




ClickHouse是“战斗民族”俄罗斯搜索巨头Yandex公司开源的一个极具“战斗力”的实时数据分析数据库,是面向OLAP的分布式列式DBMS,圈内人戏称为“喀秋莎数据库”。ClickHouse简称"CH",但在中文社区里大家更偏爱"CK",反馈是因为有"AK"的感觉!与Hadoop、Spark这些巨无霸组件相比,ClickHouse很轻量级,其特点:列式存储数据库,数据压缩;关系型、支持SQL;分布式并行计算,把单机性能压榨到极限;高可用;数据量级在PB级别。——这段话引用自一篇公众号文章《百分点大数据技术团队:ClickHouse国家级项目最佳实践》,文章地址:https://mp.weixin.qq.com/s/9S6DhDhv7lFbMaFScf137Q。
下面的内容我就把ClickHouse简称为"CK",官方的"C"和"H"字母是大写,对于有中度强迫症的我来说,简称为"CH"更符合我的胃口,但是为了方便大家区分和易读,所以就委曲求全简称为CK吧,ZooKeeper就简称为ZK。
约定好简称,下面就开始今天的内容吧。
01
环境准备与规划.
服务器配置及软件版本
| 属性 | 详情 |
|---|---|
| 服务器配置 | 基于OpenStack私有云:40C/128G/5T*4台 |
| 操作系统版本 | CentOS Linux release 7.5.1804 (Core) |
| Linux内核版本 | 3.10.0-862.el7.x86_64 |
| ZooKeeper版本 | 3.7.0 |
| ClickHouse版本 | 21.9.5.16-stable |
ZooKeeper路径、端口规划
| 名称 | 详情 |
|---|---|
| 软件安装目录 | /usr/local/zookeeper |
| 数据目录 | /usr/local/zookeeper/data |
| 日志目录 | /usr/local/zookeeper/log |
| 配置文件目录 | /usr/local/zookeeper/conf/zoo.cfg |
| 端口&MyID | 2182(对外)、2999丨3999(内部)、1丨2丨3(3节点myid) |
ClickHouse路径、端口规划
| 名称 | 详情 |
|---|---|
| CK服务端 | /usr/bin/clickhouse-server |
| CK客户端 | /usr/bin/clickhouse-client |
| 数据目录 | /data/clickhouse-server/data |
| 日志目录 | /data/clickhouse-server/logs |
| 配置文件目录 | /etc/clickhouse-server |
| HTTP PORT | 8123 |
| TCP PORT | 9000 |
| INTERSERVER HTTP PORT | 9009 |
相关服务器、软件目录、版本、端口都已规划好,下面开始部署。
02
ZooKeeper安装部署.
编写安装ZK的Ansible脚本
01
定义机器列表文件
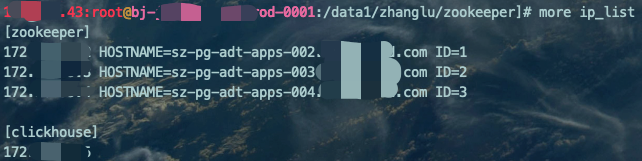
在堡垒机上定义一个ip_list文件,内容为要部署的目标机器的IP、主机名、MyID。
mkdir zookeepercd zookeepervim ip_list[zookeeper]172.xx.xx.x HOSTNAME=sz-pg-adt-apps-002.xxxxxx.com ID=1172.xx.xx.x HOSTNAME=sz-pg-adt-apps-003.xxxxxx.com ID=2172.xx.xx.x HOSTNAME=sz-pg-adt-apps-004.xxxxxx.com ID=3[clickhouse]172.xx.xx.x
