




对于单机和分布式In-memory图计算系统,图数据在内存中的构造方式和计算时数据的接入方式(数据的本地性)对系统的整体性能起决定性作用。本文整理清楚NUMA-aware是什么,以及与L3 Cache的关系,它们对In-memory图计算系统非常重要。
Memory on these systems is broken up into “local” and “remote” memory, based on how near the memory is to a specific core executing a thread. Accessing remote memory is generally more costly than local memory froma latency standpoint, and can negatively impact application performance if memory is not allocated local to the core(s) running the workload. Therefore to improve performance, some efforts must be made in Linux environments to ensure that applications are run on specific sets of cores and use the memory closest to them.
The NUMA architecture revolves around the concept that subsets of memory are divided into “local” and “remote” nodes for systems with multiple physical sockets. Because modern processors are much faster than memory, a growing amount of time is spent waiting on memory to feed these processors. Since local memory is faster than remote memory in multi-socket systems, ensuring local memory is accessed rather than remote memory can only be accomplished with a NUMA implementation. Accesses to the local NUMA node are normally lower latency and higher bandwidth than memory accesses to remote NUMA node(s).
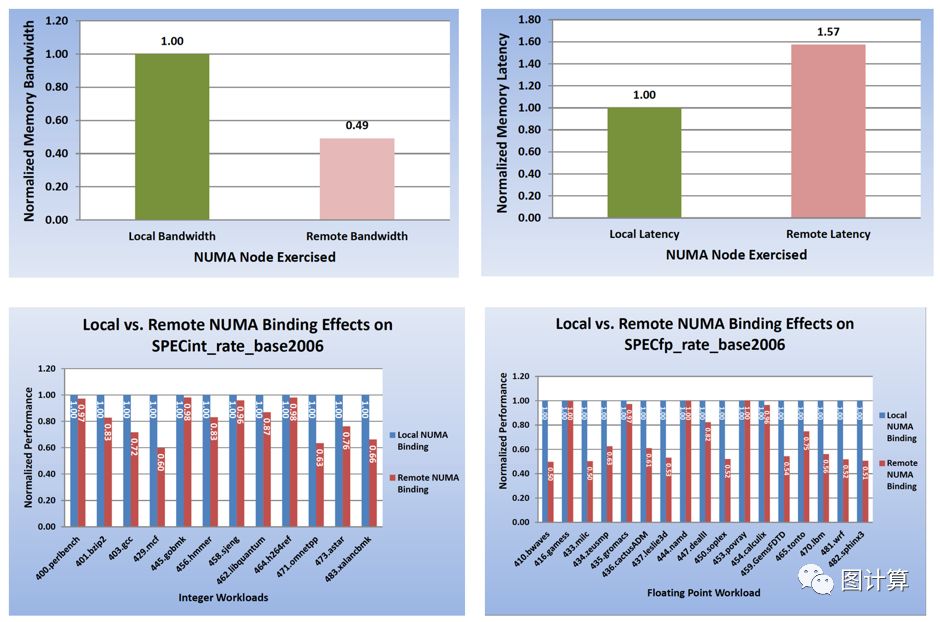
Memory bandwidth represents the rate at which memory can be read from or written to by a processor. Memory latency is the time it takes to initiate a 64-byte message transfer. Both metrics are important for evaluating memory subsystem performance.
