




毋庸置疑,现在软件行业正在发生翻天覆地的变化。一切都在迈向云时代,几乎所有公司都在手忙脚乱的从传统开发部署模式转向云模式。快速学习适应潮流才能更好的适应这个时代的需要。但很多知识完全没有必要从零学起,有效的一种方式就是学习目前业界的最佳实践(best practice),直接站在巨人的肩膀上来为设计实现我们自己的解决方案。本文主要介绍目前在云上的最佳的metrics monitoring解决方案。
一、什么是metrics monitoring系统
当我们的micro-services部署到云上之后,我们可能会有以下疑问:
1、在cluster上启动了这么多服务,各个物理节点或虚拟机的CPU、Memory、网络使用情况到底怎么样?
2、Kubernetes到底启动了多少个POD,多少个Services?
3、整个Cluster中,到底运行了多少Container,每个Container占用多少系统资源?
4、我们自己的服务适应情况怎么样?平均每秒有多少个请求?平均响应每个请求需要多少时间?
5、......
当你有上面这些疑问时,那就是着手部署Metrics monitoring系统的时候。
二、技术栈(Tech Stack)
不管后端采用什么技术收集各种metrics,对于前端来说,Grafana基本就是目前事实上的标准。Grafana有非常灵活和强大的构建各种dashboard的能力,而且它支持几乎所有目前流行的各种基于时间序列(time-series)的数据源。Grafana针对每种不同的数据源提供一个定制的查询编辑器(Query Editor),原因很简单,不同的数据源有不同的查询语法。
当然,并不是说Grafana适用于所有的前端Dashboard展示的场景。对于Log的分析,显然Kibana更适用。但Kibana紧紧与Elasticsearch绑定,虽然也很流行,人气也很旺,甚至高过Grafana,但它适用场景的广度显然不如Grafana,而且Kibana的构建Dashboard的能力也不及Grafana。这只是题外话,回头我会抽时间再写一篇用Filebeat + Elasticsearch + Kibana构建云时代的Log解决方案。
Grafana官方支持的数据源很多,其中之一就是Prometheus。后端数据源的主要作用就是采集并存储基于时间序列的各种metrics。如果目前实际正在使用的数据源不被Grafana支持,那么你可以开发一个plugin,来支持你自己的数据源,这不在本文的讨论范围内。本文重点要讲的就是Prometheus。
所以Prometheus + Grafana就是今天要讲的metrics monitoring系统的技术栈。
三、架构
千言万语不如一张图,具体架构见下图,
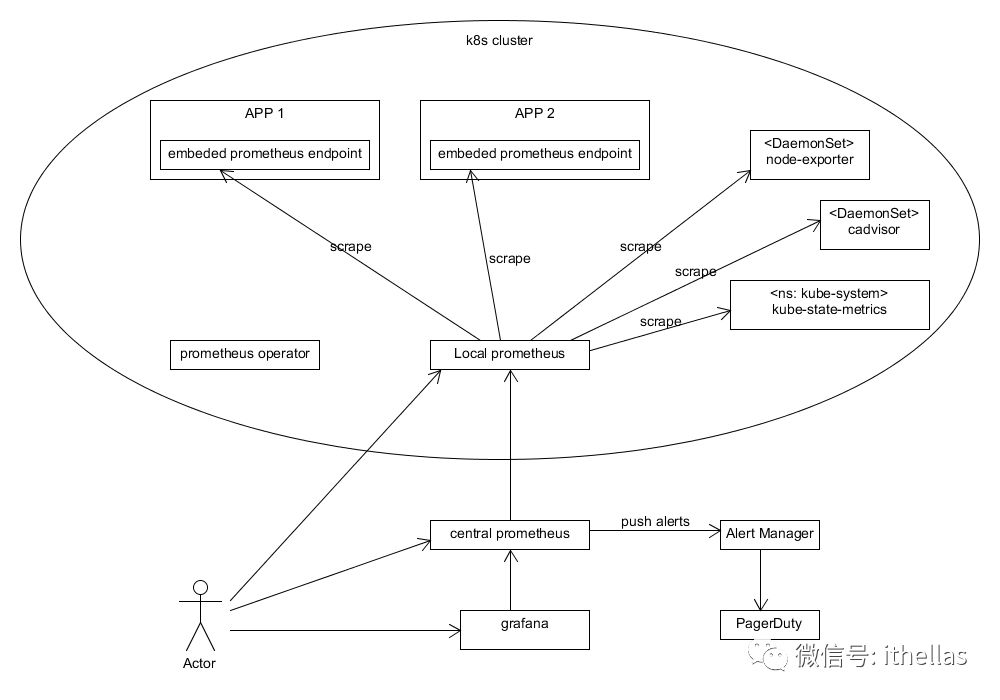
图中椭圆中的所有应用都部署于Kubernetes cluster中。Local Prometheus收集Cluster范围内的所有Metrics,然后所有Metrics汇集到central prometheus。之所以有一个central prometheus,因为当有多个cluster时,可以有一个集中的prometheus来管理所有的metrics。
Local prometheus从各个应用收集Metrics。其中APP1和APP2是自己开发的应用,需要用到Prometheus提供的客户端库(client library)来instrument自己的应用,并实现一个embedded prometheus endpoint,也就是一个embedded http server。Local prometheus会定期来访问这些embedded prometheus endpoint,来获取所有暴露出来的metrics。
node-exporter、cadvisor、kube-state-metrics都是开源的项目,都已经支持了prometheus,也就是说他们已经使用prometheus的client library来instrument了自己的应用,并有一个embedded prometheus endpoint。网上都有现成的YAML文件,可以直接将它们部署到kubernetes cluster中。需要的话,可以直接网上搜索,或者给我留言。
node-exporter用来获取kubernetes cluster中每个节点的metrics,比如CPU、Memory、Filesystem、Network等信息。它是一个DaemonSet类型的POD(DaemonSet是Kubernetes的一个概念,它保证了在每一个节点上只会启动一个POD)。
cadvisor是google自己的一个开源项目,是用来获取kubernetes cluster内每一个container的资源使用情况,比如CPU、Memory等。
github.com/google/cadvisor
kube-state-metrics也是kubernetes的一个开源项目,是用来获取cluster内所有POD、Service的信息。
https://github.com/kubernetes/kube-state-metrics
Prometheus operator的作用是方便管理部署prometheus。operator是一个比较重要的概念,现在几乎所有的产品都有一个对应的operator。比如MySQL operator、etcd operator等等。这些operator的目的就是使部署管理对应的产品更容易、方便。同样,借助于Prometheus operator,可以很方便的部署和配置prometheus。借助于Prometheus operator,可以配置prometheus动态发现所有的prometheus endpoint,这样就非常灵活。如果将上面的APP1、APP2、node-exporter、cAdvisor、kube-state-metrics配置成prometheus的静态配置项,也可以工作,但是当你部署一个新的应用时,则还要修改配置,很不方便。
