




作者介绍
李振环,贝壳金服数据基础架构负责人。
金融级大数据平台特征
传统的大数据平台主要解决分布式存储和计算问题,更关注大数据平台的可扩展性、高可用性和计算性能等问题。金融级大数据平台在传统大数据平台之上更关注以下问题:
1. 安全性:要确保用户信息安全性,如果用户数据发生泄漏会是重大的安全事故。尽量脱敏或加密用户敏感信息,数据分析师使用数据必须有合规的流程审批和权限控制。审批流程需要依据数据是否敏感,是否跨 BU 进行不同的审批策略。确保所有的数据操作都符合安全需要并记录审计。
贝壳金服大数据平台架构
在开始讨论之前先从全局看一下贝壳金服大数据平台的架构,进而讨论相关架构如何解决特定的安全性和严谨性问题。
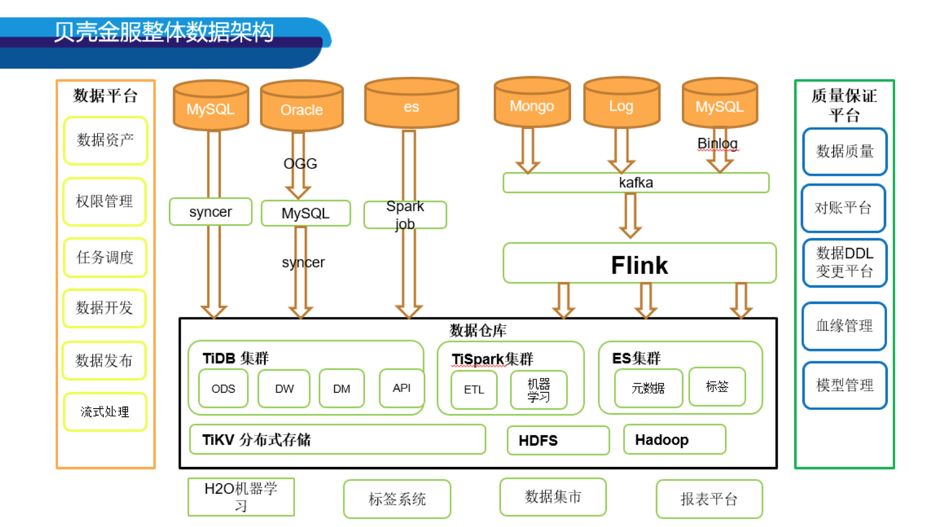
数据架构图中间是最核心的大数据平台。贝壳金服基于 Spark 和 TiDB 搭建金融级大数据平台,使用工具 Syncer 将业务数据实时同步到 TiDB,Spark 能实时查询 TiDB 和 Spark Table 的数据并做关联分析。经过 Spark ETL Job 数据处理,将报表层和服务层的数据落地到 TiDB,再基于 TiDB 支持报表可视化和数据 API 服务。其它数仓中间层数据都存储在 Spark Table 中。数据开发人员基于 Spark 和 TiDB 进行日常数据开发。
架构图左右两边是基于核心大数据平台衍生出来的平台,左边数据平台提供日常开发和调度功能,贝壳金服基于 Zeppelin 做数据开发,基于 Azkaban 做数据调度。大数据组深度开发定制了 Zeppelin 和 Azkaban,并结合内部自研产品,有效提升了数据平台安全性和易用性。右边是保障数据质量提高大数据平台严谨性的平台。主要用于保证数据准确性和一致性。