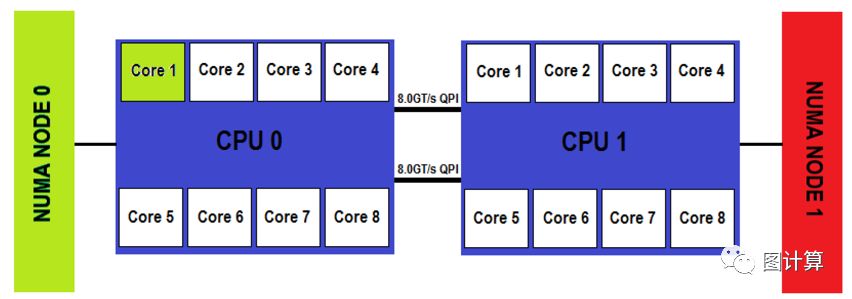
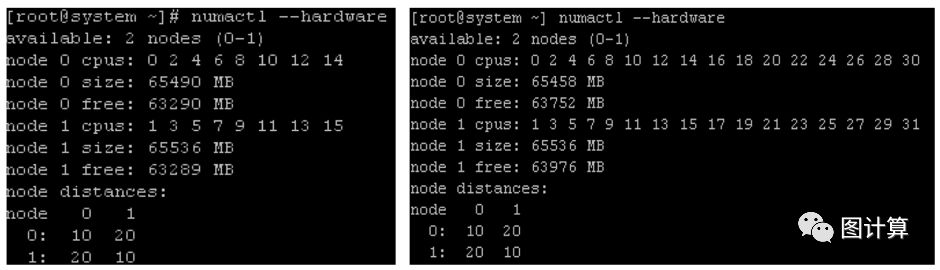
We can see that the first core on CPU 0, colored in green, is local to NUMA node 0. This means that the DIMM slots populated closest to CPU 0 are local, and the DIMM slots populated closest to CPU 1 (NUMA node 1 in red)are remote. This is due to the fact that to reach NUMA node 1 from Core 1 on CPU 0, the memory request must traverse the inter-CPU QPI link and use CPU 1’s memory controller to access this remote node. The addition of “extra hops”incurs latency penalties on remote NUMA node memory access.
Note that each core is now represented as a different “OS CPU”, which is how Linux refers to logical processors.
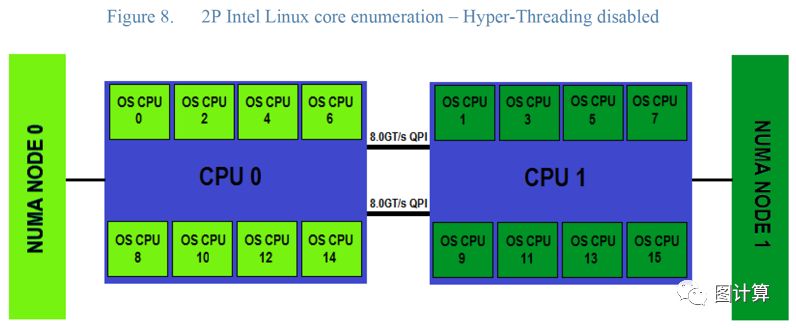
It is also important to note that the first OS CPU (0) is the first core on the first physical processor package. Now note that OS CPU 1 is the first core on the second physical processor package. It is also important to note which cores are local to any particular NUMA node, and that OS CPUs and NUMA nodes are numbered starting from 0.
For Intel Xeon-based systems, there can be up to two logical processors per physical core when Hyper-Threadingis enabled. The two logical processors represent one “real core” and one“Hyper-Threaded sibling”.

The core enumeration pattern represented in Figure 9 shows the same 2-socket processor Intel Xeon-based system with Hyper-Threading enabled. The first number before the “/” character represents the OS CPU number assigned to the real core. The second number after the “/” character represents the OS CPU number assigned to the Hyper-Threaded sibling.
Note that real cores are again enumerated first in a round robin fashion between physical processor packages. After all of the real cores are enabled, the Hyper-Threaded siblings are enabled in the same round robin pattern.