02
定义参数文件模板
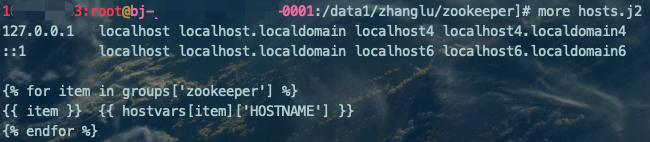
ZK安装过程,我们需要将所有的节点信息(IP地址、主机名)添加至每个节点/etc/hosts文件中,所以需要定义一个参数文件模板。
vim hosts.j2127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6{% for item in groups['zookeeper'] %}{{ item }} {{ hostvars[item]['HOSTNAME'] }}{% endfor %}
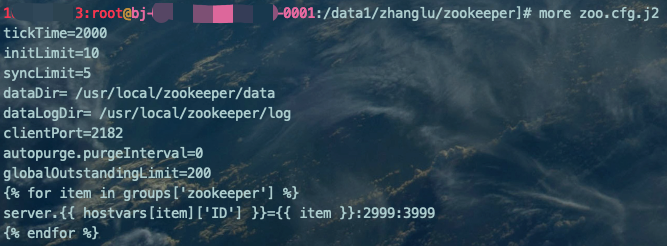
vim zoo.cfg.j2tickTime=2000initLimit=10syncLimit=5dataDir= /usr/local/zookeeper/datadataLogDir= /usr/local/zookeeper/logclientPort=2182autopurge.purgeInterval=0globalOutstandingLimit=200{% for item in groups['zookeeper'] %}server.{{ hostvars[item]['ID'] }}={{ item }}:2999:3999{% endfor %}
03
Ansible主入口文件
Ansible最核心的文件,定义安装整个流程,因为我们推出的环境会默认安装hadoop用户,所以指定用户时会指定该用户,大家因各自环境而异。
vim deploy.zookeeper.yaml---- hosts: zookeeper remote_user: root gather_facts: true # 定义ZK相关变量 vars: zookeeper_version: apache-zookeeper-3.7.0-bin.tar.gz zookeeper_dir: apache-zookeeper-3.7.0-bin # 开始定义任务 tasks: # 1、修改所有节点/etc/hosts文件 - name: "1 | update the /etc/hosts" template: src: ./hosts.j2 dest: /etc/hosts # 2、创建ZK安装目录,并赋予相关用户权限 - name: "2 | create the work_dir" file: path: /usr/local/zookeeper state: directory owner: hadoop group: hadoop mode: 0755 # 3、从HTTP服务器下载安装包并解压 - name: "3 | download and unpack the zookeeper package" unarchive: src: http://10.xx.x.xx/td-configuration/deploy/clickhouse/{{ zookeeper_version }} dest: /tmp/ remote_src: yes owner: hadoop group: hadoop # 4、 判断解压后的目录中是否有bin目录,有则为true - name: "4 | stat /tmp/{{zookeeper_dir}}/bin" stat: path: /tmp/{{zookeeper_dir}}/bin register: zookeeper_stat # 5、再次判断目标端目录中是否有bin目录,无则为false - name: "5 | stat /usr/local/zookeeper/bin" stat: path: /usr/local/zookeeper/bin register: bin_stat # 6、判断解压目录、移动目标目录,如果有解压目录且目标目录没有bin目录,可以执行移动目录操作(即第4步为true,第5步为false执行移动操作) - name: "6 | move directory |" shell: mv /tmp/{{zookeeper_dir}}/* /usr/local/zookeeper/ args: executable: /bin/bash # 条件判断通过后执行移动目录操作 when: - zookeeper_stat.stat.exists - not bin_stat.stat.exists # 7、设置ZK配置文件 - name: "7 | update the /usr/local/zookeeper/conf/zoo.cfg" template: src: ./zoo.cfg.j2 dest: /usr/local/zookeeper/conf/zoo.cfg owner: hadoop group: hadoop mode: 0644 # 8、创建ZK数据、日志目录并赋予用户权限 - name: "8 | create the other directories" file: path: /usr/loacl/zookeeper/{{ item }} state: directory owner: hadoop group: hadoop mode: 0755 with_items: - 'data' - 'log' # 9、创建各个节点myid文件 - name: "9 | create the myid" lineinfile: path: /usr/local/zookeeper/data/myid state: present create: yes # 获取ip_list中定义的ID变量值,实现赋值 regexp: '^\s*{{ ID }}' line: "{{ ID |string }}" # 10、设置ZK环境变量 - name: "10 | env" lineinfile: path: /etc/profile state: present regexp: '{{ item.S }}' line: "{{ item.D }}" with_items: - { S: '^\s*export\s+ZK_HOME=.*',D: 'export ZK_HOME=/usr/local/zookeeper' } - { S: '^\s*export\s+PATH=.*ZK_HOME.*',D: 'export PATH=$PATH:$ZK_HOME/bin' } # 11、再次递归相应目录用户权限 - name: "11 | chown" file: path: /usr/local/zookeeper owner: hadoop group: hadoop recurse: yes # 12、启动ZK服务 - name: "12 | start service" shell: | source /etc/profile /usr/local/zookeeper/bin/zkServer.sh start ignore_errors: yes
Ansible执行安装
ansible-playbook -i ip_list deploy.zookeeper.yaml
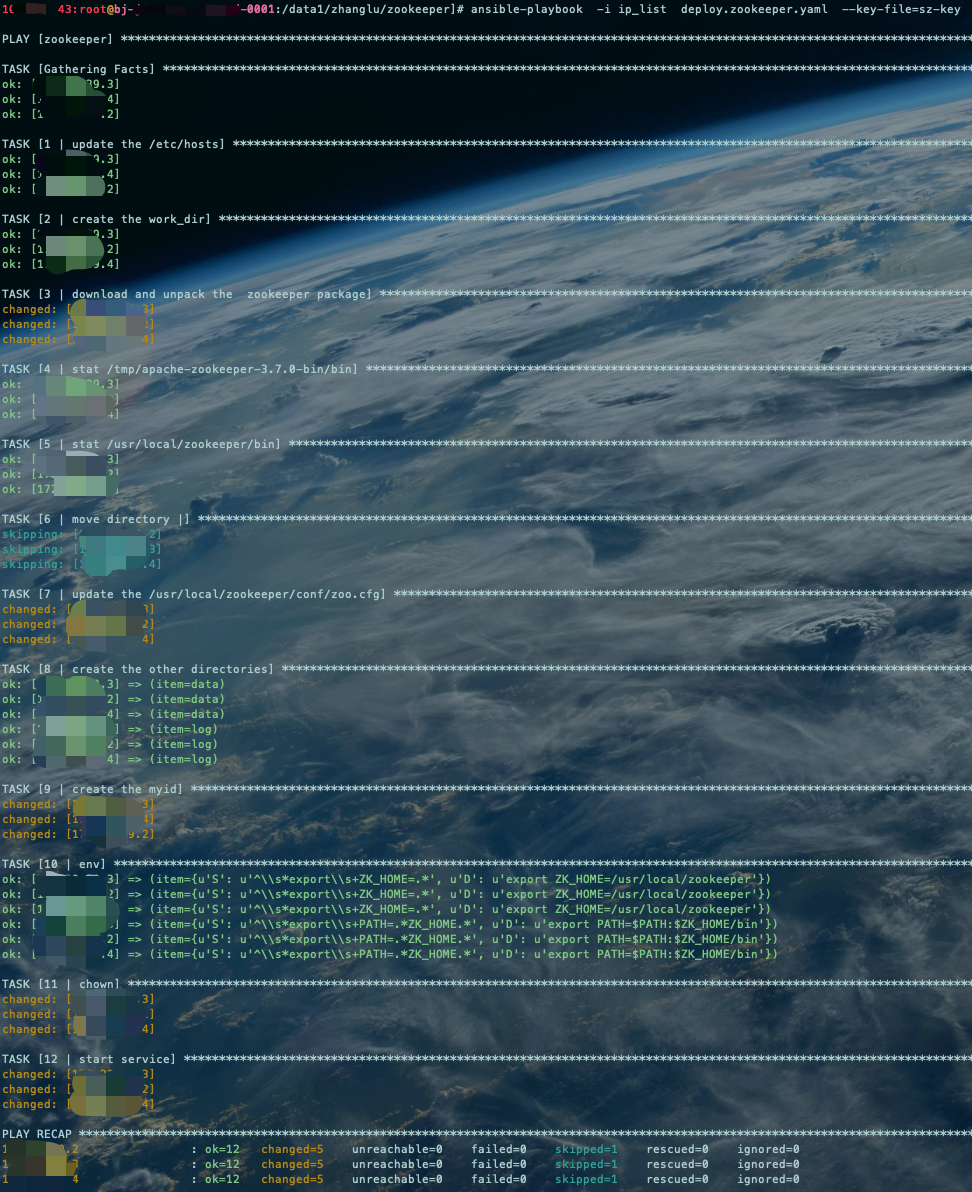
ansible-playbook -i ip_list deploy.zookeeper.yaml --key-file=sz-key
03
ClickHouse安装部署.