分析完数据平台架构,我们再聊一下对应架构是如何解决相关问题。
安全性
加密用户敏感数据
数据资产平台

图 2 数据资产平台、借款人和实际收款方为 C3(敏感)字段
数据权限申请审批流程
此流程可以根据数据是否敏感,以及数据是否跨 BU 来路由不通的审批节点。比如 Table A 有 4 个敏感字段,6 个非敏感字段。当用户只申请 6 个非敏感字段时可以进行简单流程审批,如果申请字段中包含敏感字段则需要更多安全合规的同事审批。贝壳金服也是基于数据资产平台之上开发的流程审批功能。用户可以在数据资产平台直接进行权限申请和审批操作。
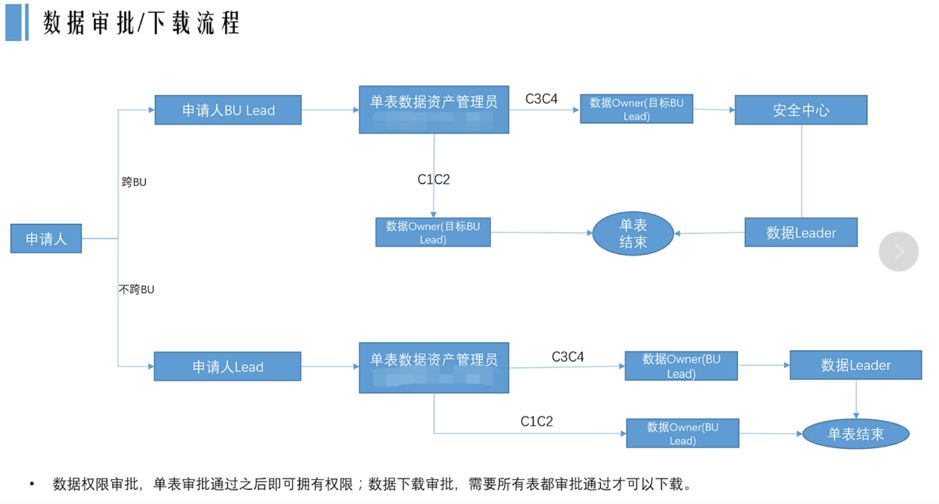
图 3 贝壳金服数据审批流程
权限管理系统
SQL 解析平台
权限管理系统会将用户和 SQL 发送给权限认证系统。在权限认证系统中会通过 SQL 解析拿到 SQL 中的 Table 和 Column,并校验此用户是否有对应的权限,如果没有权限则提示用户申请权限,验证通过之后则继续执行 SQL。贝壳金服在 Spark Catalyst 之上进行二次开发,实现了 Spark SQL 和 TiDB SQL 的解析。上述过程具体流程如图:
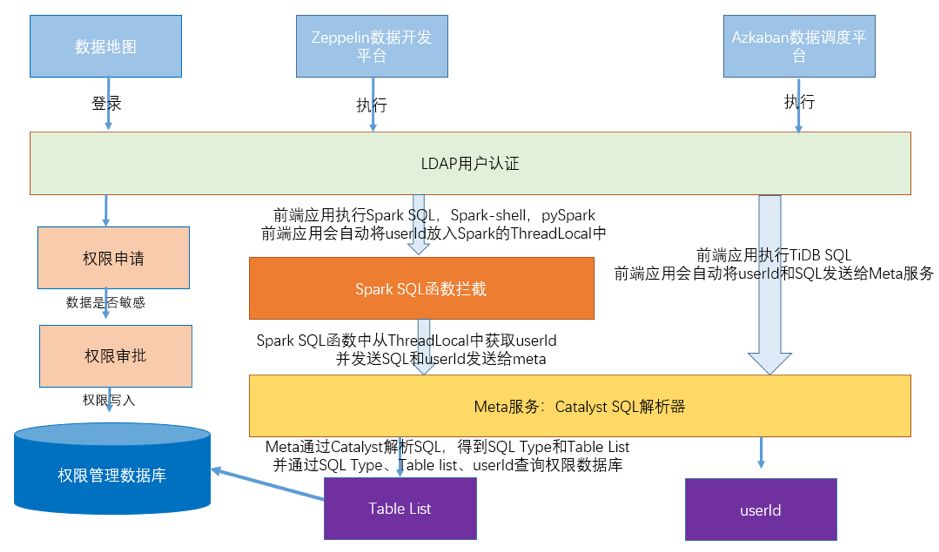
图 4 权限管理流程
严谨性
数据血缘平台
数据血缘平台可以降低业务变更对大数据平台数据正确性影响。业务 DDL 变更可能会导致报表数据不正确,而部分金融活动是依赖报表数据运作的。
