




都说人生苦短,我用python。为了找点乐趣,不如写个爬虫?
那爬什么呢?
宇宙条是爬虫界行家,它的很多信息都是从其它网站爬来的,那就拿它练练手吧。
网上类似的文章其实不少,但是大多是很久之前的,在这期间头条已经做了改版,因此还必须自己动手。
具体原理不多说了,直接简单介绍下步骤:
1.首先,打开头条首页,搜索关键词「美景」,可以得到搜索结果页面链接为https://www.toutiao.com/search/?keyword=美景,搜索结果如下:
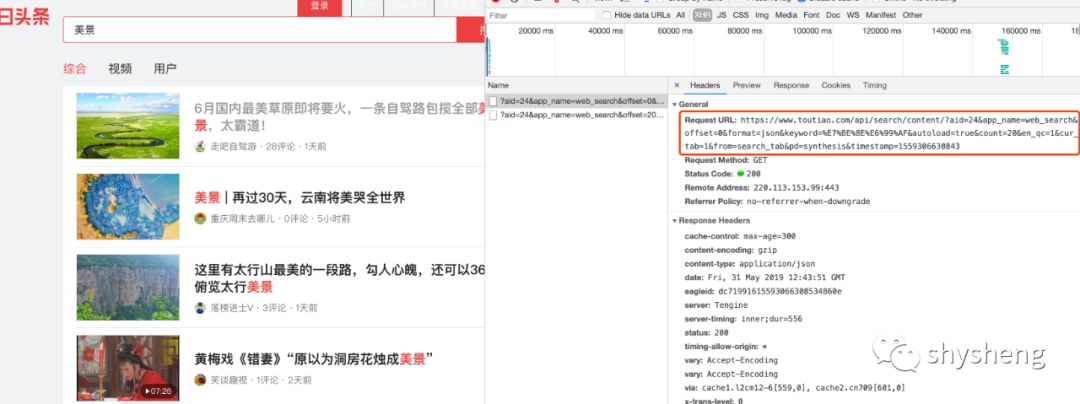
2.同时注意到这是一个Ajax请求,因此我们需要拿到其真实的请求url,就是图中红框标出来的部分。
3.第一次发起搜索请求时,头条有一个滑块验证,这里我们就不模拟这个过程了,手动验证,拿到cookie就好,同时将自己的浏览器信息,请求参数都复制出来:
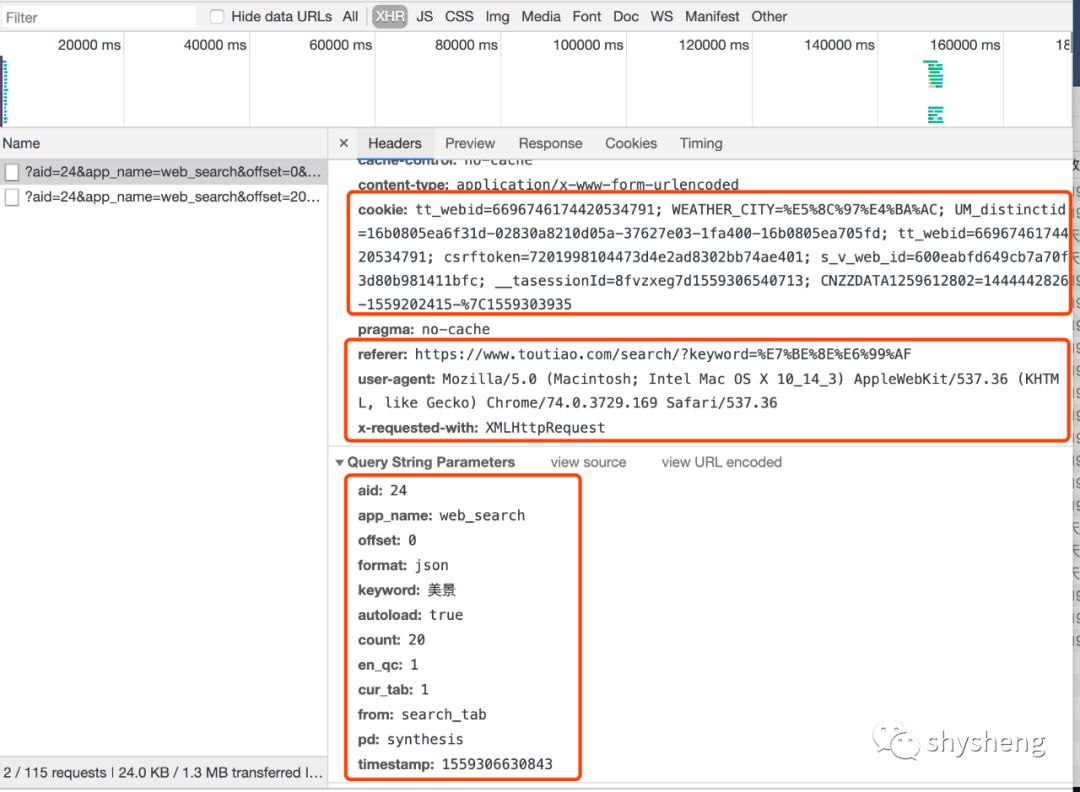
连续向后翻页,发现变化的参数只有offset一个,也就是偏移量。
4.观察请求结果,最关键的是article_url这个字段,根据这个链接重定向,就可以跳转到列表中每篇文章的详情页。
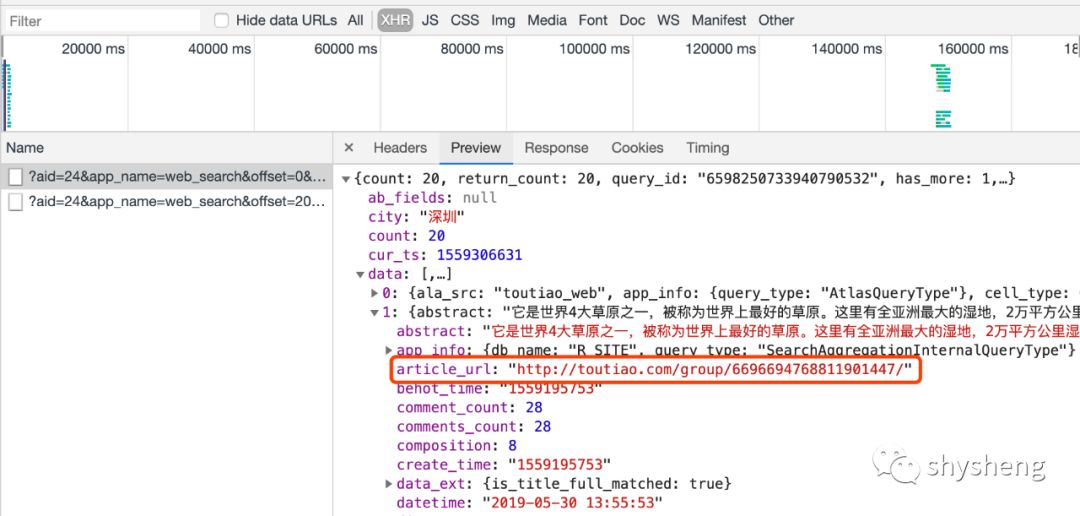
5.进入详情页,查看网页源码,可以发现图片链接都是以下图标出来的形式记录的,这就好办了,简单正则匹配一下就好
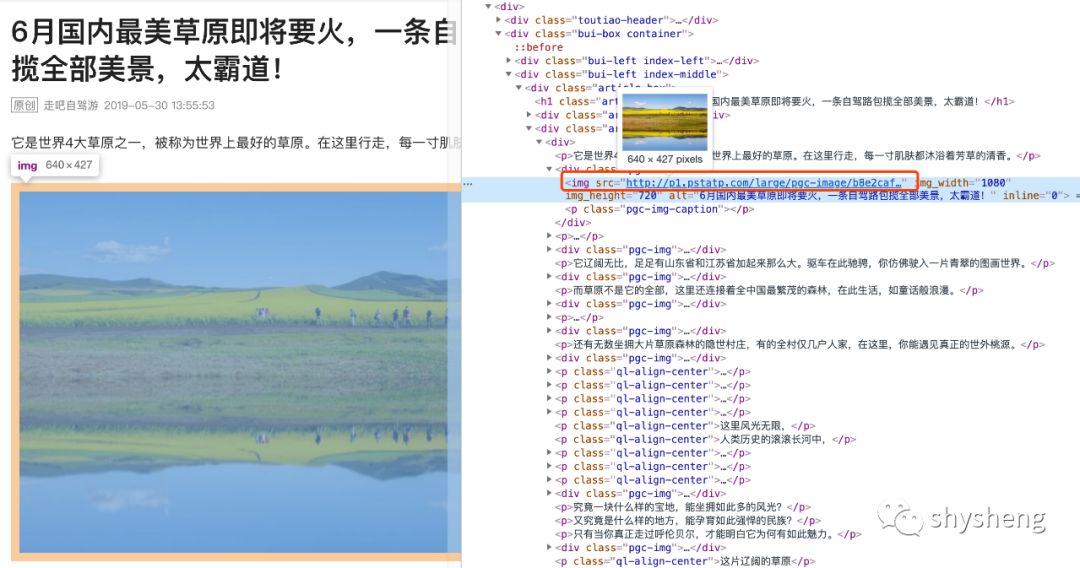
6.拿到图片链接,保存到本地,大功告成。

应该说头条相对来说做得比较简单一些,毕竟是新闻类网站,总共差不多100行代码就搞定了,不像淘宝,要爬它的数据就要困难很多。
当然了,除了爬美景,其它照片你想爬啥就怕啥,修改下搜索关键字就好了。第一次写爬虫,还有很多可以优化的地方。简单贴下代码,需要的自取,鬼晓得头条啥时候又改版了,同时欢迎大家review😝。
最后,祝各位大小宝宝节日快乐~~~~
# -*- coding: utf-8 -*-import osimport reimport threadingimport timefrom hashlib import md5from urllib import urlencodeimport requests# 这里设置你想查询的关键字keyword = '美景'# 这里替换成你自己的浏览器信息user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'# 头条图片搜索需要滑动验证,因此简单处理,先手动验证,然后设置cookiecookie = 