




“ Schema Registry提供了元数据的服务,它可以存储多个版本的Schema,支持不同的兼容性配置以及根据兼容性的要求进行Schema的演进。本文介绍Apache Pulsar的Schema Registry的原理和实现。”
Schema Registry
类型安全在任何围绕消息总线(像Kafka、Pulsar、RocketMQ这样的系统)构建的应用系统中都是非常重要的。生产者和消费者需要某种机制来协调消息数据的类型,以避免出现各种潜在的问题,比如序列化和反序列化的方式不一致。类型安全通常有两种处理方式:
client-side:客户端即负责消息的序列化和反序列化,并且需要保证生产和消费的消息的类型安全。说白了就是把“一切”交给用户,消息体就是byte[],生产者给的是什么就写入什么。消费者拿到消息后基于和生产者的约定,将byte[]的数据反序列化成特定类型的数据。这种方式最大的问题是生产者和消费者之间是基于约定的,一旦生产者写入了非约定的数据,下游的消费者将无法解析数据(往往这种“脏”数据的问题都是非常难以处理的)。
server-side:数据安全由服务端保证,生产者和消费者需要和服务端来确定消息类型。这种方式真正意义上的保证的数据的类型安全。避免了Producer写入非法数据的问题。
Pulsar对两种方式都进行了支持,可以任意选择其中的一种方式使用,也可以混合两种方式使用,比如生产者使用第一种方式,而消费者采用第二种方式:
第一种方式而言,生产者和消费者都处理byte[]数据,系统将“一切”交给用户
第二种方式,Pulsar构建了Schema Registry来支持上传Schema,由Schema来指明数据类型并进行数据验证。
也可以把直接采用byte[]作为消息体的使用方式作为一种Schema的特例,它的Schema指明了消息内容是byte[]类型的,这样可以在一个更高的层次上来抽象一个MQ系统的设计。
Architecture
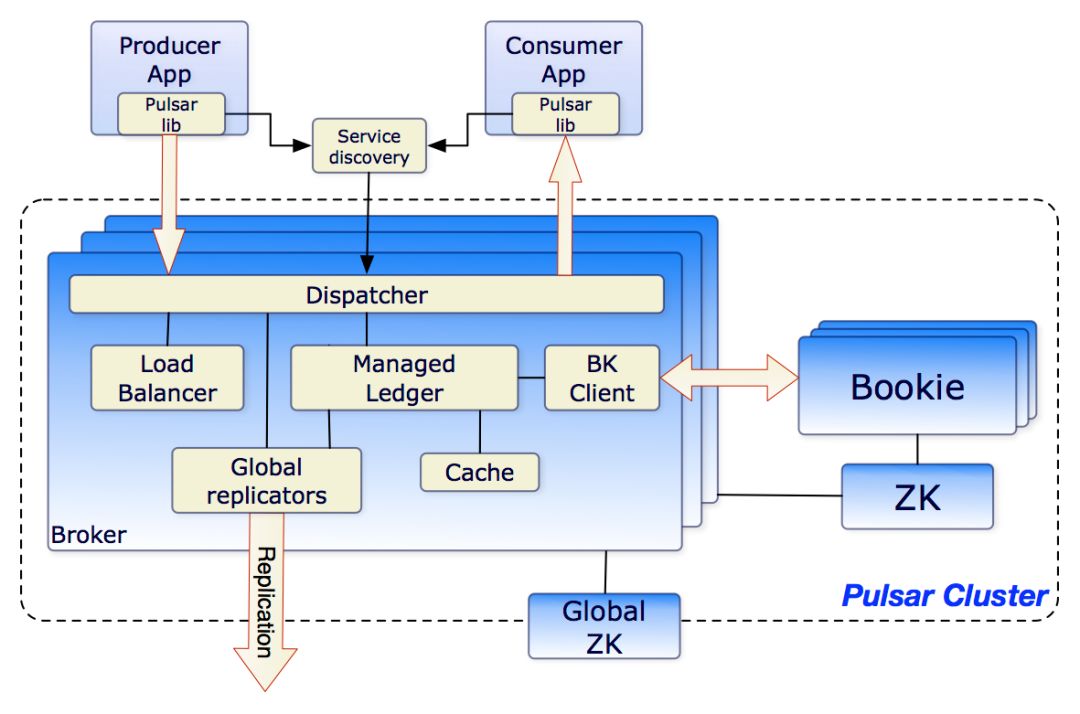
Pulsar将Schema数据存储在Bookie上,所有从架构上并没有因为支持Schema而引入额外的组件。