编写安装CK的Ansible脚本
01
定义机器列表文件
在堡垒机上定义一个ip_list文件,内容为要部署的目标机器的IP。
mkdir clickhousecd clickhousevim ip_list[clickhouse]172.xx.xx.x172.xx.xx.x172.xx.xx.x172.xx.xx.x
02
Ansible主入口文件
vim deploy.clickhouse.yaml---- hosts: clickhouse remote_user: root gather_facts: true tasks: # 1、下载相关安装包并安装 - name: "1 | download and installed" yum: name: - http://10.xx.x.xx/td-configuration/deploy/clickhouse/v21.9.5.16-stable/clickhouse-common-static-21.9.5.16-2.x86_64.rpm - http://10.xx.x.xx/td-configuration/deploy/clickhouse/v21.9.5.16-stable/clickhouse-common-static-dbg-21.9.5.16-2.x86_64.rpm - http://10.xx.x.xx/td-configuration/deploy/clickhouse/v21.9.5.16-stable/clickhouse-server-21.9.5.16-2.noarch.rpm - http://10.xx.x.xx/td-configuration/deploy/clickhouse/v21.9.5.16-stable/clickhouse-client-21.9.5.16-2.noarch.rpm state: present # 2、创建CK相关目录 - name: "2 | create directories" file: path: /data/clickhouse-server/{{ item }} state: directory with_items: - 'access' - 'data' - 'format_schemas' - 'logs' - 'tmp' - 'user_files' # 3、CK目录赋予对应用户权限 - name: "3 | chown" file: path: /data/clickhouse-server owner: clickhouse group: clickhouse recurse: yes
Ansible执行安装
ansible-playbook -i ip_list deploy.clickhouse.yaml --key-file=sz-key
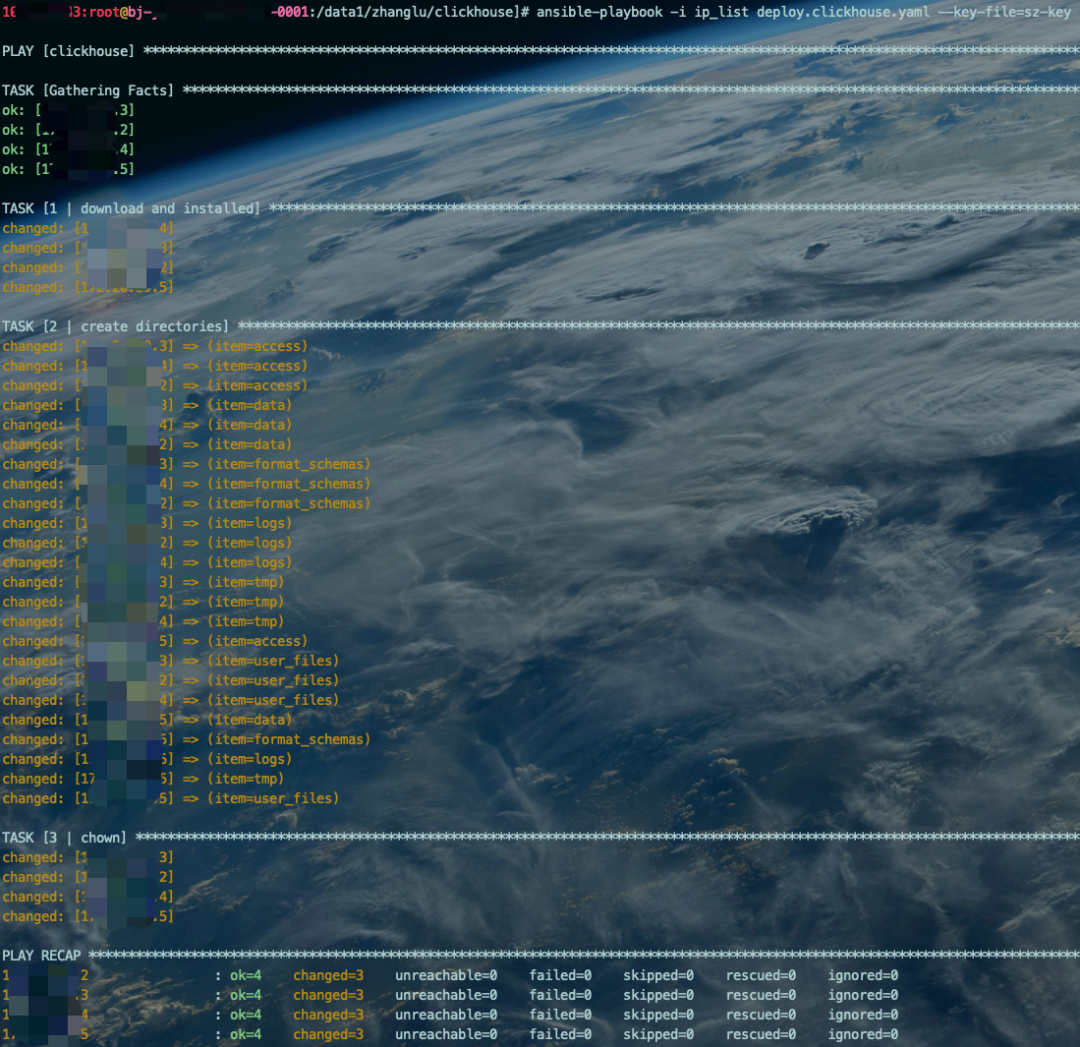
至此,CK安装完成。
修改CK配置文件
因为CK的配置文件内容较多,所以,只将需要调整的部分展示出来。
CK主配置文件:/etc/clickhouse-server/config.xml
