





从 Amazon EMR 5.32 开始,Amazon EMR 引入了 Apache Ranger 2.0 支持,这让您可以为 Apache Spark、Amazon Simple Storage Service(Amazon S3) 和 Apache Hive 启用授权和审计功能。它还允许在 Amazon CloudWatch 中记录授权审计。但是,尽管您可以使用这些授权功能控制 Apache Spark 向 Amazon S3 的写入操作,但 SparkSQL 支持仅限于读取授权。
我们很高兴地宣布,借助 Amazon EMR 6.4,Apache Ranger SparkSQL 集成能够支持数据操作语句(DML)的授权功能。现在,您可以使用 Apache Ranger 策略,为 SparkSQL 授权 INSERT INTO、INSERT OVERWRITE 和 ALTER 语句。
架构概览
Amazon EMR 使用 Amazon EMR 记录服务器实现了对 Apache SparkSQL 的支持,该服务器会读取 Apache Ranger 策略定义、评估访问权限并筛选数据,然后再将数据传回各个 Spark 执行程序。
下图显示了简要的架构。
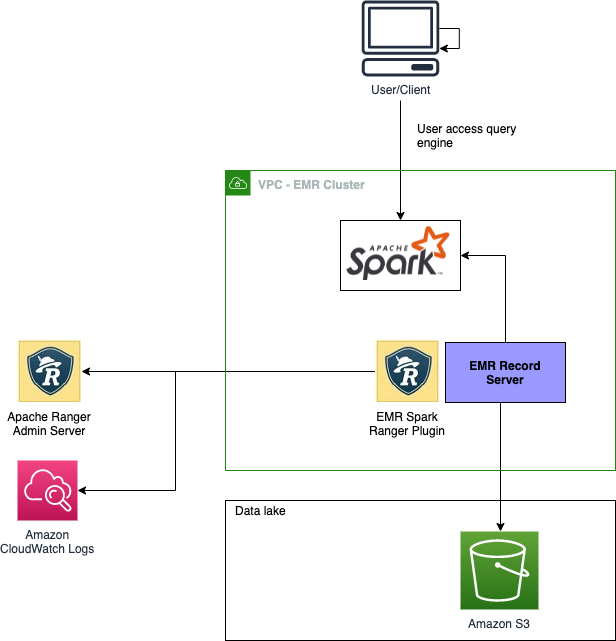
实施细节
在开始之前,请设置您的 Apache Ranger 和 Amazon EMR 集群。有关说明,请参阅 Amazon EMR 与 Apache Ranger 的集成简介。如果您在 Apache Ranger 服务器上的现有安装已经部署了 Apache Spark 服务定义,请使用以下代码重新部署服务定义:
# 获取调用 Ranger REST API 和 JSON 处理程序的现有 Spark 服务定义 ID
curl --silent -f -u <admin_user_login>:<password_for_ranger_admin_user> \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id
# 下载最新的服务定义
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
# 使用 Ranger REST API 更新服务定义
curl -u <admin_user_login>:<password_for_ranger_admin_user> -X PUT -d @ranger-servicedef-amazon-emr-spark.json \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<id-you-got from step1>'
*左右滑动查看更多
现在服务定义已更新,我们可以开始测试策略。
对于我们的使用场景,假设您有一个由外部 Amazon S3 支持的分区 Hive 表。您想要使用 SparkSQL DML 语句将数据插入到表中。
使用以下代码来定义表:
CREATE EXTERNAL TABLE IF NOT EXISTS students_s3 (name VARCHAR(64), address VARCHAR(64))
PARTITIONED BY (student_id INT)
STORED AS PARQUET
LOCATION 's3://xxxxxx/students_s3/'
*左右滑动查看更多
现在,您可以在 Apache Ranger 上设置授权策略。以下屏幕截图说明了此过程。
因为表由 Amazon S3 在外部提供支持,我们首先需要启用针对表的 Amazon S3 位置的读写访问权限。如果该位置位于 HDFS 上,则 URL 应具有 HDFS 路径,例如 hdfs://xxxx。
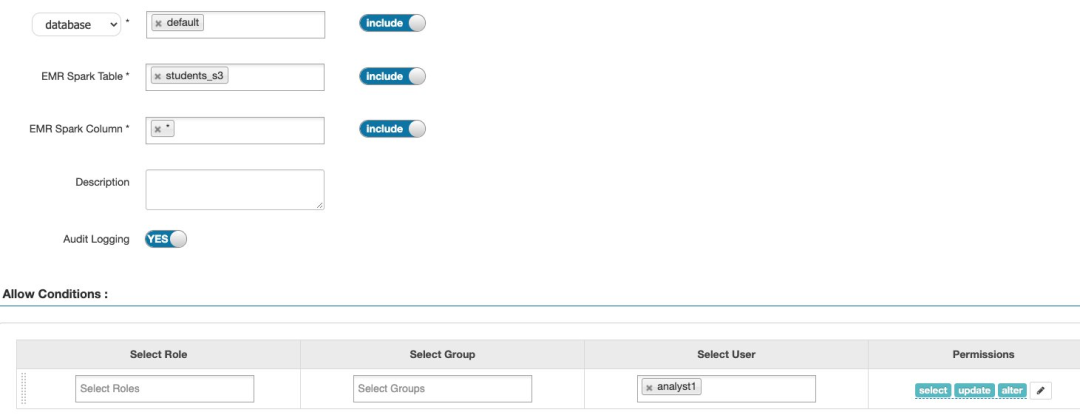
接下来,我们添加 SELECT、UPDATE 和 ALTER 权限,以允许用户使用 DML 命令。对表元数据(如统计数据或分区信息)的任何更新都需要 ALTER 权限。
设置了这些 Apache Ranger 策略之后,我们就可以开始测试 DML 语句。下面是 INSERT INTO 语句的代码示例:
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
spark.sql("INSERT INTO students_s3 VALUES ('Amy Smith', '123 Park Ave, San Jose', 231111)")
studentsSQL = spark.sql("select * from default.students_s3 where student_id=231111")
studentsSQL.show()
*左右滑动查看更多
以下屏幕截图显示了结果。
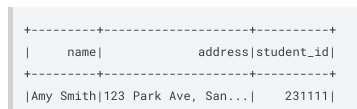
与其他操作类似,我们可以在Amazon CloudWatch 上审计此操作。