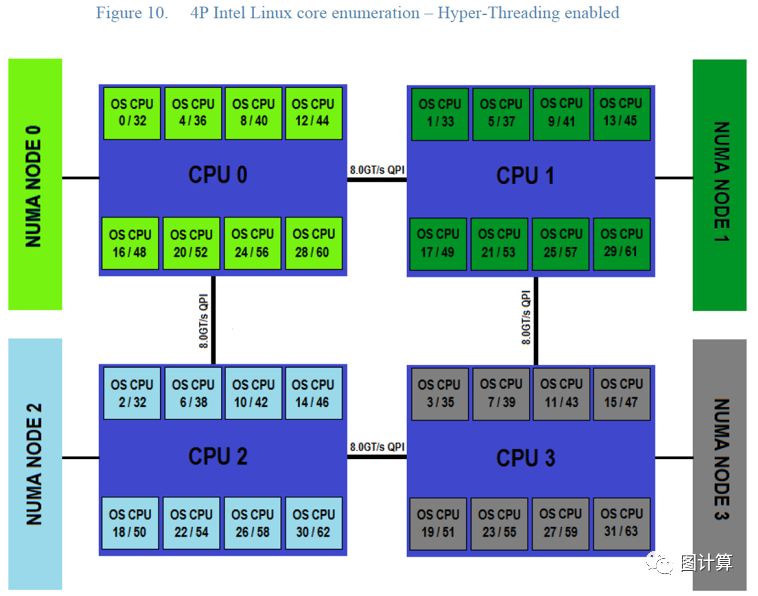
Because of the fact that a given core can be up to two QPI hops away from one of the four NUMA nodes based on the “box” topology, it can be more important to aggressively affinitize workloads for this architecture.


AMD的处理器对应的NUMA结构则有所不同
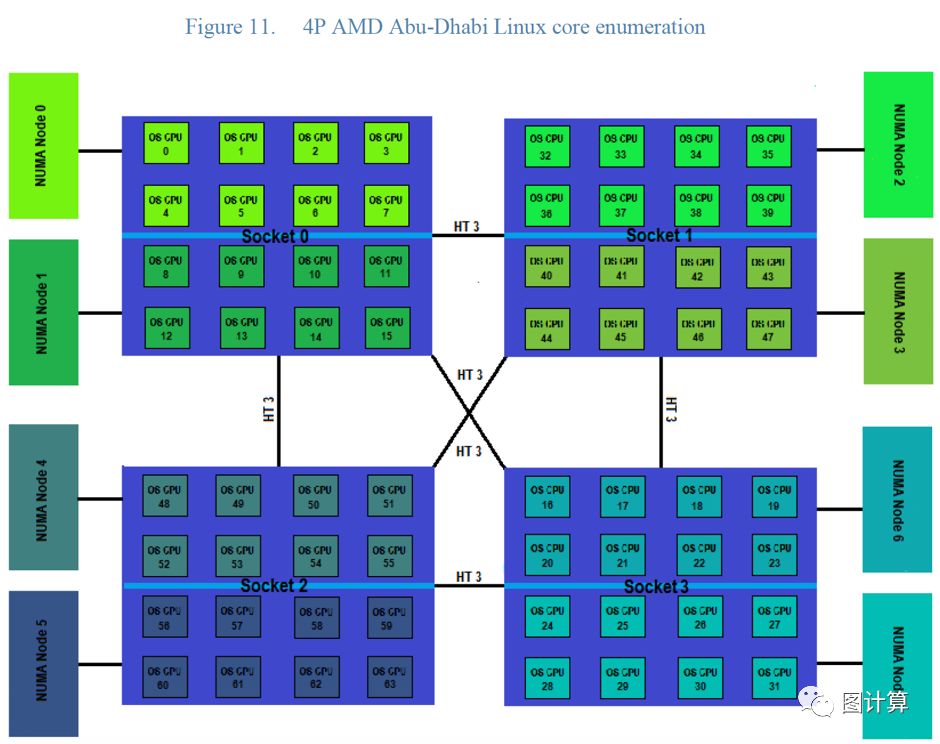
NUMA topology
# numactl --hardware
# numastat
# numactl --show
Memory allocation scopes and policies
There are several components of a Memory Allocation Policy: scope, mode, mode flags and specific nodes provided as an argument.
Memory policy scopes:默认策略
The System Default Policy is called local allocation.This policy dictates memory allocation for tasks that take place on the NUMA node closest to the logical processor where the task is executing. This policy is a reasonable balance for many general computing environments, as it provides good overall support for NUMA memory topologies without the need for manual user intervention. However, under a heavy load, the scheduler may move the task to other cores and leave the memory allocated to a NUMA node now remote from where the task isexecuting.