vim /etc/clickhouse-server/config.xml<!-- 日志目录 --><log>/data/clickhouse-server/logs/clickhouse-server.log</log><errorlog>/data/clickhouse-server/logs/clickhouse-server.err.log</errorlog><!-- CK内部HTTP通信HOST,填写本机IP,每个节点都不一样 --><interserver_http_host>172.xx.xx.x</interserver_http_host><!-- 监听HOST --><listen_host>0.0.0.0</listen_host><!-- 软件的目录配置,同Ansible安装创建的目录 --><path>/data/clickhouse-server/data/</path><tmp_path>/data/clickhouse-server/tmp/</tmp_path><user_files_path>/data/clickhouse-server/user_files/</user_files_path><local_directory><path>/data/clickhouse-server/access/</path></local_directory><format_schema_path>/data/clickhouse-server/format_schemas/</format_schema_path><!-- 指定ZK配置 --><zookeeper incl="zookeeper-servers" optional="true" /><!-- 指定外部CK集群配置文件 --><include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
引用到外部的集群相关配置文件:/etc/clickhouse-server/config.d/metrika.xml
vim /etc/clickhouse-server/config.d/metrika.xml<?xml version="1.0"?><yandex><!--zookeeper相关配置--> <zookeeper-servers> <!--需要与config.xml中zookerper的incl名称匹配--> <node index="1"> <!--node节点配置--> <host>172.xx.xx.x</host> <!--zk_host--> <port>2182</port> <!--zk_port--> </node> <node index="2"> <host>172.xx.xx.x</host> <port>2182</port> </node> <node index="3"> <host>172.xx.xx.x</host> <port>2182</port> </node> </zookeeper-servers> <remote_servers> <!-- 集群名称 --> <test_cluster> <!-- 集群第1个分片 --> <shard> <internal_replication>true</internal_replication> <!-- 集群第1个分片的第1个副本 --> <replica> <host>172.xx.xx.x</host> <port>9000</port> </replica> <!-- 集群第1个分片的第2个副本 --> <replica> <host>172.xx.xx.x</host> <port>9000</port> </replica> </shard> <!-- 集群第2个分片 --> <shard> <internal_replication>true</internal_replication> <!