限制
对于分区位置不同于表位置的分区,当前不支持在其中插入数据。分区位置必须始终是主表位置的子目录。
现已推出
| 美国东部(俄亥俄) | 美国东部(弗吉尼亚北部) |
| 美国西部(加利福尼亚北部) | 美国西部(俄勒冈) |
| 非洲(开普敦) | 亚太地区(香港) |
| 亚太地区(孟买) | 亚太地区(首尔) |
| 亚太地区(新加坡) | 亚太地区(悉尼) |
| 加拿大(中部) | 欧洲(法兰克福) |
| 欧洲(爱尔兰) | 欧洲(伦敦) |
| 欧洲(巴黎) | 欧洲(米兰) |
| 欧洲(斯德哥尔摩) | 南美洲(圣保罗) |
| 中东(巴林) |
有关最新可用区域的信息,请参阅 Amazon EMR 管理指南
结论
Amazon EMR 6.4 为 Apache Ranger 2.0 的数据操作语句引入了额外的授权功能。您可以在 SparkSQL 中使用 INSERT INTO、INSERT OVERWRITE 和 ALTER 等语句,并使用 Apache Ranger 策略控制授权。
相关资源
有关其他信息,请参阅以下资源:
· Amazon EMR 与 Apache Ranger 的集成简介
· 将 Amazon EMR 与 Apache Ranger 集成
· Amazon EMR 6.3 现在支持 Apache Ranger 进行细粒度的数据访问控制
· 在 Amazon EMR 上使用 Apache Ranger 实施授权和审计
本篇作者

Varun Rao Bhamidimarri
亚马逊云科技分析专家解决方案构架师团队的高级经理
工作重点是帮助客户采用支持云的分析解决方案,以满足客户业务需求。在工作之外,他喜欢与妻子和两个孩子共度欢乐时光,享受健康的生活方式,进行冥想,最近在疫情封城期间开始从事园艺活动。

Jalpan Randeri
亚马逊云科技的高级软件工程师
对于大数据系统的性能优化和数据访问控制工作,他乐此不疲。在工作之余,他喜欢看动漫和玩电子游戏。

听说,点完下面4个按钮
就不会碰到bug了!