Local prometheus并不存储历史数据,每次central prometheus获取的都是最新的实时数据。而central prometheus则可配置成存储一定时间的历史数据,默认是15天。Grafana从central prometheus获取数据,并展现在dashboard中。
AlertManager和PagerDuty是用来管理alerts的。AlertManager是Prometheus整个solution的一部分,和Prometheus是同一个公司开发的。PagerDuty是位于San Francisco的一家公司提供alert监控并通知的服务(这个是收费的:,不过有15天的免费试用期:)),具体参考https://www.pagerduty.com/。比如某个节点的CPU使用率超过80%,就产生一条alert。产生alert的规则定义在一个rules.yaml文件中,prometheus会根据这些规则自动产生alerts,并发送到AlertManager中。而AlertManager则可以与PagerDuty集成,将收到的alert路由到PagerDuty。最后PagerDuty则会根据配置通知相应的负责人,比如发邮件、短信或者打电话。据说湾区那边很多公司都在用PagerDuty的服务。
四、如何用Prometheus client library来instrument自己的应用
目前Prometheus官方正式实现的client library有以下几种:
1、Go
2、Java 或 Scala
3、Python
4、Ruby
还有很多第三方实现的client library,几乎涵盖了目前所有的流行语言。这里主要是通过一个简单的例子来介绍如何用Go client library来instrument自己的应用。
package main
import (
"flag"
"log"
"time"
"net/http"
"math/rand"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var addr = flag.String("listen-address", ":8080", "The address to listen on for HTTP requests.")
var (
totalCount = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "example_call_count",
Help: "count of request",
},
[]string{"label1", "label2"},
)
)
func main() {
prometheus.MustRegister(totalCount)
for {
totalCount.WithLabelValues("label1_value", "label2_value").Inc()
time.Sleep(time.Duration(10) * time.Second)
}
flag.Parse()
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(*addr, nil))
}
下面的两条语句就是导入go语言的client library中的两个包,
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
下面这条语句则是Counter类型的metrics,关于prometheus支持的几种metrics类型,可以参考下面的链接,
totalCount = prometheus.NewCounterVec(...)
https://prometheus.io/docs/concepts/metric_types/
下面的几条语句则分别是向prometheus注册定义的metrics,并启动一个embedded HTTP server来对外暴露注册的metrics,
prometheus.MustRegister(totalCount)
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(*addr, nil))
上面这个例子应该是一目了然。就是模拟当前的应用从启动到目前总共收到了多少个请求。for循环里,每隔10秒计数加一,模拟每隔10秒有一个请求进来。因为每个metrics都带有时间信息,所以在Grafana上既可以直接显示这个数值,也可以很容易计算出过去一段时间内的请求率,比如在最近的10分钟内,平均每秒有多少个请求。label是prometheus一个很重要的概念,label主要是每个metrics的维度数据(dimensional data)。这里就不展开说了,因为这个话题要不是一两句能讲清楚的,具体可以参考以下链接,
https://prometheus.io/docs/concepts/data_model/
五、Grafana
Grafana可以很方便的定制各种Dashboard,由于Grafana针对不同的数据源都提供了不同的查询编辑器(query editor)。所以定制Dashboard关键是要熟悉后端数据源提供的查询语言的语法。针对本文来说,就是要理解Prometheus的查询语言的语法。这个就暂时不深入讲了。回头会单独讲讲使用Grafana开发Dashboard的技巧以及一些常见的问题。
--END--
如果你喜欢这篇文章,欢迎转发给更多的朋友!

