




一、前言
相信大家对暗网这个概念并不陌生,众所周知,暗网藏着一个暗黑版的交易市场,违法工具、色情交易、毒品交易、枪械信息比比皆是,俨然一个网络犯罪分子聚集的“虎狼之穴”。我们使用Tor浏览器等可以轻松访问暗网中的浅层网,主要是黄赌毒和数据情报信息,如丝绸之路等。
对于企业而言,往往不免被黑客攻击而被获取大量的数据,而这些数据一般会优先在暗网售卖,如近年来的12306、各大互联网公司等的数据泄露事件。为了及时响应突发的数据泄露事件,企业需要一款实时监控暗网数据泄露的威胁情报平台,用来监控敏感数据泄露、薅羊毛、业务安全风险等事件。
二、代理服务器搭建
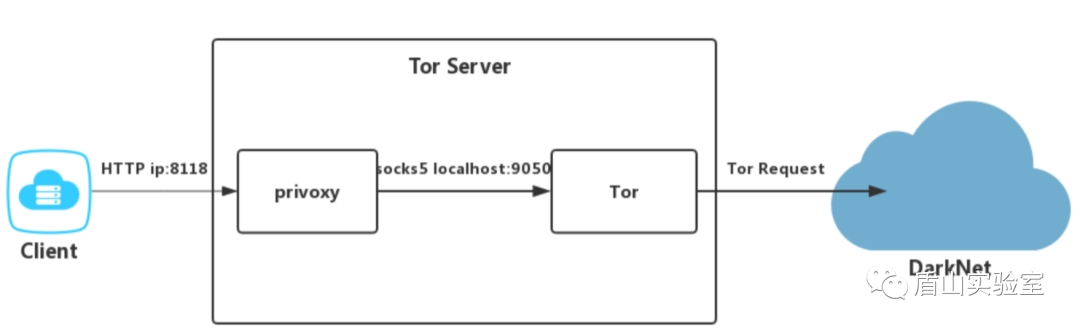
由于国内网络环境的原因,为了顺利访问暗网,我们需要一台海外服务器,系统版本是ubuntu 18.04(当然其他系统也可以,只是本文会把这个版本的系统作为例子),同时需要在这台服务器上安装Tor与Privoxy用作访问代理服务器。
本文的系统版本:
root@536ef99cab94:/# cat etc/issue.net
Ubuntu 18.04.2 LTS复制
2.1 整体架构
3.1 暗网网站的特点
暗网网站不同于表层网网站,没有太多花里胡哨的动态js与强大的反爬策略,因此对暗网网站爬虫也相对简单。在总结了几个常见的暗网网站后,发现暗网网站的反爬策略一般是如下几种情况:
1.Referer;
2.针对Cookie的请求频率限制;
3.User-Agent;
4.验证码;
5.对网站代码进行更新,修改html标签名字或位置。
3.2 暗网网站的反反爬虫
针对3.1的反爬虫策略我们可以设法绕过,由于本文的主旨并不在探究反爬虫策略,故简单地说下绕过方法:
1.指定请求头的referer为访问暗网网站的域名;
2.建立多账号Cookie池,同时使用Redis对url去重实现增量爬取减少请求量;
3.指定User-Agent为FireFox浏览器:{‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; rv:60.0) Gecko/20100101 Firefox/60.0’};
4.暗网网站的验证码一般比较简单,可以简单使用ocr技术识别,如tesseract;
5.需要及时更新爬虫代码,有针对地修改反反爬虫代码。
3.3 暗网监控的爬虫架构
Scrapy是用Python实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过Scrapy框架实现一个爬虫,抓取指定网站的内容。
本文在Scrapy基础上结合3.2小节的反爬虫绕过方法实现了一个实时监控程序,其架构如下:
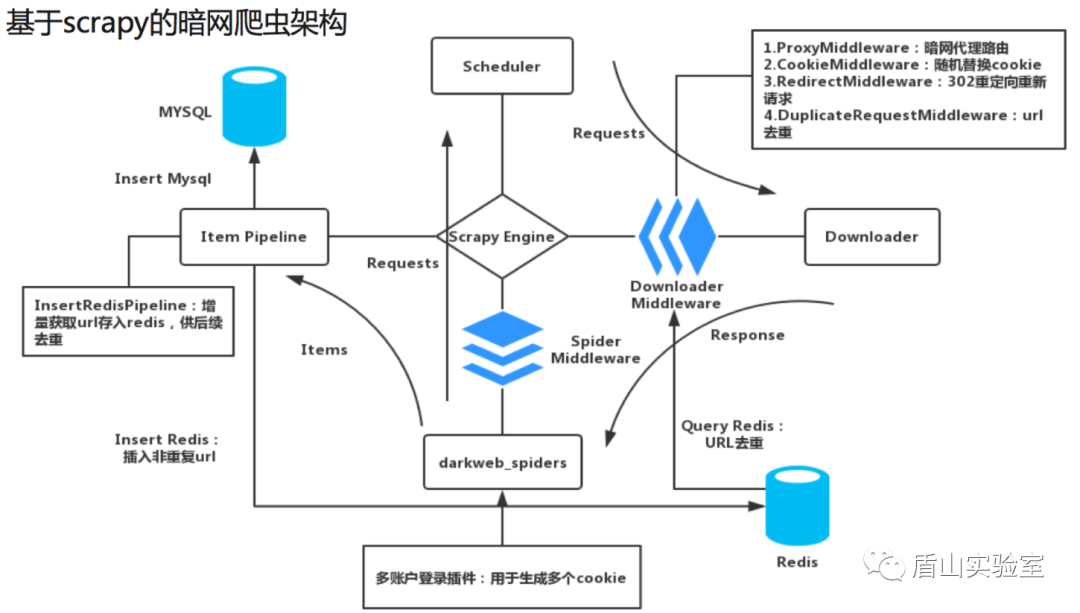
3.4 监控程序的具体实现
本文的监控程序是同时监控几个常见的暗网网站,由于篇幅有限,故只拿某暗网网站作为例子。
