




写在开头---方便读者测试 每小部分都有代码进行结果测试(节约时间 就不刻意注重排版了喔 废话不多说 进主题)
爬取思路:
1输入的歌手名称-2确定并获取该歌手下全部歌曲id(理想状态下)-3爬取歌曲相关属性信息-4下载
1.输入想要下载歌曲的作者名称 如 薛之谦、许嵩、陈奕迅...由歌手名称确定到该歌手歌曲列表url
2.每首歌曲 都有唯一标识tsid 从上步url源码界面中运用正则表达式爬取歌曲总页码及歌曲tsid
(由总页码通过循环获取到全部歌曲的tsid-这个可以放到实现首页歌曲爬取后再进行)
3.在歌曲播放player页面(随便播放一首歌-f12)分析获取歌曲相关信息json文件
ps: 千千音乐有sign的js加密 此处需要解密sign 进而爬取歌曲相关属性信息
4.下载-视频音频下载用urlretrieve库即可 文件类用with open下载复制
1.根据输入的歌手名称 确定的歌曲列表 2.按F12后如图操作 可以看到歌曲的tsid标识符 即歌曲页码
2.按F12后如图操作 可以看到歌曲的tsid标识符 即歌曲页码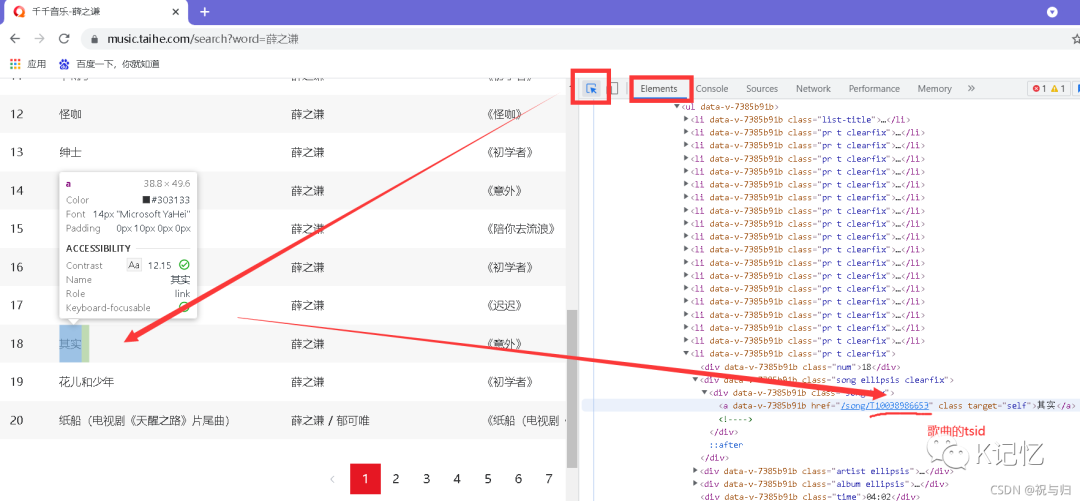
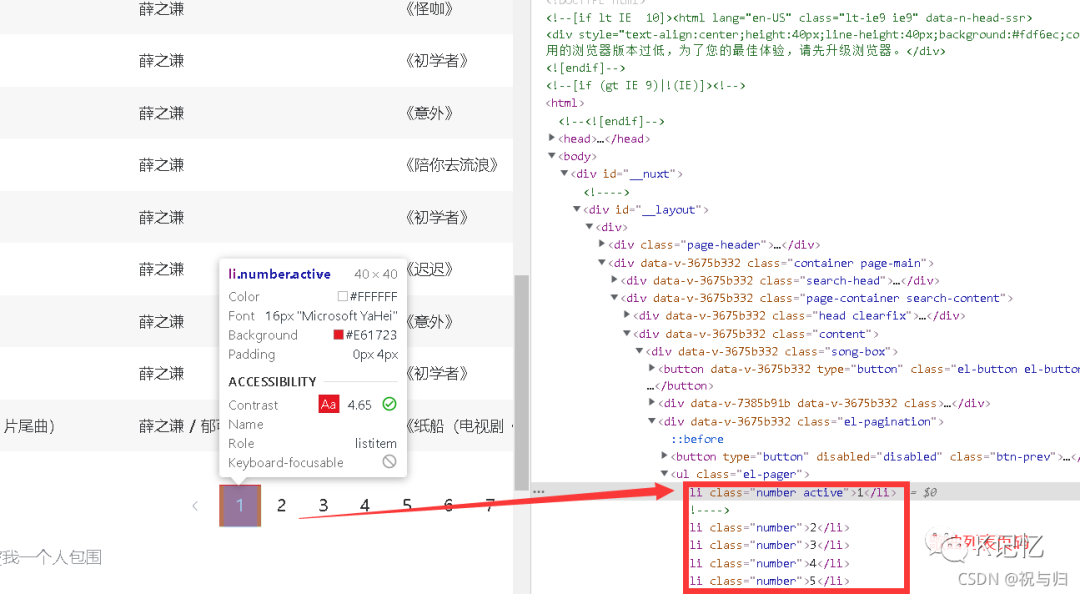 2.1根据上图操作显示 歌曲tsid和页码都是需要获取的 怎么获取?从源码中查看特点获取:在网页随处右击鼠标-查看网页源代码
2.1根据上图操作显示 歌曲tsid和页码都是需要获取的 怎么获取?从源码中查看特点获取:在网页随处右击鼠标-查看网页源代码
 2.2通过正则表达式实现歌曲tsid及页码的获取 记住这个(.*?) 很重要很重要 后面一直在用
2.2通过正则表达式实现歌曲tsid及页码的获取 记住这个(.*?) 很重要很重要 后面一直在用
import requests
import re