Schema存储在Bookie上,Schema的写入、读取操作都通过Broker和Bookie交互,这个逻辑和消息的写入读取操作是一致的,那么不需要额外考虑Schema的可用性和可靠性的问题(如果使用其他设备来支持Schema Registry,那么就需要考虑高可用和高可靠的问题,比如Schema Registry不可用导致消息获取不到Schema无法解析,那么就影响系统整体的可用性了)。
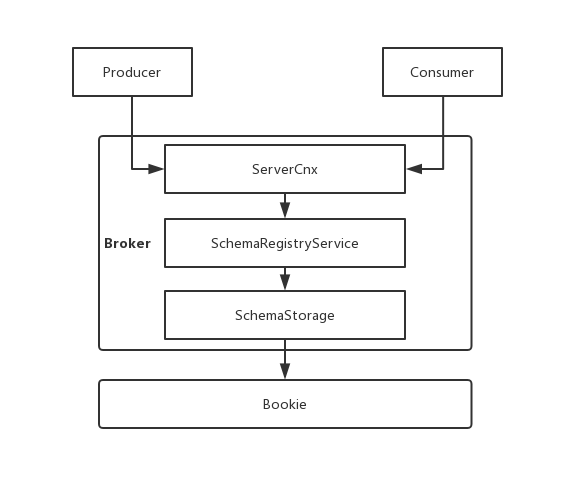
如上图,Pulsar在服务端主要由两个组件来服务Schema:
SchemaRegistryService:SchemaRegistry相关接口
SchemaStorage:Schema存储接口,提供了基于Bookie的存储实现
整体上看,Pulsar实现Schema Registry的方式非常优雅,没有给系统增加额外的依赖,这也得益于系统本身计算和存储分离的架构。
How Schemas Work
Pulsar的Schema应用在Topic级别,Producer和Consumer“上传”
自己的Schema。
Schema数据结构:
name: 在Pulsar中,schema的name是它应用的topic的名称
paylod: schema的二进制数据
type: schema的类型,有JSON、AVRO等
properties: Map<String,String>格式,用于存一些拓展的信息
Schema Example
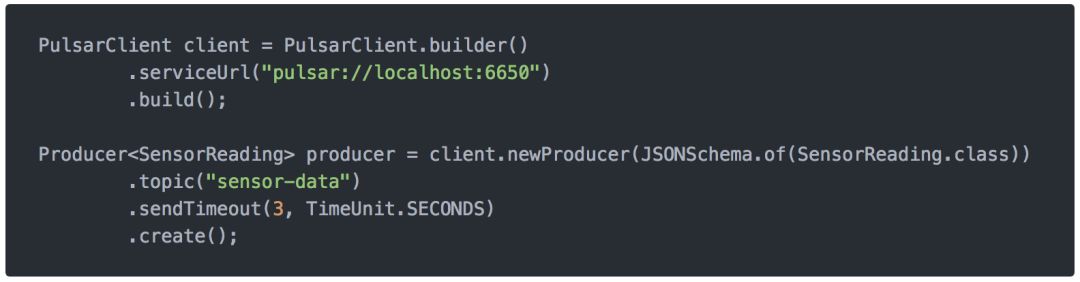
以上图为例,当Producer连接到Broker时:
topic不存在schema:schema被上传的broker并存储到BookKeeper
schema已经存在:broker校验producer的schema是否是兼容的,并决定是否存储,如果是新的schema则以新的版本号存储schema
总结
本文简单的介绍了Pulsar的Schema Registry,另外最近Pulsar发布了2.3.0版本,引入了更多的Schema类型,在Pulsar Admin中添加了Schema的管理机制来更好的使用Schema。相对于Pulsar“自包含”的实现Schema Registry能力,Kafka则采用Confluent Schema Registy来实现Schema的能力。无论是Pulsar还是Kafka,都将Schema能力纳入到自己的体系中,这是从一个简单的消息的Pub/Sub系统到一个流计算平台重要的组件。

