




近来,换脸应用层出不穷,照片换脸已经是小儿科了。甚至视频换脸都已经做到人类很难分辨真假的水平。很多视频利用名人的形象,操控他们的讲话内容,或者给他们换脸,诋毁他人形象,这使得人们对数字信息逐渐失去信任。也使得AI的发展受到了道德层面的质疑。为了让AI应用真正造福人类,提升数字信息可信度,很多公司、AI技术团队都为人脸打假问题做出了很多贡献。其中,来自慕尼黑工业大学的研究团队提出了一种基于图像信息的假脸检测模型,并提供了一个FaceForensics++ 数据集——专门针对换脸问题设计的数据集,旨在用AI技术来反制AI造假技术。
为了反制AI造假技术,我们就需要先了解其技术,这有点像关于计算机病毒的攻防战,知己知彼百战不殆。
目前关于换脸应用的造假方式主要分为两种:
面部表情操控(facial expression manipulation )
变化比较小,又叫做面部重建(facial reenactment)。给你换个表情,或者融合一些别人的面部特征给你。
代表模型:Face2Face
面部身份操控(facial identity manipulation )
面部变化比较大,一般是直接把另一个人的脸换到你身上。
代表模型:DeepFakes

本文提供了FaceForensics++这个数据集外,还提供了一个baseline的方法来对这些造假视频进行检测,据作者(指原文作者,后同)汇报,该方法比人眼标注的准确率高很多。这类任务真可以说是完美的机器学习项目,因为完全不受人类标注影响,没有标注错误,数据的标签的准确率是100%!
知己知彼百战不殆,本文提供的数据集都是利用经典计算机图形学方法Face2Face , FaceSwap, 以及深度学习方法DeepFakes, NeuralTextures 来生成的。
Face2Face是一个实时面部重建系统,可以根据原视频进行三维模型重建和图形渲染来生成换脸后的视频。
Tips:DeepFake是一个基于深度学习进行image to image变换的模型,需要做pair-wise训练,训练非常耗时。
FaceForensics++数据集包含:从1000个视频中截取的180万张图片。
对于视频的打假工作,文章总结如下:
For videos, the main body of work focuses on detecting manipulations that can be created with relatively low effort, such as dropped or duplicated frames, varying interpolation types, copy-move manipulations, or chroma-key compositions.
因此,掉帧或者重复帧,不断变化的插值类型,存在复制移动操作或者绿幕的组件都可以作为造假视频的证据。
至于专门针对面部的打假方法,文章有如下总结:
For face manipulation detec- tion, some approaches exploit specific artifacts arising from the synthesis process, such as eye blinking, or color, texture and shape cues. Other works are more general and propose a deep network trained to capture the subtle inconsistencies arising from low-level and/or high level features.
例如眨眼检测,肤色肤质以及形状等线索也有帮助。还有一些更通用的方法通过深度学习网络来捕捉到一些细微的不连续性。
以上所提的方法尽管表现都还不错,但是都或多或少有一些还没解决的缺点或者鲁棒性不足等问题。例如:
For example, operations like compression and resizing are known for laundering manipula- tion traces from the data.