keywords = input("请输入歌手姓名:")
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
params = (
('word', keywords),
)
# 参数timeout=5 防止访问超时
response = requests.get('https://music.taihe.com/search', headers=headers, params=params)
# 歌曲页码数
page_NUM = re.findall(r'<li class="number">(.*?)</li>', response.text, re.S)
print(page_NUM)
# 演示获取第一页歌曲tsid
url_fenye = f'https://music.taihe.com/search?word={keywords}&pageNo=1'
response = requests.get(url=url_fenye, headers=headers)
tsids = re.findall(r'<a href="/song/(.*?)"', response.text, re.S)
print(tsids)复制
输出结果: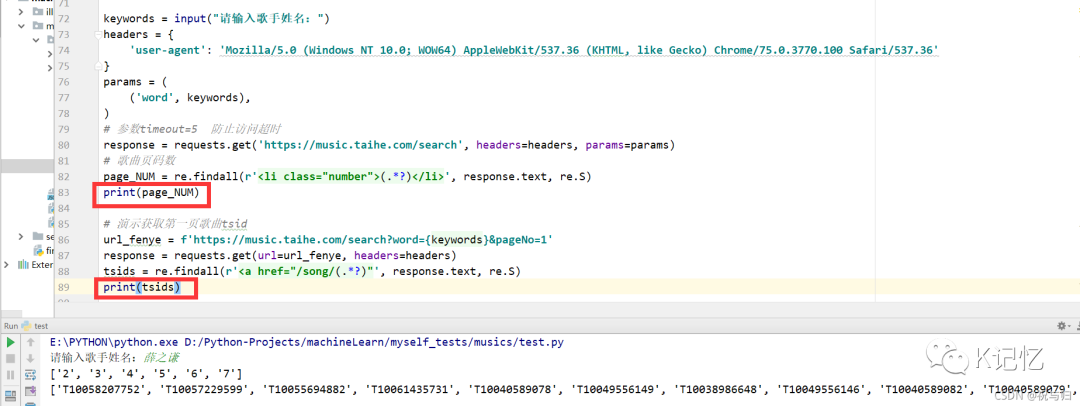 2.3通过分页获取某歌手下所有歌曲tsid
2.3通过分页获取某歌手下所有歌曲tsid
page_NUM = re.findall(r'<li class="number">(.*?)</li>', response.text, re.S)
if len(page_NUM) == 0: # 存在某歌手歌曲过少不足一页的情况
page_num = 1
else:
page_num = int(page_NUM[-1]) # 总页码取最后一位
