




Let's address this solution by listing, in the first place, all the typical approaches to provide a primary data center (production or DC) a disaster recovery (DR) replica of data in another site.
DC: InnoDB Cluster -> MySQL Router -> DR: Standalone MySQL Server
DC: Group Replication -> DR: Group Replication
Stretch InnoDB Cluster across 2 or more data centers with dedicated network with extremely low latency
This document will consider these scenarios.
DC: InnoDB Cluster -> MySQL Router -> DR: Standalone MySQL Server
Having an InnoDB Cluster in the primary or production DC, and a standalone instance in the DR site, can be deployed with simplicity by setting up a MySQL Router instance in the DR site bootstrapped against the primary cluster in DC. The MySQL Server standalone instance in DR site will simply point to the MySQL Router IP (using the R/W or R/O port, arbitrarily) as the source instance, thus executing the typical CHANGE REPLICATION SOURCE TO statement against the very MySQL Router R/W port to configure the asynchronous replication channel, followed by START REPLICA. The Router will then forward the connection from the standalone replica to the primary instance in the primary cluster, which will be used as source in this asynchronous replication channel.
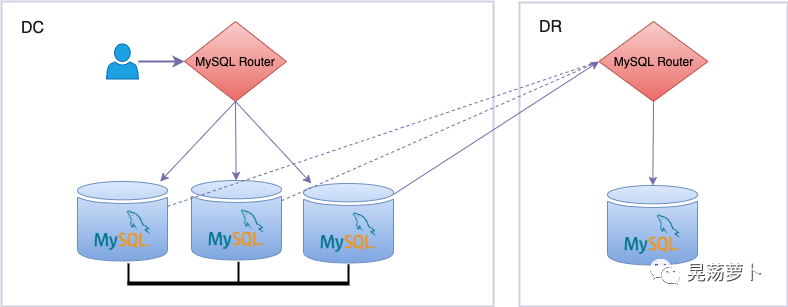
This configuration solves two problems.
The failure of the instance in the primary DC, that was connected by Router and used as source of the replication channel. MySQL Router will automatically point the connection established with the standalone instance to another source in the cluster, so the synchronisation between DC and DR will continue undisturbed
There is no other situation to deal with, as a DR standalone instance failure does not have any further consequence
DR standalone instance can be used to deal with exceptional situations (e.g. DC isolated) to drive traffic to it, but it's important to benchmark in advance the traffic it may receive: the cluster in DC can afford n times the read traffic received in load sharing (with n equal to the number of instances in DC cluster) that this standalone instance will have to deal with.
Starting from MySQL Server 8.0.23, MySQL Server’s asynchronous connection failover mechanism now supports Group Replication topologies, by automatically monitoring changes to group membership and distinguishing between primary and secondary servers. Configuring the recovery instance in DR with such a mechanism, replaces MySQL Router, hence simplifies setup and maintenance of the DR site instance while still having transparent failovers. Read more about setting up this solution in the documentation.
DC: Group Replication -> DR: Group Replication
This solution is probably the most complex, but it's still feasible meanwhile the different failover scenarios are managed. In this scenario, with the two clusters based on the bare Group Replication plugin (that is, not configured using MySQL Shell and therefore without metadata, which also forbids using MySQL Router), all the failovers are managed manually.
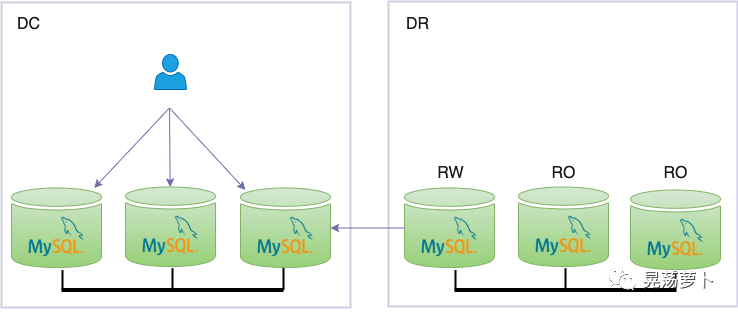
Setup
Replicating events from primary data center (DC) to disaster recovery (DR), is equivalent to configuring the traditional source/replica replication channel between 2 instances, one from the Group Replication cluster in DC, the other from IC.
