




摘要
本文介绍了通过kafka connector组件+Debezium 实现Oracle 增量数据库抽取,并把增量数据写入kafka topic。该方案可以实现增量数据迁移,可以作为OGG迁移的替代工具,该工具的优势在于数据写入kafka topic,实现下游消息的订阅。当然OGG大数据的组件同样可以实现该功能,如果你考虑法律合规性和作为模块内嵌到应用,可以考虑使用Debezium 项目,目前该项目支持,Oracle ,MySQL ,SQL server ,MongoDB 等主流数据库。
kafka connector 是kafka的一个开源组件,是一个用于与外部系统连接的框架,支持数据库,文件等等。根据功能的不同,社区现在有上百种插件,社区相当活跃。kafka connect 有两个核心概念:source和sink,source负责导入数据到kafka,sink 负责从kafka导出数据,他们都被称为Connector。Connector 是作为插件方式集成到kafka集群的,你可以根据具体需求,定制开发属于自己的Connector。
Debezium 开源项目就是针对主流数据库-CDC的Connector,本文将介绍Debezium。
Debezium 介绍
概念
Debezium是一个分布式平台,它将您现有的数据库转换为事件流,因此应用程序可以看到数据库中的每一个行级更改并立即做出响应。Debezium构建在Apache Kafka之上,并提供Kafka连接兼容的连接器来监视特定的数据库管理系统。Debezium在Kafka日志中记录数据更改的历史,您的应用程序将从这里使用它们。这使您的应用程序能够轻松、正确、完整地使用所有事件。即使您的应用程序停止(或崩溃),在重新启动时,它将开始消耗它停止的事件,因此它不会错过任何东西。
插件模式部署
依赖kafka服务,以插件方式和kafka 一起部署。
源连接器,如Debezium,它将数据摄取到Kafka topic
接收连接器,它将数据从Kafka主题传播到其他系统。

Debezium server模式部署
不依赖kafka,直接解析数据,并投递到一些支持的公有云组件。
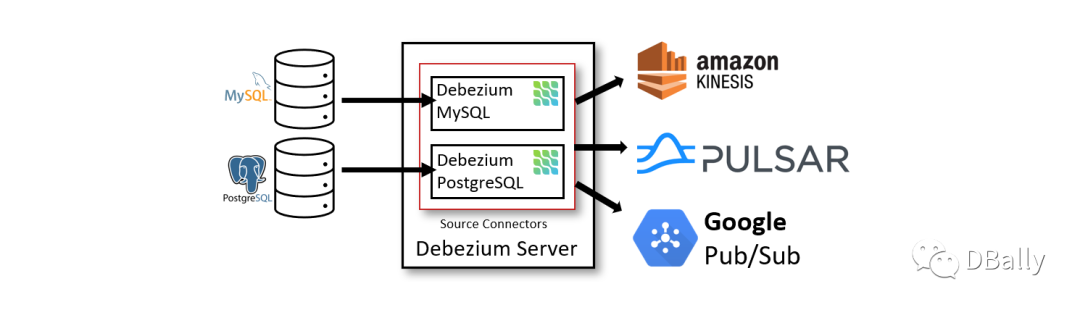
内嵌应用程序模式
内嵌模式,既不依赖 Kafka,也不依赖 Debezium Server,用户可以在自己的应用程序中,依赖 Debezium 的 api 自行处理获取到的数据,并同步到其他源上
目前比较常用部署模式,是以插件方式和kafka一起部署,本文将以debezium-connector-oracle举例说明
kafka部署和 plugin组件配置
1、创建kafka用户,配置环境变量
[root@node1 ~]# useradd kafka
[root@node1 ~]# su - kafka
[kafka@node1 ~]$ vi .bash_profile
export KAFKA_HOME=/app/kafka_2.13-2.8.1
export LD_LIBRARY_PATH=/app/instantclient_19_12
export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$KAFKA_HOME/bin
--解压二进制安装包
[kafka@node1 ~]$ tar -xzf kafka_2.13-2.8.1.tgz -C app
--创建plugin路径
[kafka@node1 ~]$ cd app/kafka_2.13-2.8.1
[kafka@node1 ~]$ mkdir -p plugins
--解压到文件夹
tar -xvzf debezium-connector-oracle-1.7.0.Final-plugin.tar.gz -C app/kafka_2.13-2.8.1/plugin/
-- 需要把Oracle连接驱动拷贝kafka libs文件夹下,ojdbc8.jar需要自己下载。
cp ojdbc8.jar app/kafka_2.13-2.8.1/libs复制
数据库层配置
1、启用数据库的最小附件日志和表级别的全字段附件日志
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
- 示例
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- 创建 用户并赋权
CREATE USER c##dbzuser IDENTIFIED BY dbz
DEFAULT TABLESPACE users
QUOTA UNLIMITED ON users
CONTAINER=ALL;
GRANT CREATE SESSION TO c##dbzuser CONTAINER=ALL;
GRANT SET CONTAINER TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$DATABASE to c##dbzuser CONTAINER=ALL;
GRANT FLASHBACK ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ANY TRANSACTION TO c##dbzuser CONTAINER=ALL;
GRANT LOGMINING TO c##dbzuser CONTAINER=ALL;
GRANT CREATE TABLE TO c##dbzuser CONTAINER=ALL;
GRANT LOCK ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT CREATE SEQUENCE TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR_D TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG_HISTORY TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_LOGS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGFILE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVED_LOG TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO c##dbzuser CONTAINER=ALL;复制
standalone 的方式启动服务
--zookeeper 配置文件
[kafka@node1 ~]$ vi app/kafka_2.13-2.8.1/config/zookeeper.properties
dataDir=/app/data/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=false
--启动zookeeper服务
[kafka@node1 ~]$ zookeeper-server-start.sh -daemon app/kafka_2.13-2.8.1/config/zookeeper.properties
--kafka 配置文件