# 通过翻页获取某歌手所有歌曲id
for i in range(1, page_num + 1):
url_fenye = f'https://music.taihe.com/search?word={keywords}&pageNo={i}'
response = requests.get(url=url_fenye, headers=headers, timeout=5)
tsids = re.findall(r'<a href="/song/(.*?)"', response.text, re.S)复制
输出结果: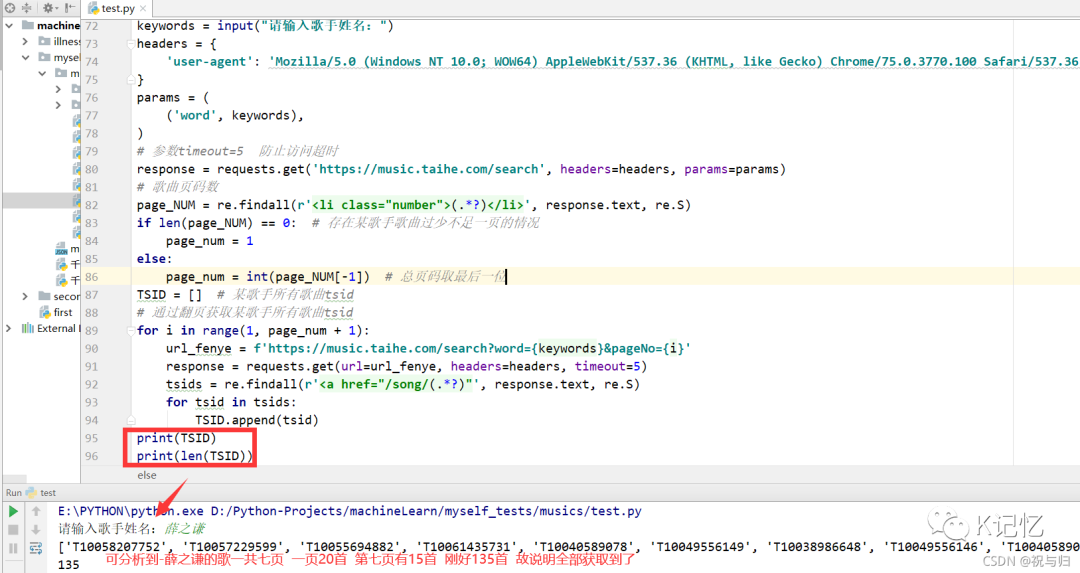 3.获取歌曲相关属性信息 查看 如图操作
3.获取歌曲相关属性信息 查看 如图操作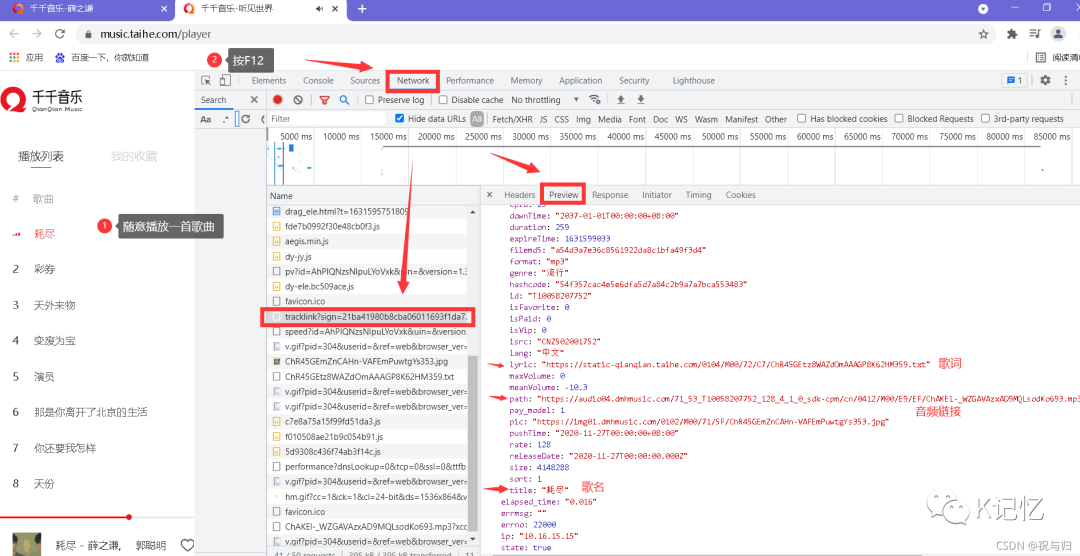 3.1通过json文件实现歌曲相关属性信息的获取
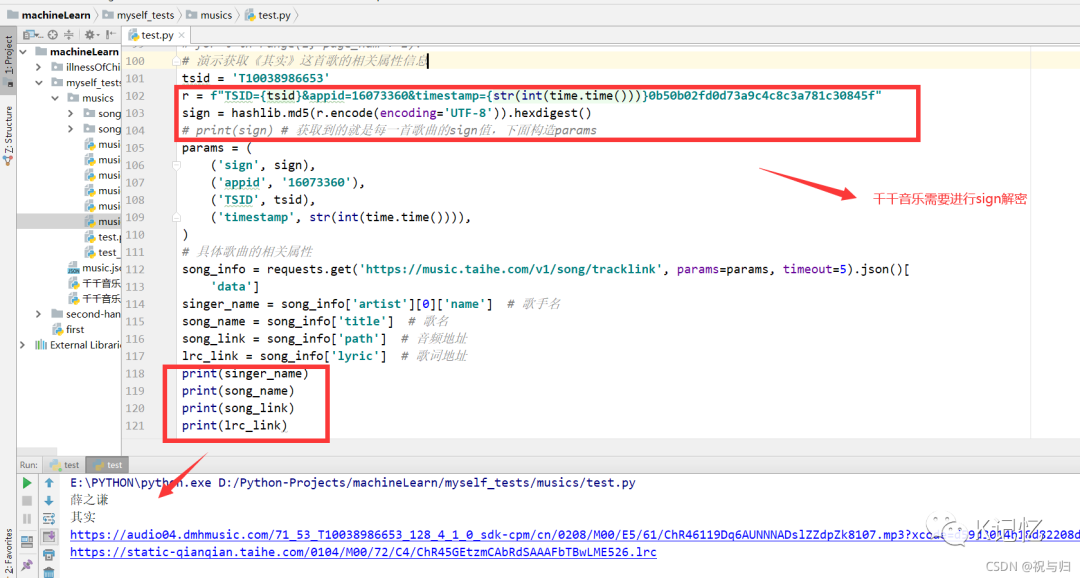
3.1通过json文件实现歌曲相关属性信息的获取
import requests
tsid = 'T10038986653'
r = f"TSID={tsid}&appid=16073360×tamp={str(int(time.time()))}0b50b02fd0d73a9c4c8c3a781c30845f"
sign = hashlib.md5(r.encode(encoding='UTF-8')).hexdigest()
# print(sign) # 获取到的就是每一首歌曲的sign值,下面构造params
params = (
('sign', sign),
('appid', '16073360'),
('TSID', tsid),
('timestamp', str(int(time.time()))),