In order to provide for optimal performance on a NUMA-aware system, it can be important to pin performance-sensitive workload threads to specific cores local to one physical processor, and ensure that all memory allocation for that process occurs on the local NUMA node. This provides for two potential performance enhancements. By executing a particular workload on specific OS CPUs, you can prevent the operating system scheduler from shuffling processes around to different cores during execution, as can occur under heavy load. By fixing the cores for process execution, you can target multiple threads on processors that share the same L3 cache. The workload can also be affinitized to a particular NUMA node to maximize local memory access. NUMA-aware和L3 Cache共享(相同的socket)
QPI <Quick Path Interconnect>介绍
https://en.wikipedia.org/wiki/Intel_QuickPath_Interconnect
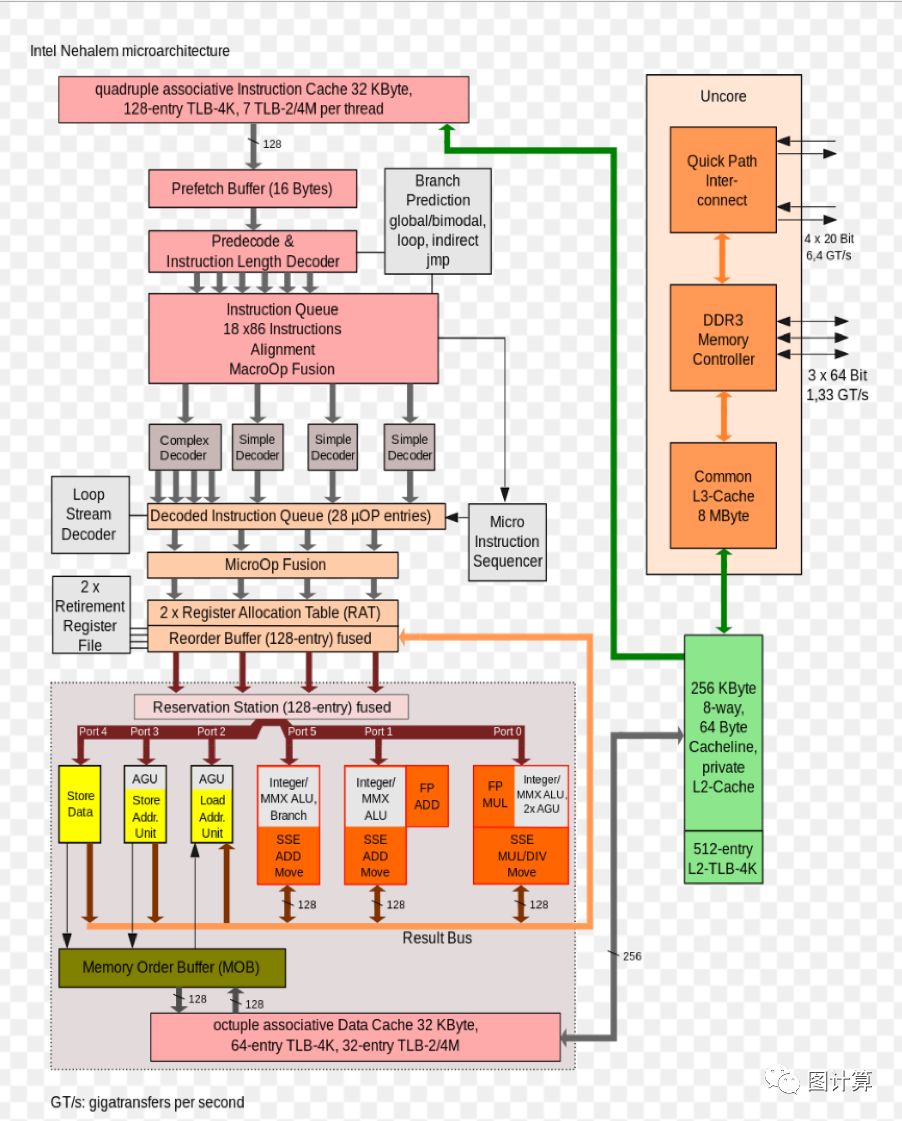
https://upload.wikimedia.org/wikipedia/commons/6/64/Intel_Nehalem_arch.svg
The QPI is an element of a system architecture that Intel calls the Quick Path architecture that implements what Intel calls Quick Path technology.[11] In its simplest form on a single-processor motherboard, a single QPI is used to connect the processor to the IO Hub (e.g., to connect an Intel Core i7 to an X58). In more complex instances of the architecture, separate QPI link pairs connect one or more processor sand one or more IO hubs or routing hubs in a network on the motherboard, allowing all of the components to access other components via the network. As with HyperTransport, the QuickPath Architecture assumes that the processors will have integrated memory controllers, and enables a non-uniform memory access (NUMA) architecture.