[kafka@node1 ~]$ vi app/kafka_2.13-2.8.1/config/server.properties
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/app/data/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
--启动kafka 服务
kafka-server-start.sh -daemon app/kafka_2.13-2.8.1/config/server.properties
--connect 配置文件
[kafka@node1 logs]$ vi app/kafka_2.13-2.8.1/config/connect-standalone.properties
bootstrap.servers=10.96.80.31:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/app/data/connect.offsets
offset.flush.interval.ms=10000
plugin.path=/app/kafka_2.13-2.8.1/plugin
---需要注意,standalone 的方式启动connect 时,需要指定连接器的配置信息。
[kafka@node1 logs]$ vi debezium-oracle-connector.properties
name=hr-connector
connector.class=io.debezium.connector.oracle.OracleConnector
tasks.max=1
database.server.name=ORCL
database.hostname=10.96.80.21
database.port=1521
database.user=c##dbzuser
database.password=dbz
database.dbname=orcl
database.pdb.name=PDB1
table.include.list=hr.test
database.history.kafka.bootstrap.servers=10.96.80.31:9092
database.history.kafka.topic=schema-changes.test
--启动connect ,此时连接器worker进程同时启动
[kafka@node1 logs]$ connect-standalone.sh -daemon app/kafka_2.13-2.8.1/config/connect-standalone.properties app/kafka_2.13-2.8.1/config/debezium-oracle-connector.properties
--后台日志,可以看出执行了闪回查询(as of scn 4842963),
[2021-11-07 21:02:27,103] INFO WorkerSourceTask{id=hr-connector-0} Executing source task (org.apache.kafka.connect.runtime.WorkerSourceTask:238)
[2021-11-07 21:02:27,106] INFO Metrics registered (io.debezium.pipeline.ChangeEventSourceCoordinator:104)
[2021-11-07 21:02:27,106] INFO Context created (io.debezium.pipeline.ChangeEventSourceCoordinator:107)
[2021-11-07 21:02:27,143] INFO Snapshot step 1 - Preparing (io.debezium.relational.RelationalSnapshotChangeEventSource:93)
[2021-11-07 21:02:27,144] INFO Snapshot step 2 - Determining captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:102)
[2021-11-07 21:02:27,743] INFO Snapshot step 3 - Locking captured tables [PDB1.HR.TEST] (io.debezium.relational.RelationalSnapshotChangeEventSource:109)
[2021-11-07 21:02:27,749] INFO Snapshot step 4 - Determining snapshot offset (io.debezium.relational.RelationalSnapshotChangeEventSource:115)
[2021-11-07 21:02:27,968] INFO Snapshot step 5 - Reading structure of captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:118)
[2021-11-07 21:02:29,215] INFO Snapshot step 6 - Persisting schema history (io.debezium.relational.RelationalSnapshotChangeEventSource:122)
[2021-11-07 21:02:32,262] INFO Snapshot step 7 - Snapshotting data (io.debezium.relational.RelationalSnapshotChangeEventSource:134)
[2021-11-07 21:02:32,262] INFO Snapshotting contents of 1 tables while still in transaction (io.debezium.relational.RelationalSnapshotChangeEventSource:304)
[2021-11-07 21:02:32,262] INFO Exporting data from table 'PDB1.HR.TEST' (1 of 1 tables) (io.debezium.relational.RelationalSnapshotChangeEventSource:340)
[2021-11-07 21:02:32,264] INFO For table 'PDB1.HR.TEST' using select statement: 'SELECT "JOB_ID", "JOB_TITLE", "MIN_SALARY", "MAX_SALARY" FROM "HR"."TEST" AS OF SCN 4842963' (io.debezium.relational.RelationalSnapshotChangeEventSource:348)复制
通过reset api 查看connector信息
--查看连接器的名字