)
# 具体歌曲的相关属性
song_info = requests.get('https://music.taihe.com/v1/song/tracklink', params=params, timeout=5).json()[
'data']
singer_name = song_info['artist'][0]['name'] # 歌手名
song_name = song_info['title'] # 歌名
song_link = song_info['path'] # 音频地址
lrc_link = song_info['lyric'] # 歌词地址
print(singer_name)
print(song_name)
print(song_link)
print(lrc_link)复制
 补充:千千音乐中的sign的解密过程:
补充:千千音乐中的sign的解密过程: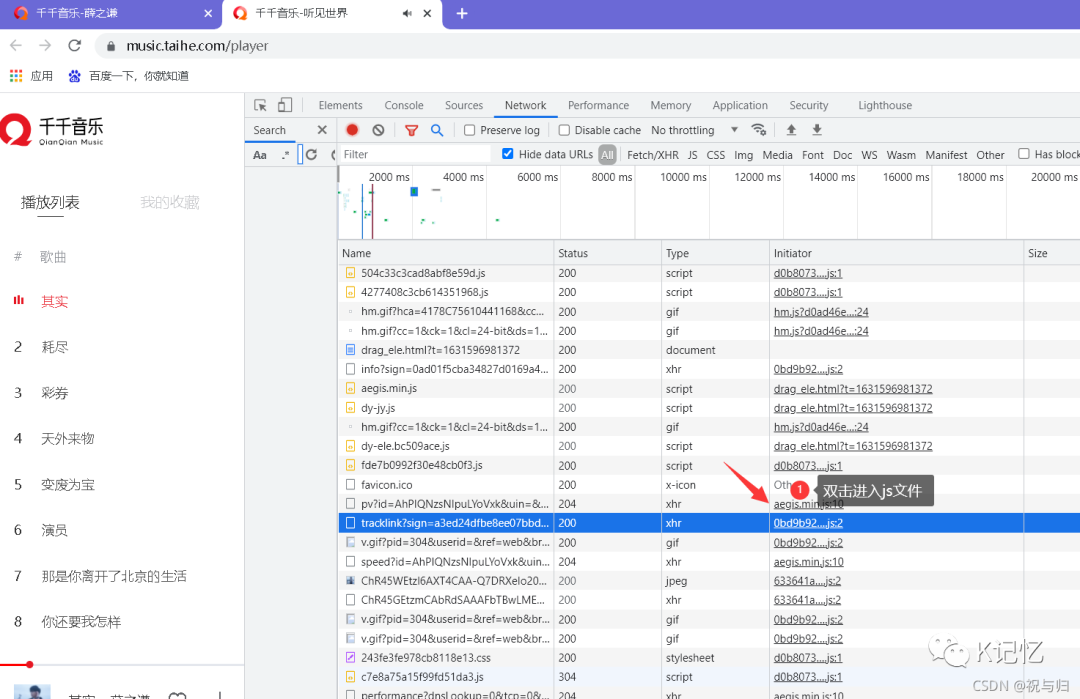
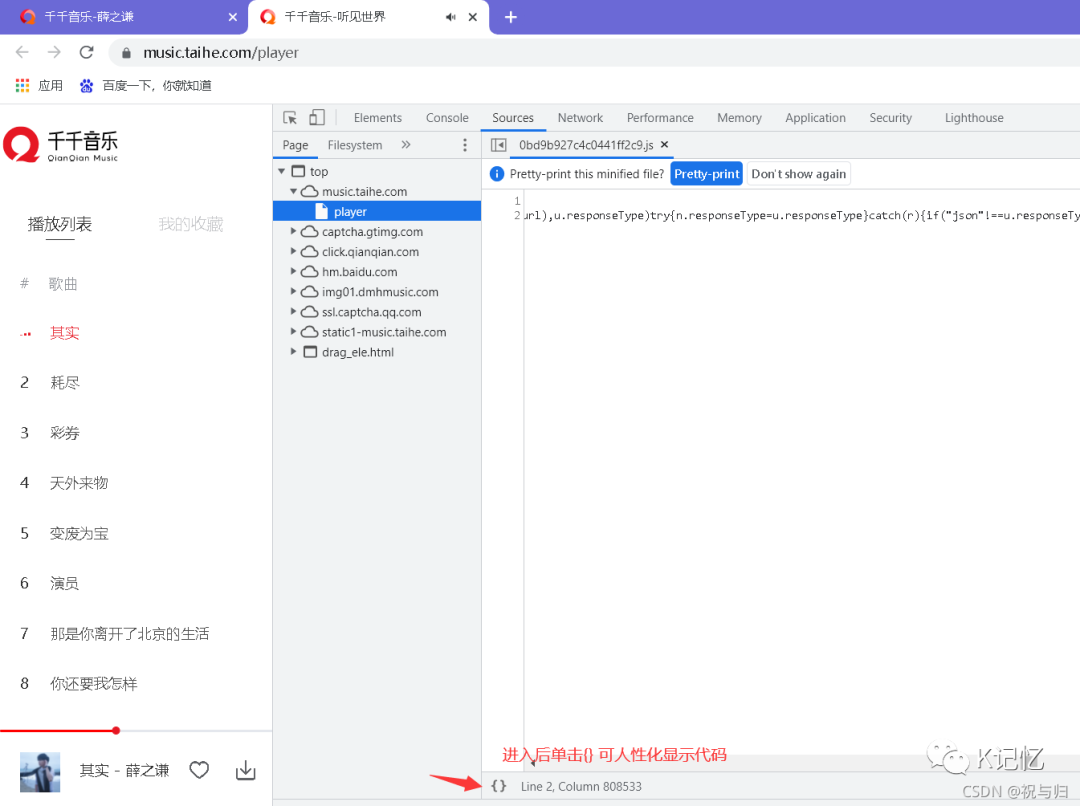
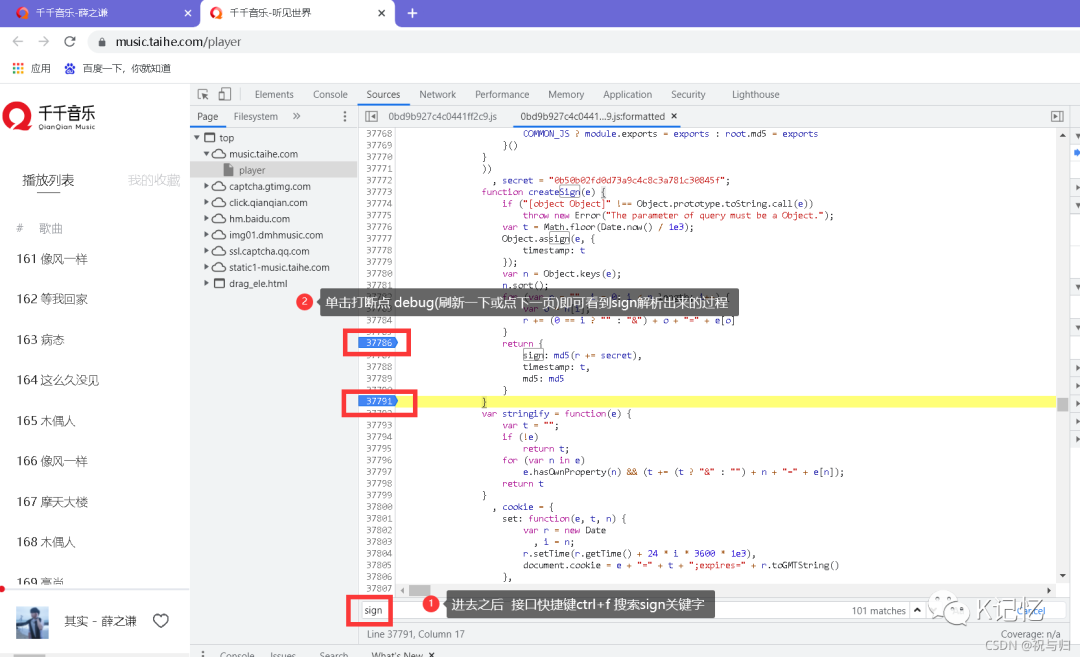 想要深入明白sign解析请参考这位大佬sign分析部分:https://blog.csdn.net/shiguanggege/article/details/119249347?spm=1001.2014.3001.5501
想要深入明白sign解析请参考这位大佬sign分析部分:https://blog.csdn.net/shiguanggege/article/details/119249347?spm=1001.2014.3001.5501
4.在上文基础上进行下载
from urllib.request import urlretrieve
