




本文基于CentOS Linux 7虚拟机搭建的Hadoop环境。Hadoop版本3.2.0,Java 1.8
首先我们需要安装一些常用工具:netstat、telnet、wget、net-tools、ssh、rsync
yum -y install netstat telnet wget net-tools ssh rsync复制
Hadoop依赖Java环境,我们需要安装一下JDK 1.8,先搜索openjdk1.8的安装包有哪些
yum search java-1.8复制
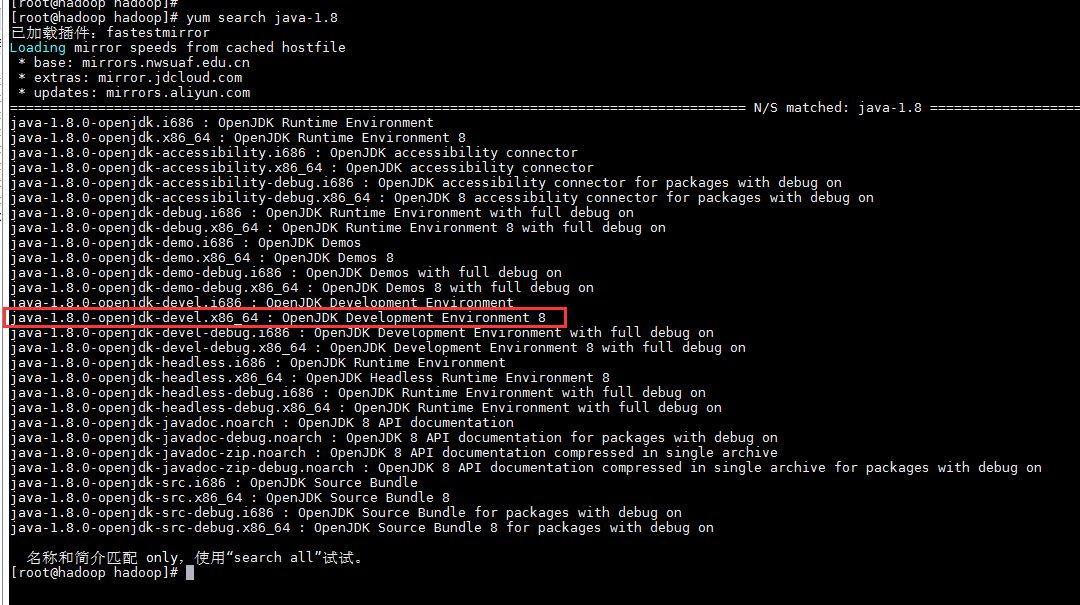
我们安装java-1.8.0-openjdk-devel.x86_64
$ yum -y install java-1.8.0-openjdk-devel.x86_64复制
之后配置环境变量,修改/etc/profile文件,在文件末尾添加以下三行,JAVA_HOM指向你的JDK目录
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.212.b04-0.el7_6.x86_64export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar复制
使配置生效
$ source etc/profile复制
hadoop所需的依赖安装好之后,我们下载Hadoop3.2.0并解压
$ wget http://apache.mirrors.lucidnetworks.net/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz$ tar -zxvf hadoop-3.2.0.tar.gz复制
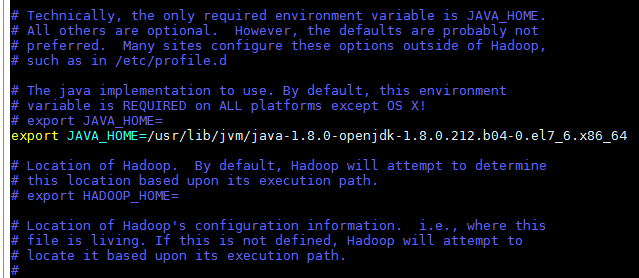
进入hadoop-3.2.0,并修改文件etc/hadoop/hadoop-env.sh,设置hadoop的环境变量JAVA_HOME
在sbin/start-dfs.sh,sbin/stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root复制
在sbin/start-yarn.sh,sbin/stop-yarn.sh顶部添加以下参数
YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root复制
修改etc/hadoop/core-site.xml,我的虚拟机ip是192.168.5.206,所以我的配置如下
<configuration><property><name>fs.defaultFS</name><value>hdfs://192.168.5.206:9000</value></property></configuration>复制
修改etc/hadoop/hdfs-site.xml
<configuration><!-- 指定HDFS副本数 --><property><name>dfs.replication</name><value>1</value></property><!-- 配置namenode的web界面 --><property><name>dfs.namenode.http-address</name><value>192.168.5.206:50070</value></property></configuration>复制
配置免密登录(注意:对本机也需要配置)
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys$ chmod 0600 ~/.ssh/authorized_keys复制
格式化文件系统
$ bin/hdfs namenode -format复制
启动NameNode守护程序和DataNode守护程序,hadoop守护程序日志输出将写入$ HADOOP_LOG_DIR目录(默认为$ HADOOP_HOME logs)
$ sbin/start-dfs.sh复制
浏览NameNode的Web界面,这里我的ip是192.168.5.206,访问http://192.168.5.206:50070/;我们将看到Hadoop的节点Web页面
接下来,我们创建执行MapReduce作业所需的HDFS目录
$ bin/hdfs dfs -mkdir user$ bin/hdfs dfs -mkdir user/<username>复制
将输入文件复制到分布式文件系统中
$ bin/hdfs dfs -put etc/hadoop input复制
运行一些提供的示例
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'复制
检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们
$ bin/hdfs dfs -cat output/*复制
完成后,停止守护进程
$ sbin/stop-dfs.sh复制
我们也可以通过设置一些参数并运行ResourceManager守护程序和NodeManager守护程序,以伪分布式模式在YARN上运行MapReduce作业
修改etc/hadoop/mapred-site.xml,配置参数如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>复制
修改etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>复制
启动ResourceManager守护程序和NodeManager守护程序
$ sbin/start-yarn.sh复制
浏览ResourceManager的Web界面;默认情况下,可访问 http://<ip>:8088/
运行MapReduce作业
完成后,停止守护进程
$ sbin/stop-yarn.sh复制
多节点集群安装可参考官方文档:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
点个“好看”支持一下鸭
点鸭点鸭点鸭
↓↓↓