-- 集群第2个分片的第1个副本 --> <replica> <host>172.xx.xx.x</host> <port>9000</port> </replica> <!-- 集群第2个分片的第2个副本 --> <replica> <host>172.xx.xx.x</host> <port>9000</port> </replica> </shard> </test_cluster> </remote_servers> <macros> <layer>01</layer> <!-- 集群标识 --> <shard>01</shard> <!-- 分片标识:不同机器放的分片数不一样 --> <replica>rep_1_1</replica> <!-- 副本标识:不同机器放的副本数不一样 --> </macros></yandex>
CK集群主配置文件/etc/clickhouse-server/config.xml配置项:<interserver_http_host>172.xx.xx.x</interserver_http_host>,需要填写每个节点自己的IP; 引用到外部的集群相关配置文件/etc/clickhouse-server/config.d/metrika.xml配置项:<macros>...</macros>,每个节点需要填写自己在当前集群的信息,比如第3个节点,应该配置成<layer>01</layer>(集群标识为01)、<shard>02</shard>(所处在第2个分片)、<replica>rep_2_1</replica>(副本的名称格式为:rep_[分片号]_[副本号])。
启动CK服务并检查集群情况
CK集群的启动需要所有节点都操作:
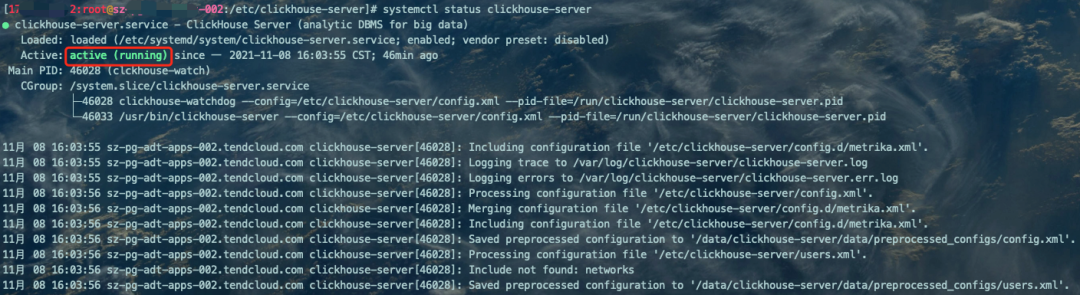
# 启动服务,所有节点都需要执行systemctl start clickhouse-server# 查看CK服务状态systemctl status clickhouse-server
# 登录SQL对话框clickhouse-client -m# 查看当前集群状态SELECT * FROM system.clusters;# 查看ZK信息SELECT * FROM system.zookeeper where path='/clickhouse';
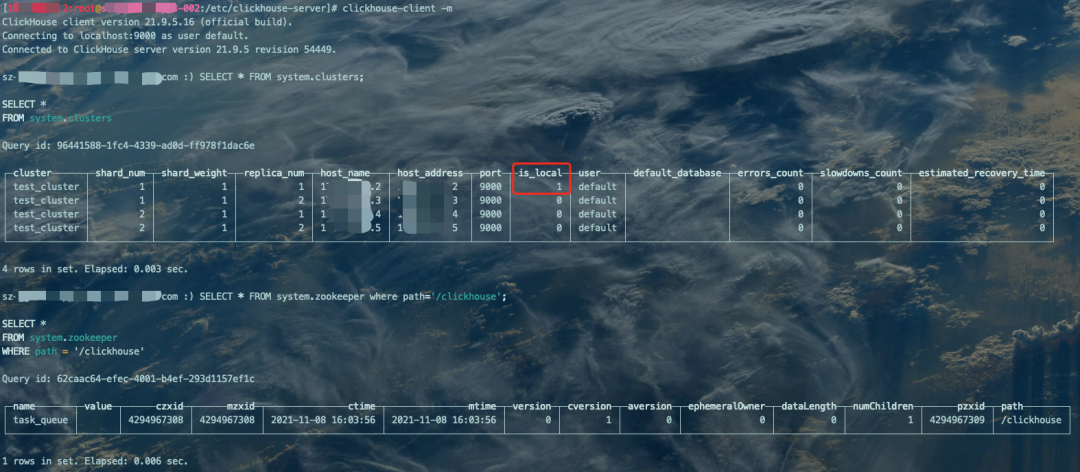
CK支持SQL,clickhouse-client命令后面可以跟很多参数,例子中的-m参数:代表多行输入,最后要以';'为结束符才算完整的一个SQL、--host:指定主机名、--port:指定端口等,其实你会发现,和MySQL客户端mysql参数类似。
CK中有一个system系统库,也可以使用use system;的语句切换到该库下,show tables;命令可以看到里面的各个元数据表,这些表记录着CK集群的各种状态。
在修改配置文件的时候一定要仔细,认真区分好集群、分片、副本的关系。我刚开始学习的时候也很乱,不过,书读百遍其义自见。

04
小结.
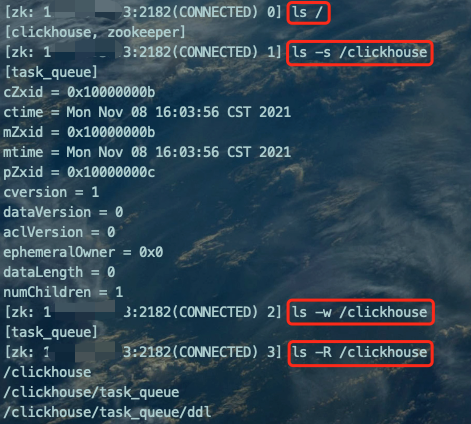
zkCli.sh -server 172.xx.xx.x:2182ls /ls -s /clickhousels -w /clickhousels -R /clickhouse

end