urlretrieve(song_link, song_name + '-' + singer_name + '.mp3') # 下载歌曲复制
输出结果: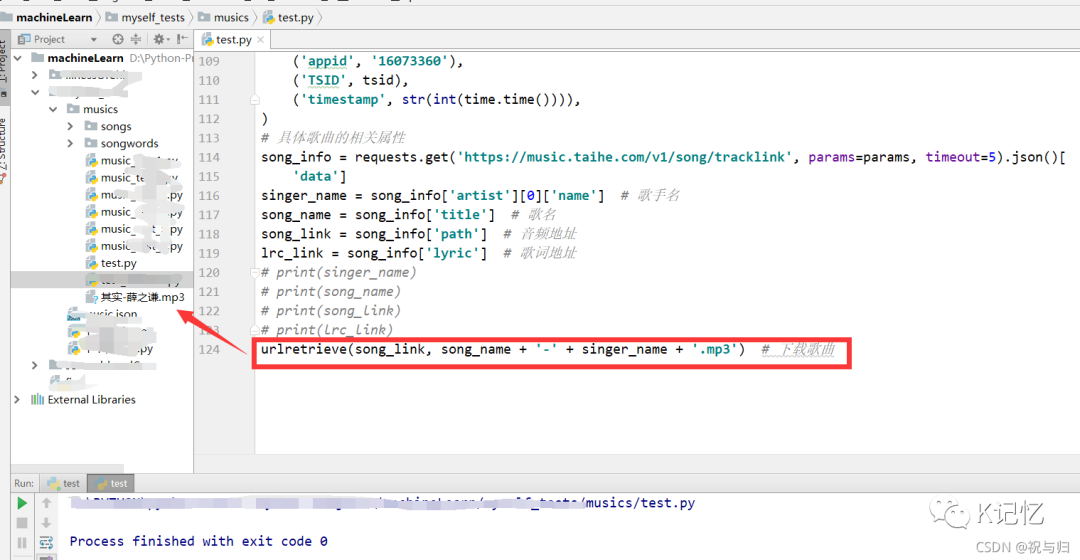 其他补充:(1).*?正则表达式用法:
其他补充:(1).*?正则表达式用法:
需要的数据 就用(.*?)代替 哪里需要就把(.*?)放哪
如源码:<li class="number">1</li> <li class="number">2</li>
page_NUM = re.findall(r'<li class="number">(.*?)</li>', response.text, re.S)
print(page_NUM)----['1', '2']
不需要的数据 要去掉的 忽视掉的 就用.*? 代替 注意没有括号复制
(2)自动化构造头部: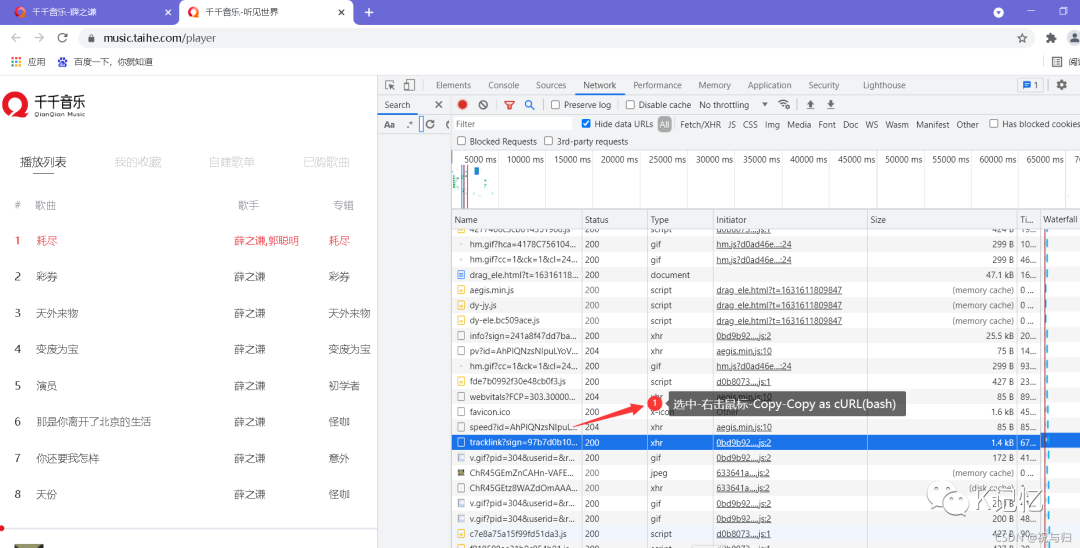 在线curl转代码工具:https://www.toolfk.com/tool-online-curl?share_token=0bc39c74-b970-4cf7-9555-e4b89337f7bf
在线curl转代码工具:https://www.toolfk.com/tool-online-curl?share_token=0bc39c74-b970-4cf7-9555-e4b89337f7bf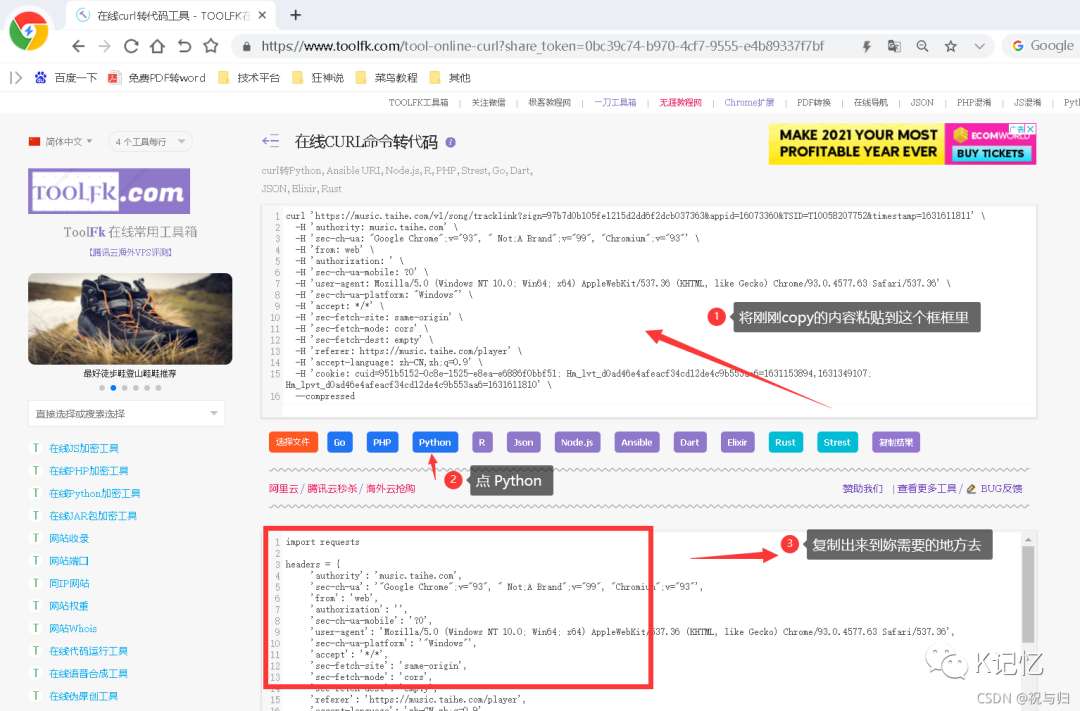
完整源代码:
# encoding:utf-8
"""
@祝与归小天地
time: 2021/9/14 10:37
IDE: PyCharm
content:尝试爬取千千音乐上非VIP歌曲(按歌手名称分类)
ps: 已封装成函数--可以一次性下载某歌手下所有歌曲(是输入歌手名称的)