'tt_webid=6696746174420534791; WEATHER_CITY=%E5%8C%97%E4%BA%AC; UM_distinctid=16b0805ea6f31d-02830a8210d05a-37627e03-1fa400-16b0805ea705fd; tt_webid=6696746174420534791; __tasessionId=znvodagrm1559207733945; csrftoken=7201998104473d4e2ad8302bb74ae401; s_v_web_id=600eabfd649cb7a70f3d80b981411bfc; CNZZDATA1259612802=1444442826-1559202415-%7C1559207815'headers = {'Host': 'www.toutiao.com','Referer': 'https://www.toutiao.com/search/?keyword=' + keyword,'User-Agent': user_agent,'X-Requested-With': 'XMLHttpRequest','Cookie': cookie}start_offset = 0end_offset = 20step = 20# 根据偏移量获取每页文章列表def get_page_by_offset(offset):params = {'aid': '24','app_name': 'web_search','offset': offset,'format': 'json','keyword': keyword,'autoload': 'true','count': '20','en_qc': '1','cur_tab': '1','from': 'search_tab','pd': 'synthesis',}url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params)try:resp = requests.get(url, headers=headers)if resp.status_code == 200:return resp.json()except requests.ConnectionError:return None# 获取每篇文章的重定向链接def get_article_url(article):if article.get('data'):for item in article.get('data'):article_url = item.get('article_url')title = item.get('title')yield {'article_url': article_url,'title': title}# 将图片保存到文件def save2file(title, url):if