作者提到,他们注意到了跟原视频比起来,造假视频通常都会进行压缩或者尺寸缩放,这可能会导致数据泄露,使得模型学到错误的信息,FaceForensics++这个数据集考虑到这点,将原视频和造假视频的压缩方法和尺寸包括清晰度都设置为了相同的参数。
在FaceForensics++之前,其实还有个数据库叫做FaceForensics,本文提供的数据集是对FaceForensics的一个扩展,因此叫做FaceForensics++。
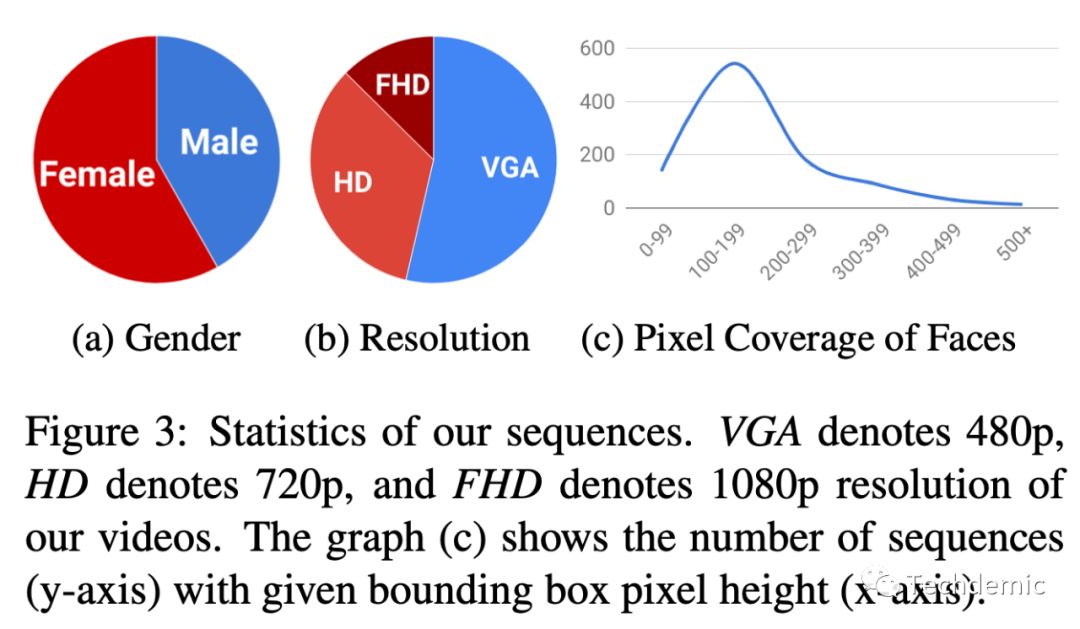
上图就是对FaceForensics++数据集的一个基本统计信息,从性别比例,视频清晰度以及面部大小(占多少像素),横轴为像素值,纵轴为出现次数。
关于原视频信息:
We selected 1,000 video sequences containing 509, 914 images which we use as our pristine data.
在YouTube等视频网站上下载的1000个视频片段,包括了509914帧图片。
关于造假视频信息:
We chose two computer graphics-based approaches (Face2Face and FaceSwap) and two learning- based approaches (DeepFakes and NeuralTextures).
使用两种基于计算机图形学的方法Face2Face 和 FaceSwap以及两种基于深度学习的方法DeepFakes 和 NeuralTextures来生成。
生成的图片再压缩成视频:
To create a realistic set- ting for manipulated videos, we generate output videos with different quality levels.
FaceForensics++数据集用不同的压缩比(23和40)将图片压缩成质量不同的视频。后面的研究中也指出,模型对于不同清晰度的视频的检测准确率也不同,清晰度更高的视频检测准确率也更高。