在贝壳金服的业务系统上线都会经过 DBA 的管理平台上线。大数据资产平台管理了表的元数据信息,还会将表、任务、报表、服务和数据开发的关系打通。当一个表的数据结构发生变化时,通过上述的关系能直接发出相关报警给数据开发人员,提醒数据开发人员及时和业务沟通关注对应的业务变化。具体过程说明:例如业务人员修改了 ODS(数据仓库原始数据层)的数据,删除了一个 Column。通过表与表的数据血缘关系发现此 ODS 的 Job 会导致报表层表数据不正确,再由报表层表和报表的血缘关系推算出会影响到哪些报表,并及时发出相关报警邮件。
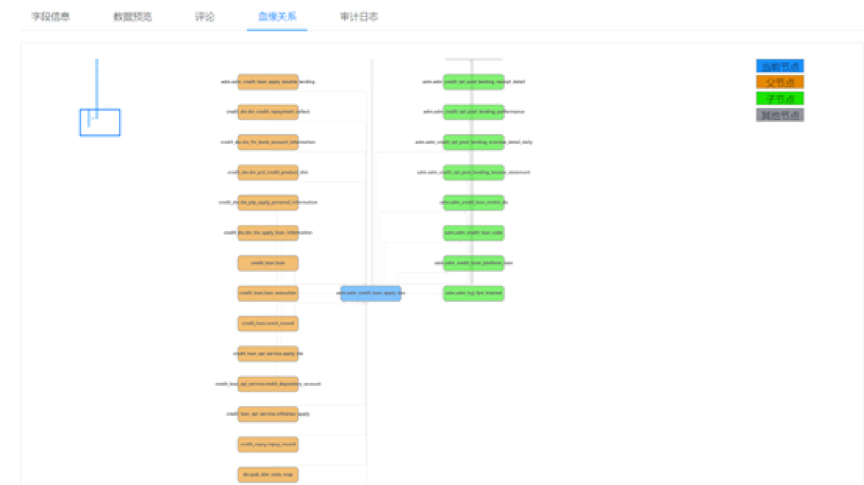
图 5 数据血缘展示
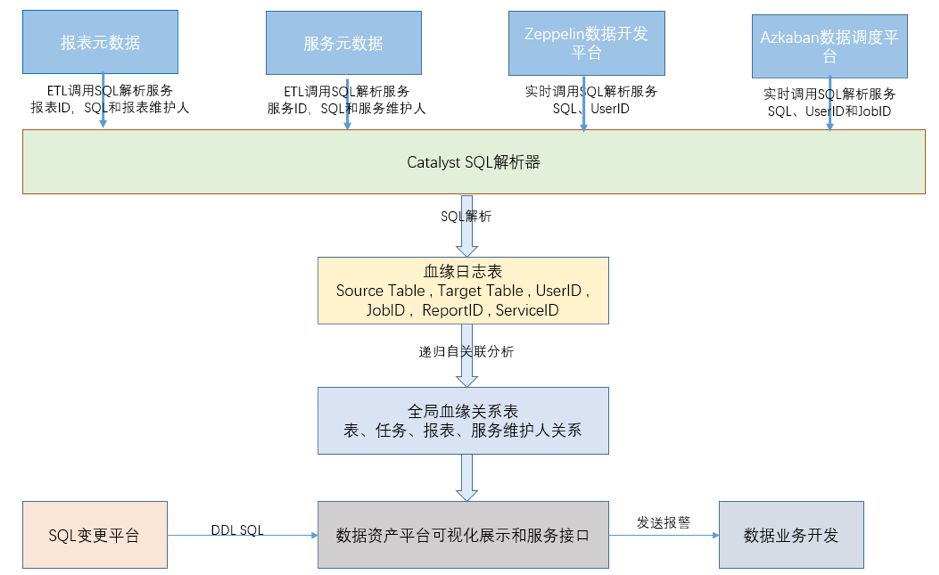
图 6 血缘实现分析
数据质量平台
数据质量平台保证产生的数据是符合基础的逻辑。比如今天的数据总量应该大于昨天的数据量,比如利息应该在合理的区间。
大数据平台采用了自研的数据质量平台,在数据质量平台配置 Spark SQL 或者 TiDB SQL 来校验数据是否正确。并通过将数据质量平台服务化与调度系统打通来管理数据校验逻辑之间的依赖关系。例如可以在核心日报邮件发送之前检验重要的数据是否为空,是否大于 0。另外数据质量平台支持强弱规则,如果是强规则数据校验失败则直接当前 Job 运行失败并发出相关报警,下游 Job 则会继续等待。如果是弱规则数据校验失败则只发出报警邮件下游 Job 继续运行。

图 7 数据质量平台
对账平台
对账平台保证有逻辑上对应关系金额数据上下游能完整匹配,确保核心金额数据正确性和一致性。比如业务收款、放款数据和支付系统有逻辑上上下游的关系,则需要保证对应数据的一致性。
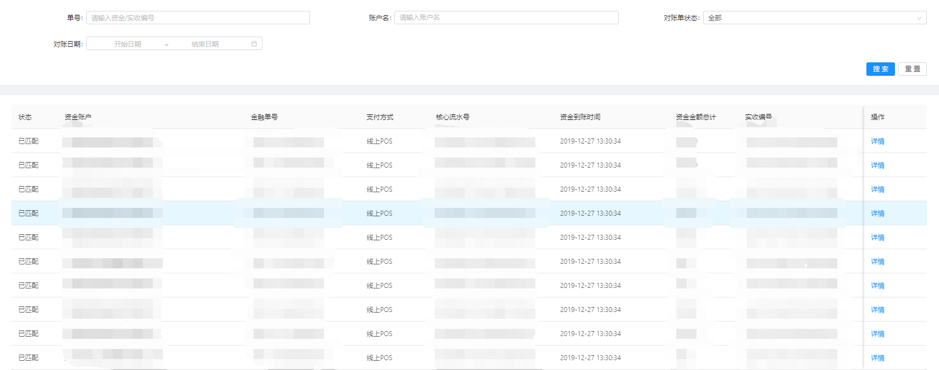
图 8 对账平台
总结
延展阅读:
贝壳金服 TiDB 在线跨机房迁移实践