Although some high-end Core i7 processors expose QPI,single-socket boards do not expose QPI externally, because these processors are not intended to participate in multi-socket systems. However, QPI is used internally on the sechips to communicate with the "uncore"(见上图,包含内存控制器),which is part of the chip containing memory controllers, CPU-side PCI Expressand GPU, if present; the uncore may or may notbe on the same die as the CPU core.
Polymer PPoPP’15 《NUMA-Aware Graph-Structured Analytics》
Though conventional wisdom is that remote memory accesses have higher latency and lower throughput than local ones, we quantitatively show that sequential remote accesses have much higher bandwidth than both random local and random remote ones (2.92X and 6.85X on our tested machines).
两张图看懂NUMA 和 L3 Cache的关系
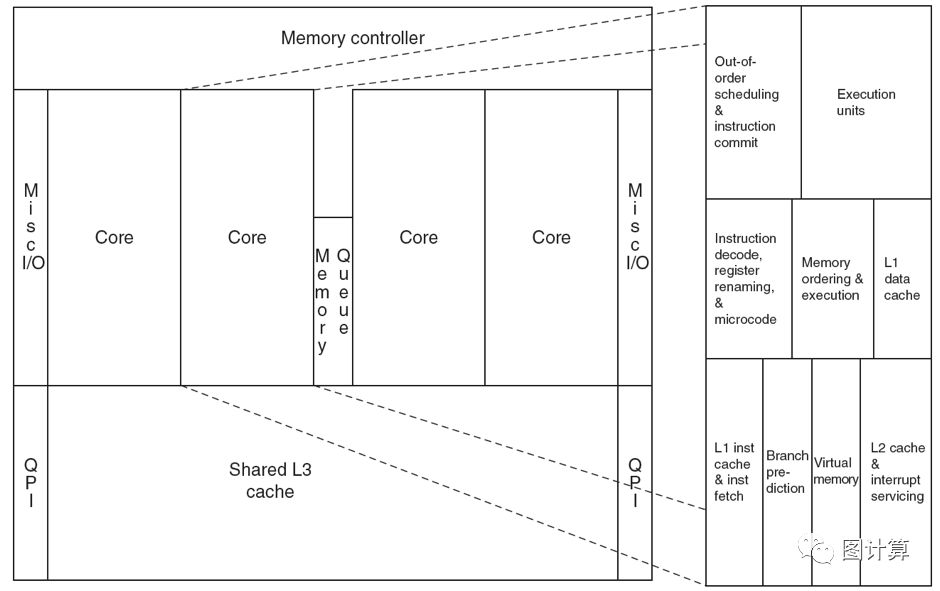

主要参考:《NUMA Best Practices for DellPowerEdge 12th Generation Servers》
本文内容仅个人观点,如有错误和不足之处还望大家雅正,如果对您有所帮助则是我的荣幸,如需本文相关资料请发邮件到zhangguoqingas@gmail.com或留言!