作者把视频打假问题简化成一个每帧二分类问题:
We cast the forgery detection as a per-frame binary clas- sification problem of the manipulated videos.
以视频为样本,将在训练集,验证集,测试集分为720,140,140(共1000个视频)。
为了证明模型的有效性,作者先进行了人工标注,随后证明model的准确率高于人工标注,下图就是人工标注的结果:
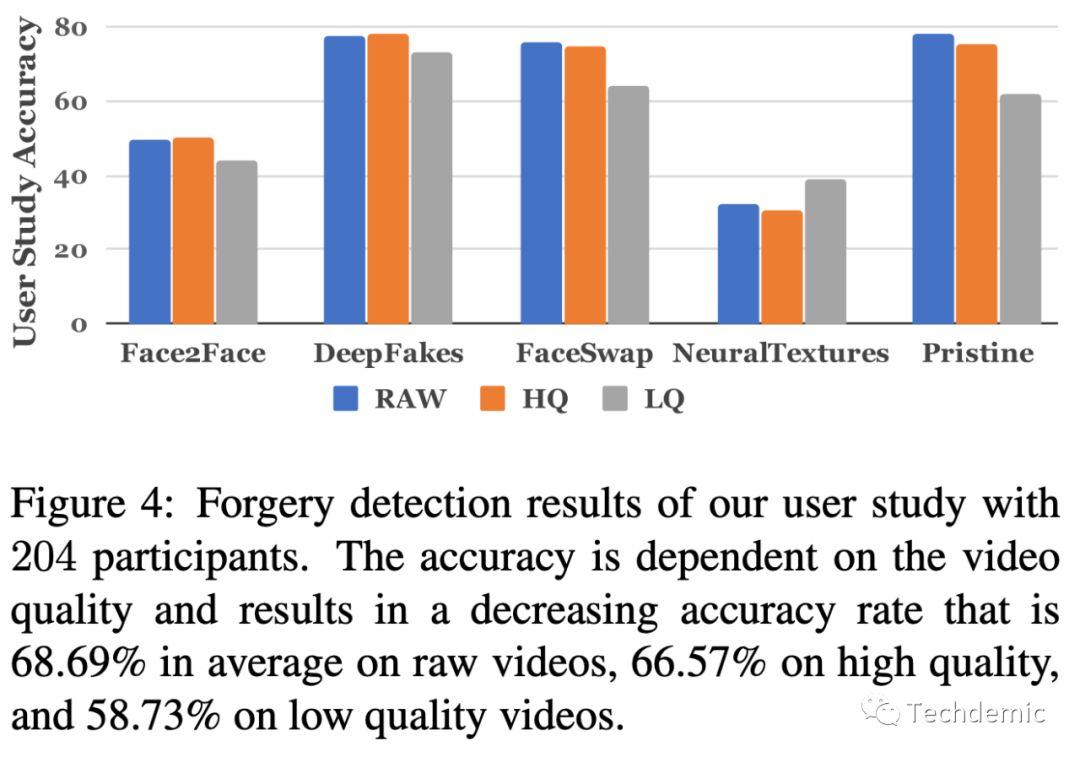
但是这里作者用了一个逻辑谬误,机器学习的模型是以视频为样本,但是人工标注却以图片为样本。一个是动态判断,一个是静态判断,无形中提高了人工标注的难度。另外要注意的就是人类在静态图片的情况下,确实很难识别出NeuralTextures和Face2Face这种表情造假。其中NeuralTextures是基于GAN的生成模型,从数据上来看,它也是人类最难判断的模型,这也说明了GAN的优越性,难怪这段时间异常火爆!
Face Tracking
接下来就是本文提出的baseline模型了,首先是一个face tracking面部跟踪模型。
To this end, we use the state- of-the-art face tracking method by Thies et al. [59] to track the face in the video and to extract the face region of the image.
如原文所说,他们采用了Thies et al. 的SOTA模型作为面部跟踪模型。之后将bounding box放大1.3倍作为面部patch。面部跟踪的patch相比于整个图片作为输入,提高了准确率。
Classifier
有了面部patch作为输入,再跟一个CNN分类网络,来对这个patch进行二分类。
We evaluated various variants of our approach by using different state-of-the-art classifica- tion methods.