已避坑:部分歌曲播放链接不存在-判断pass 部分歌曲歌词不存在-判断pass
已删除掉很多注释-纯净版
"""
import requests
import os
import re
import time
import hashlib
from urllib.request import urlretrieve
'''
爬取思路:
由1输入的歌手名称-2确定并获取该歌手下全部歌曲id(理想状态下)-3爬取歌曲相关属性信息-4下载
1.输入想要下载歌曲的作者名称 如 薛之谦、许嵩、陈奕迅...由歌手名称确定到该歌手歌曲列表url
2.每首歌曲 都有唯一标识tsid 从上步url源码界面中运用正则表达式爬取歌曲总页码及歌曲tsid
3.在歌曲播放player页面(随便播放一首歌-f12)分析获取歌曲相关信息json文件
ps: 千千音乐有sign的js加密 此处需要解密sign 进而爬取歌曲相关属性信息
4.下载-视频音频压缩包图片下载用urlretrieve库即可 文件类用with open
'''
# 输入歌手名称
keywords = input("请输入歌手姓名:")
# 成功下载歌曲数
song_number = 0
# 创建存放歌曲/词的文件
filename1 = f'{os.getcwd()}\\songs\\{keywords}\\'
if not os.path.exists(filename1):
os.mkdir(filename1)
filename2 = f'{os.getcwd()}\\songwords\\{keywords}\\'
if not os.path.exists(filename2):
os.mkdir(filename2)
def main():
# 伪装头部
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
params = (
('word', keywords),
)
# 参数timeout=5 防止访问超时
response = requests.get('https://music.taihe.com/search', headers=headers, params=params, timeout=5)
# 歌曲页码数
page_NUM = re.findall(r'<li class="number">(.*?)</li>', response.text, re.S)
if len(page_NUM) == 0: # 存在某歌手歌曲过少不足一页的情况
page_num = 1
else:
page_num = int(page_NUM[-1])
# 通过翻页获取某歌手所有歌曲id
for i in range(1, page_num + 1):
url_fenye = f'https://music.taihe.com/search?word={keywords}&pageNo={i}'
response = requests.get(url=url_fenye, headers=headers, timeout=5)
tsids = re.findall(r'<a href="/song/(.*?)"', response.text, re.S)
set_tsids = list(set(tsids))
set_tsids.sort(key=tsids.index) # set_tsids去重不改变原顺序
# 开始下载歌曲/词
j = 1 # 歌曲数
# 获取每首歌曲的tsid值
for tsid in set_tsids:
# 防止反爬,每隔1秒进行一次
time.sleep(1)
print(f'正在下载第{i}页第{j}首...')