not os.path.exists(title):os.mkdir(title)resp = requests.get(url)file_name = './' + title + '/' + md5(resp.content).hexdigest() + '.jpg'if not os.path.exists(file_name):with open(file_name, 'wb') as f:f.write(resp.content)else:print('Already Downloaded', file_name)# 获取每篇文章的图片列表def get_image_by_article(article):article_url = article.get('article_url')title = article.get('title')print titleprint article_urlif article_url:try:# 这里需要使用session的方式,否则会因为重定向次数太多而报错session = requests.Session()session.headers['User-Agent'] = headers['User-Agent']resp = session.get(article_url)if resp.status_code == 200:# soup = BeautifulSoup(resp.text, 'lxml')# result = soup.find_all(name='script')[6]regex = '.*?img src="(.*?)".*?'items = re.findall(regex, resp.text, re.S)if items:for item in items:print itemsave2file(title, item)except requests.ConnectionError:print 'Get image fail.'if __name__ == '__main__':for offset in range(start_offset, end_offset, step):article_list = get_page_by_offset(offset)for article in get_article_url(article_list):# 每篇文章单独起一个线程进行抓取t = threading.Thread(target=get_image_by_article(article))t.start()t.join()# get_image_by_article(article)end_time = time.time()print('=====Done=====')