In addition, we show that the classification based on XceptionNet outperforms all other variants in detecting fakes.
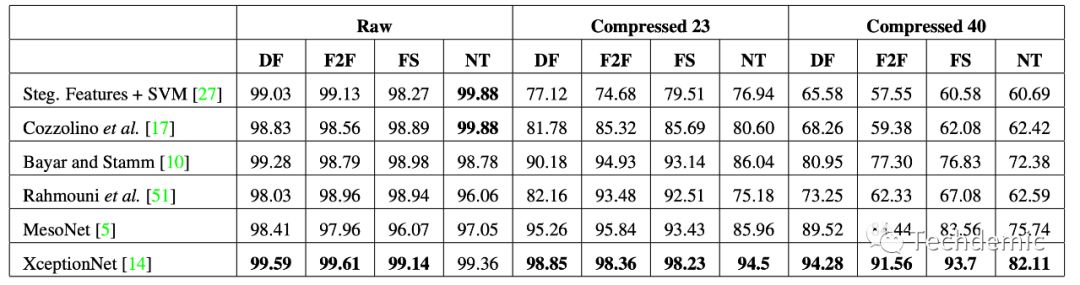
作者对比了不同的SOTA分类器,最后得出结论,XceptionNet的准确率最高,这里注意,结果的统计根据清晰度分为了3组对照,说明清晰度影响确实很大,但是清晰度是可以作为视频的先验知识的,因此可行的方案是针对不同清晰度视频,训练不同的模型。
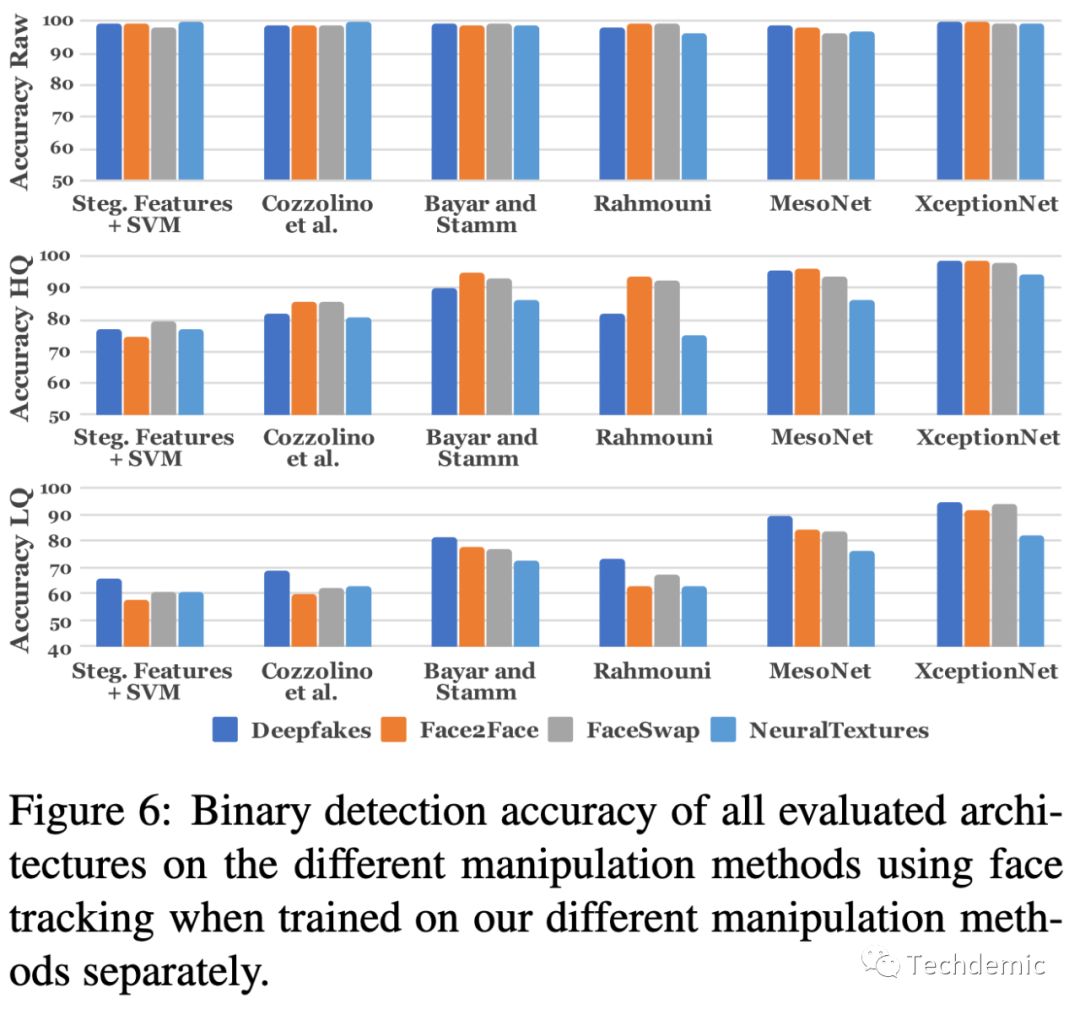
关于XceptionNet训练的细节如下:
XceptionNet is a traditional CNN trained on Im- ageNet based on separable convolutions with residual con- nections. We transfer it to our task by replacing the final fully connected layer with two outputs. The other layers are initialized with the ImageNet weights. To set up the newly inserted fully connected layer, we fix all weights up to the final layers and pre-train the network for 3 epochs. After this step, we train the network for 15 more epochs and choose the best performing model based on validation accuracy.