# 从浏览器中js解密sign,采用的是md5加密形式
r = f"TSID={tsid}&appid=16073360×tamp={str(int(time.time()))}0b50b02fd0d73a9c4c8c3a781c30845f"
sign = hashlib.md5(r.encode(encoding='UTF-8')).hexdigest()
# print(sign) # 获取到的就是每一首歌曲的sign值,下面构造params
params = (
('sign', sign),
('appid', '16073360'),
('TSID', tsid),
('timestamp', str(int(time.time()))),
)
# 具体歌曲的相关属性
song_info = requests.get('https://music.taihe.com/v1/song/tracklink', params=params, timeout=5).json()[
'data']
if len(song_info) != 0: # 部分歌曲播放链接不存在导致song_info为空的情况
if 'path' in song_info.keys(): # VIP的歌曲只能部分听取 无意义 不下载
singer_name = song_info['artist'][0]['name'] # 歌手名
song_name = song_info['title'] # 歌名
song_link = song_info['path'] # 音频地址
lrc_link = song_info['lyric'] # 歌词地址
else:
print(f'第{i}页的第{j}首为VI歌曲,无法找到下载链接!') # 可去掉
j += 1
continue
else:
print("该歌曲播放链接不存在!") # 可去掉
pass
# 下载歌曲 f'{song_name}-{singer_name}.mp3'
if not os.path.exists(f'{filename1}{song_name}-{singer_name}.mp3'):
urlretrieve(song_link, f'{filename1}{song_name}-{singer_name}.mp3') # 下载歌曲
print(song_name, '下载完成')
global song_number # 使变量全局化
song_number += 1
else:
print(f"{song_name}已存在,下载失败!")
pass
j += 1
# 下载歌词 f'{song_name}.lrc'
if not os.path.exists(f'{filename2}{song_name}.lrc'):
if lrc_link: # 存在歌词链接即下载
urlretrieve(lrc_link, f'{filename2}{song_name}.lrc') # 下载歌词
else:
pass
print(f'共下载成功{song_number}首歌曲,请查看存放地址{filename1}')
if __name__ == '__main__':
main()
''' 写在最后-存在的问题:
根据输入的歌手名称获取到的歌曲可能并不是歌手本人唱的 只是含有歌手名的歌曲
曲线救国(解决问题):尽量下载在千千音乐上有识别度的歌手-比如薛之谦、许嵩等等
'''复制
下载结果:
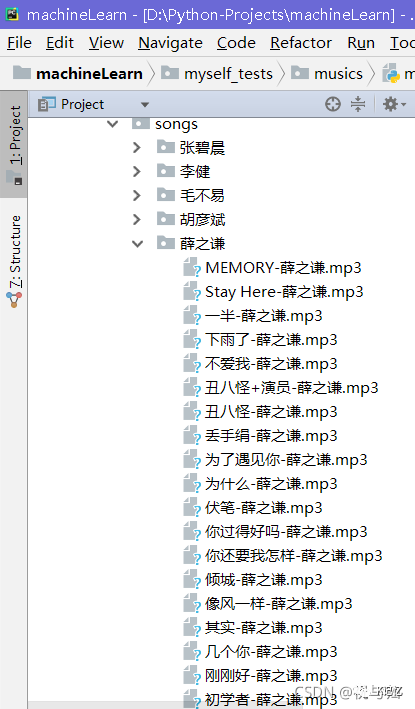
上传到网易云盘(或自己需要的地方)中: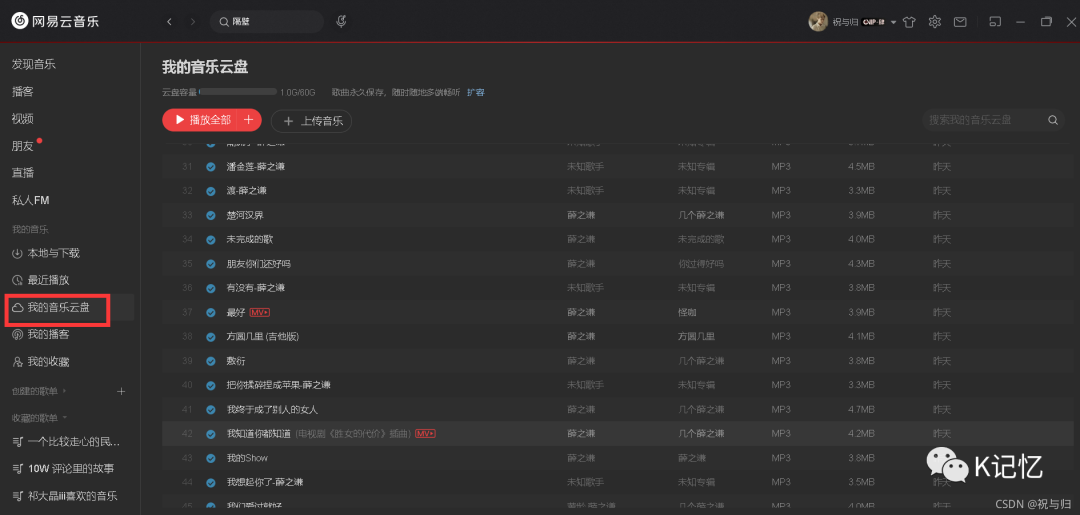 后文:
后文:
好了 差不多记录完了 看着蛮畅通的 其实这中间踩了很多坑的(流泪呜呜呜呜呜呜呜~~~)千千音乐上还是有很多歌手查不到的 不过拿它只是试手 终极目标是爬网易云音乐!!!后续应该还会进一步改善 比如说:播放的同时会显示歌词 也可能会学习PYQTS弄一个可视化下载的界面 学习之路 道阻且长....加油加油