[root@node1 ~]# curl -s 10.96.80.31:8083/connectors|jq
[
"hr-connector"
]
--查看连接器的配置
[root@node1 ~]# curl -s 10.96.80.31:8083/connectors/hr-connector/config |jq
{
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"database.user": "c##dbzuser",
"database.dbname": "orcl",
"tasks.max": "1",
"database.pdb.name": "PDB1",
"database.history.kafka.bootstrap.servers": "10.96.80.31:9092",
"database.history.kafka.topic": "schema-changes.test",
"database.server.name": "ORCL",
"database.port": "1521",
"database.hostname": "10.96.80.21",
"database.password": "dbz",
"name": "hr-connector",
"table.include.list": "hr.test"
}
--查看连接器的状态
[root@node1 ~]# curl -s localhost:8083/connectors/hr-connector/status|jq
{
"name": "hr-connector",
"connector": {
"state": "RUNNING",
"worker_id": "10.96.80.31:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "10.96.80.31:8083"
}
],
"type": "source"
}复制
查看所有的topic
--查看所有topic
[kafka@node1 ~]$ kafka-topics.sh --list --zookeeper 10.96.80.31:2181|jq
ORCL --表结构信息
ORCL.HR.TEST --表数据,全量数据和增量数据(默认)
__consumer_offsets --偏移量
schema-changes.test --历史信息topic,表结构
--查看topic详细信息
[kafka@node1 ~]$kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL.HR.TEST -from-beginning|jq
--默认是执行闪回查询,获取所有数据,所以befor是null,after 是表中的数据,"scn": "4842963"。
"payload": {
"before": null,
"after": {
"JOB_ID": "PR_REP",
"JOB_TITLE": "Public Relations Representative",
"MIN_SALARY": 4500,
"MAX_SALARY": 10500
},
"source": {
"version": "1.7.0.Final",
"connector": "oracle",
"name": "ORCL",
"ts_ms": 1636290152296,
"snapshot": "last",
"db": "PDB1",
"sequence": null,
"schema": "HR",
"table": "TEST",
"txId": null,
"scn": "4842963",--闪回查询指定的scn
"commit_scn": null,
"lcr_position": null
},
"op": "r",
"ts_ms": 1636290152296,
"transaction": null复制
模拟操作,查看消息触发情况
1、dml 操作模拟
可以看到可以触发实时消息
-查看实时消息
[kafka@node1 ~]$ kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL.HR.TEST |jq
"payload": {
"before": {
"JOB_ID": "AC_ACCOUNT",
"JOB_TITLE": "Public Accountant",
"MIN_SALARY": 4200,
"MAX_SALARY": 9000
},
"after": null, --删除之后afer 是null
"source": {
"version": "1.7.0.Final",
"connector": "oracle",
"name": "ORCL",
"ts_ms": 1636320665000,
"snapshot": "false",
"db": "PDB1",
"sequence": null,
"schema": "HR",
"table": "TEST",
"txId": "0800050041020000",
"scn": "4892329",
"commit_scn": "4892347", --提交的scn
"lcr_position": null
},
"op": "d", --删除操作
可以看到
--模拟触发消息
HR@pdb1 09:24:57> delete from test where rownum =1 ;
1 row deleted.
HR@pdb1 09:31:05> commit;
Commit complete.复制
ddl 操作模拟
可以看到 ddl可以正常采集
-模拟ddl操作
HR@pdb1 09:35:41> alter table test add (col varchar2(20)) ;
Table altered.
--查看ORCL topic
[kafka@node1 ~]$kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL -from-beginning|jq
"payload": {
"source": {
"version": "1.7.0.Final",
"connector": "oracle",
"name": "ORCL",
"ts_ms": 1636320952000,
"snapshot": "false",
"db": "PDB1",
"sequence": null,
"schema": "HR",
"table": "TEST",
"txId": "0a001b00c4040000",
"scn": "4893263",
"commit_scn": "4893054",
"lcr_position": null
},
"databaseName": "PDB1",
"schemaName": "HR",
"ddl": "alter table test add (col varchar2(20)) ;"复制
总结
1、 debezium oracle cdc 可以初始化全量数据,闪回查询实现
2、debezium oracle cdc 可以实现增量数据同步
3、debezium oracle cdc 可以实现ddl采集(19C 库)
4、生产环境要部署集群模式,不要采用stanalone模式。