简单总结就是 把输出层改为2分类,ImageNet预训练权重作为初始权重。固定输出层以前的权重,只保留输出层权重,训练3个epoch,然后对整个网络训练15个epoch,最后选择表现最好的模型。
最后,作者又约定俗成地做了一些消融学习(Ablation Study)对比实验。其中也证实了我之前的猜想,他们根据视频的清晰度分别训练了3个模型,并证明这样得到的总体准确率更高。另外还得到一个结论,对于低清视频,训练数据越多,得到的提升非常明显,高清视频则对训练数据数量要求没有那么多。
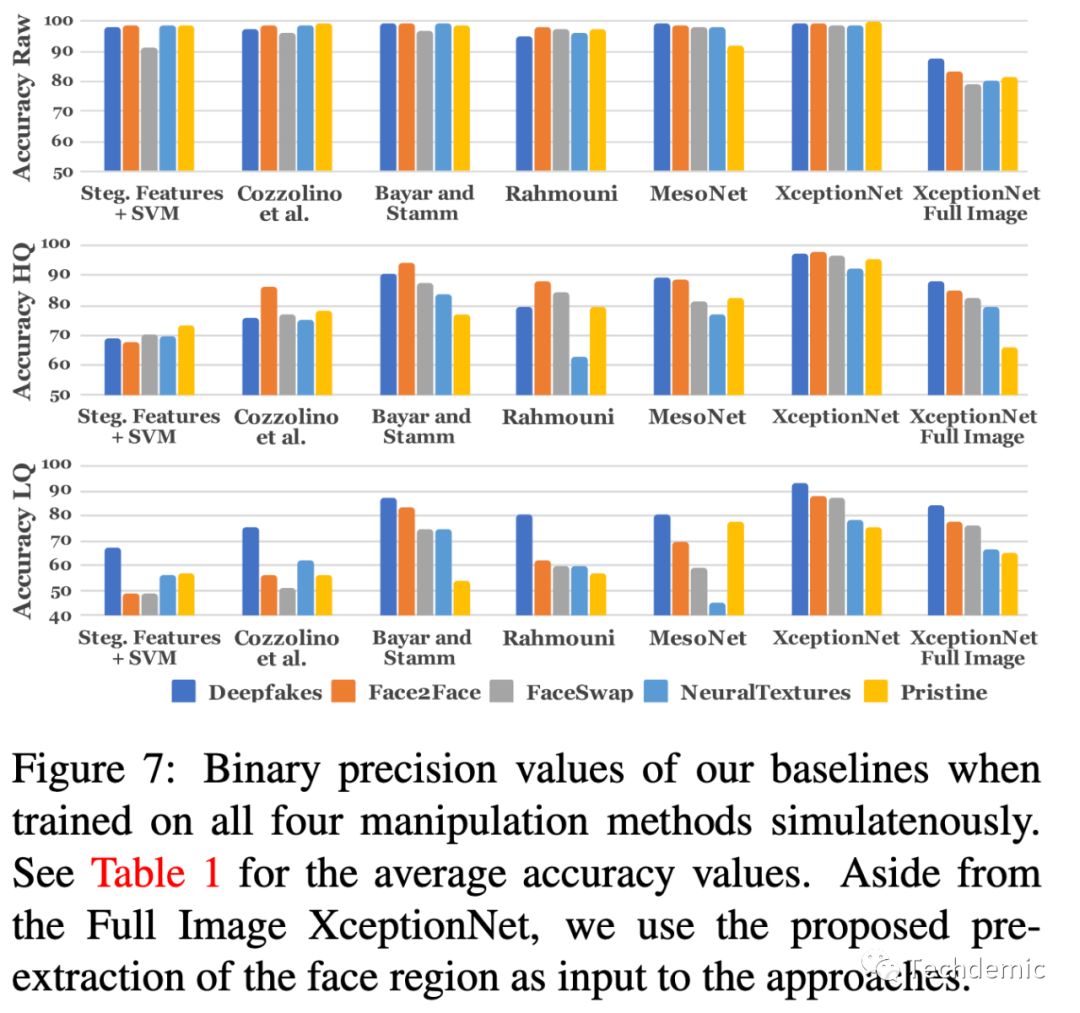
最后放出结果图,可以看到这个baseline模型对所有类型的造假以及原始视频识别的准确率都超过了95%以上!
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J. and Nießner, M., 2019. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1-11).

