




在写这篇文章的时候,突然想到很多生活中关于"结构组织"的场景,比如现在我要到某个学校找一名同学,那么我需要知道他在几号楼->几层->几班->几号座位才能快速明确的找到他;我要去电影院看电影,在网上购买了电影票,到达电影院后,通过电影票上面的几号厅->几号座次,我可以明确的找到看电影的位置;我要去小区拜访朋友,同样需要知道朋友住几号楼->几单元->几层->门牌号,然后才能快速的到朋友家拜访;我要去远方旅行,准备做高铁,那么我买的票上也同样告诉我列车的班次->几号车厢->几号座位,等等......。那么对于某个同学的座位、电影院的座次、小区的住户、火车的座位,这些其实都属于基本的数据单元,只不过概念不同而已,我们这里为了便于理解,暂且不从学术严谨的角度而从生活的角度,将这些事物划分到一个抽象层级,这样我们会从中得到一个共性的组织结构:

图1
上图是对高铁的座位结构组织的抽象,试想一下对于某个同学座位、小区住户、电影院座位是不是也可以抽象出上面的这种结构呢?答案是可以的。生活中这样的案例不胜枚举,而不管是这些枚举中的哪个场景,其组织的目的都是为了更加方便、高效的进行管理。
计算机是帮助人们解决现实生活中的问题的,也就是说它并不是脱离生活的存在,那么上面的抽象思想在计算机中也同样是完全适用的,只不过在计算机中我们需要将这种抽象思维应用到数据的组织和管理上,从而让计算机更好的协助我们解决现实中的问题。所谓的更好其实隐含了一个高效,当然准确是必须的,下面我们以更高效的查找数据为目的来展开分析。
这里就以MySQL的InnoDB引擎索引组织为切入点,首先我们有这样一张表:
create table e_user(id int primary key auto_increment,username varchar(64) not null comment '用户名',password varchar(32) not null comment '密码',mobile varchar(11) not null comment '手机号',age tinyint comment '年龄')engine=InnoDB comment='用户表' charset=utf8mb4;
表的数据在MySQL中是如何组织然后存储的呢?拿学校的教室来讲,不同学校的教室、不同功能的教室的座位数量是不一样的,这里我们把座位数量想象成数据单元便于我们更好的理解MySQL的数据组织。计算机是以磁盘、内存作为数据的存储媒介(就像一个大学校,而教室和座位如何安排就要因地制宜了),MySQL里有个抽象的概念叫做数据页(这个东西可比作为教室),每个数据页的大小是16KB,每向表中存储一次数据都会找到指定的数据页存储,如果一个数据页存满了则申请一个新的数据页,依次类推,会有很多的数据页,向下面这样:
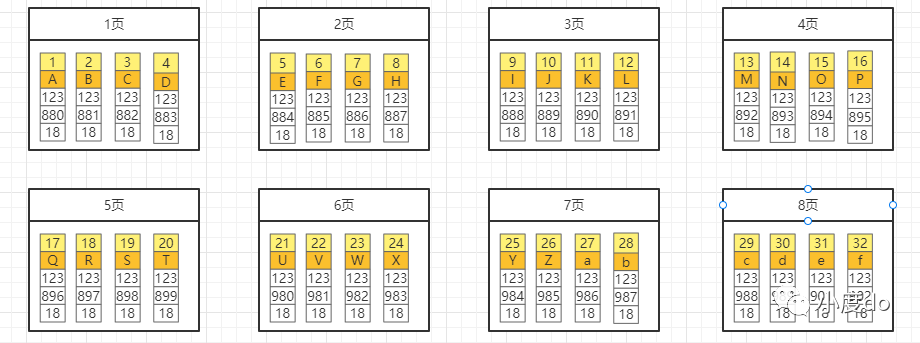
图2
那么这些数据页如何组织起来可以更加快速的查找到某条数据呢?假设我们现在把上面的这些数据页比作字典中的每一页,而你又是如何在字典中快速查找到一个字的呢?答案是通过索引目录,字典设计索引目录的目的就是为了方便查找,字典会拿出字的偏旁部首,然后根据笔画数组成一个索引目录,我们找一个字的时候,会根据其偏旁部首的笔画,先到索引目录找到这个偏旁,而这个偏旁会指向一个页码......,接下来你会很快找到目标的字。同样我们也可以借鉴字典的这种设计思想将我们的数据页重新组织一下,就变成下边这样:

图3
我们暂且把上图的第一层叫做索引页,第二层叫做数据页,图中所表示的是索引页存储每个数据页的最小主键值,主键值下对应其所在的数据页编号。就现在的图1和图2我们分别计算一下从中查找一个数据的效率对比。比如我要查找ID为15的那条数据:
图2从左上数据页开始查找(每个数据页之间是双向链表,数据页内部的数据条是单向链表),假如就一次从左上到右下遍历数据页,需要遍历到第四个数据页才能找到,一共遍历了15条数据。
图3从第一层(索引页层)开始查找,还是查找主键ID为15的数据,由于15处于13和17之间,所以需要先遍历数据页4,很巧在数据页4中遍历3条数据后找到了目标数据。其实不难发现,即使想要查找ID为17的数据,也只需要遍历数据页中的5条数据。
显然图3中的数据组织形式可以更加快速的查找数据,这种查找算法就是二分查找,二分查找的最坏情况时间复杂度是O(logn),这是非常高效的,如果我们再增加一层索引是不是还会提高查找效率呢?答案是肯定的,当然这种查找效率的提升也是以空间换时间的代价换来的。
MySQL实际数据页中的存储还有很多细节,比如数据页格式的设计、数据行格式的设计,如果理解了上面的这种数据结构组织形式,对于数据页的细节设计也是很容易理解的。
