我看了各种网上分析的版本和源码分析的书籍,云里雾里。
核对了一下代码,核心入口为findMaster,选择主节点成功返回对应Master,否则返回null。选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml设置的值discovery.zen.minimum_master_nodes;
第二步:比较:先判定是否具备master资格,具备候选主节点资格的优先返回;若两节点都为候选主节点,则id小的值会主节点。注意这里的id为string类型。
题外话:获取节点id的方法。
1、GET _cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2、ip port heapPercent heapMax id name
3、127.0.0.1 9300 39 1.9gb Hk9w Hk9wFwU
补充:
1、Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
2、对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
3、如果对某个节点的投票数达到一定的值(可以成为 master 节点数 n/2+1)并且该节点自己也选举自己,那这个节点就是 master。否则重新选举一直到满足上述条件。
4、master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
4. Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
1、当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
2、当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data节点,避免脑裂问题。
5. 详细描述一下 Elasticsearch 索引文档的过程。
协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
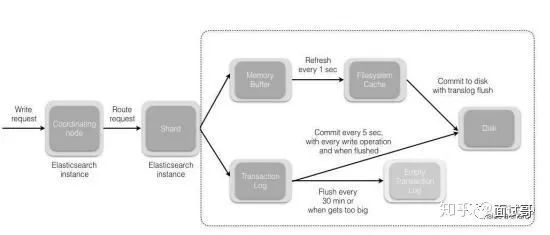
1、当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 MemoryBuffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 MomeryBuffer 到 Filesystem Cache 的过程就叫做 refresh;
2、当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
3、在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
4、flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
补充:关于 Lucene 的 Segement:
1、Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
2、段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
3、对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
4、为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
6. 详细描述一下 Elasticsearch 更新和删除文档的过程。
1、删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
2、磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。
3、在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
7. 详细描述一下 Elasticsearch 搜索的过程?
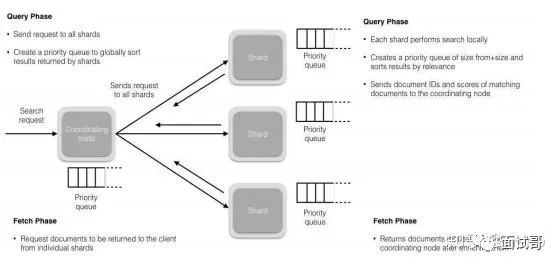
1、搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
2、在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。
PS:在搜索的时候是会查询 Filesystem Cache 的,但是有部分数据还在 MemoryBuffer,所以搜索是近实时的。
3、每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
4、接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
5、补充:Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
8. 详细描述一下Elasticsearch搜索的过程?
面试官:想了解ES搜索的底层原理,不再只关注业务层面了。
解答:
搜索拆解为“query then fetch” 两个阶段。
query阶段的目的:定位到位置,但不取。
步骤拆解如下:
1)假设一个索引数据有5主+1副本 共10分片,一次请求会命中(主或者副本分片中)的一个。
2)每个分片在本地进行查询,结果返回到本地有序的优先队列中。
3)第2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
fetch阶段的目的:取数据。
路由节点获取所有文档,返回给客户端。
9. 详细描述一下Elasticsearch索引文档的过程?
面试官:想了解ES的底层原理,不再只关注业务层面了。
解答:
这里的索引文档应该理解为文档写入ES,创建索引的过程。
文档写入包含:单文档写入和批量bulk写入,这里只解释一下:单文档写入流程。
记住官方文档中的这个图。
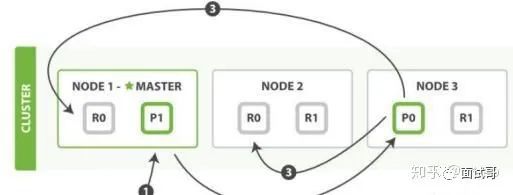
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点1接受到请求后,使用文档_id来确定文档属于分片0。请求会被转到另外的节点,假定节点3。因此分片0的主分片分配到节点3上。
第三步:节点3在主分片上执行写操作,如果成功,则将请求并行转发到节点1和节点2的副本分片上,等待结果返回。所有的副本分片都报告成功,节点3将向协调节点(节点1)报告成功,节点1向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档id计算目标的分片id的过程。
shard = hash(_routing) % (num_of_primary_shards)
10. Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。
其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);
小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。

关注面试哥公众号,获取更多面试题答案与学习资料。