Instance elected in DC can be the primary instance: will act as source to the replica configured in DR. Another instance, though, could act as source server. Primary instance can be chosen for simplicity, acting as source in the traditional asynchronous replication does not add relevant load.
Instance elected in DR must be the primary instance: will pull events to apply locally to the cluster from source configured in DC (or any other instance if the cluster in DR is configured with multi-primary instance)
While based on the classic asynchronous replication channel between one instance in the cluster in DC and the primary instance of the cluster in DR (only the primary instance of the cluster in DR can receive updates that must be propagated to the cluster, or, in case of multi source Group Replication setup, any instance in DR can be configured as replica):
The failure of the instance in the primary DC which is source to the replica in DR (and not only the failure of the instance, but also the instance only leaving the group but still running), must be detected so that the instance in DR will be configured again to a valid source instance using CHANGE REPLICATION SOURCE TO.
The failure of the instance in DR which is replica to the source in DC must be detected so that another instance can be elected as replica. Let's cover this two scenarios in the following two paragraphs.
Failover of primary instance in DR
If the instance that gets evicted from the cluster, crashes or becomes isolated is the primary instance in the DR cluster, the replication channel must be reconfigured with CHANGE REPLICATION SOURCE TO to elect next primary instance in DR to act as replica and pull events from DC. This is manual, then an implementation to contemplate such a scenario should:
Implement a monitor the check validity of current primary instance in DR
If the instance fails, the monitor should find out what is the next primary and reconfigure it with CHANGE REPLICATION SOURCE TO
RESET REPLICA ALL; for former failed primary instance to clean up former configuration as replica
Failover of primary instance in DR with Consul
A chance to monitor primary instance in DR acting as replica and perform a failover to a new DR primary instance, to be reconfigured as new replica for cluster in DR, can be done with Consul tool from Hashicorp. Refer to the following blog for an example.
Stretch InnoDB Cluster across 2 or more data centers with dedicated network with extremely low latency
The last and simplest solution to have different copies of the data across multiple data centers, is nothing but deploying cluster instances in different data centers.
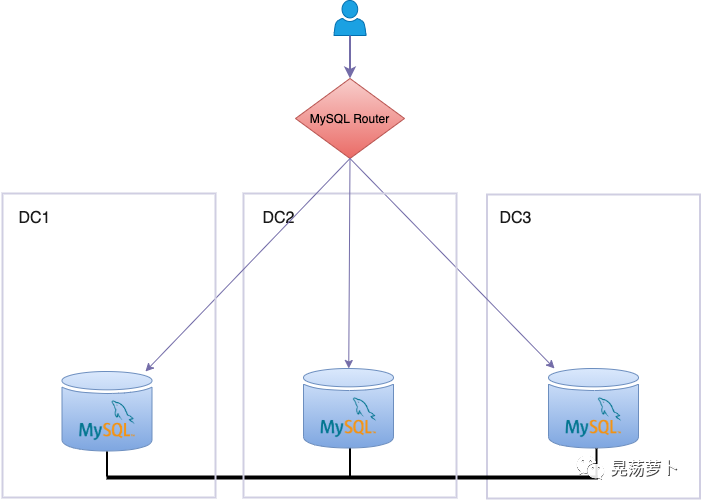
While setting up such a topology is immediate, it has to face latency and instability of the network, so it is required that there's extremely low single digit latency. Unstable networks affect InnoDB Cluster Group Replication solution considerably, as these distributed systems are based on distributed synchronisation, for which extremely performing networks are mandatory. That is one strict requirement, and that is the reason it is usually preferable to deploy geographically redundant solutions using the aforementioned asynchronous replication classic solution.
Stable and low latency links are nowadays guaranteed by cloud environments, where latency between Fault Domains in the same Availability Domain, or even latency between different Availability Domains is stable and ensured, thus making such infrastructures adequate to deploy cluster nodes in data centers spanning different geographic sites.
