点击蓝字 关注我们
Cassandra 4.0的目标就是成为史上最稳定的版本。为了达到这个目的,社区用了很多方法和工具进行测试。
在本次活动中,来自DataStax的工程总监曹海荣为大家介绍了Cassandra 4.0的测试思路。
点击文末“阅读原文”查看活动录像,获取更多技术细节。
01
Cassandra数据库准确性测试架构
对于数据库来讲,最最重要的就是准确性——你不希望你的数据在存储的过程中被修改或丢失。所以,数据的准确性是4.0版本中最关注的地方。
简单来讲,在通常情况下,在测试时会有一个运行着Cassandra集群的生产环境。在这里,我们的核心方式是利用开源的Cassandra-diff工具来测试源集群和目标集群里面的数据。
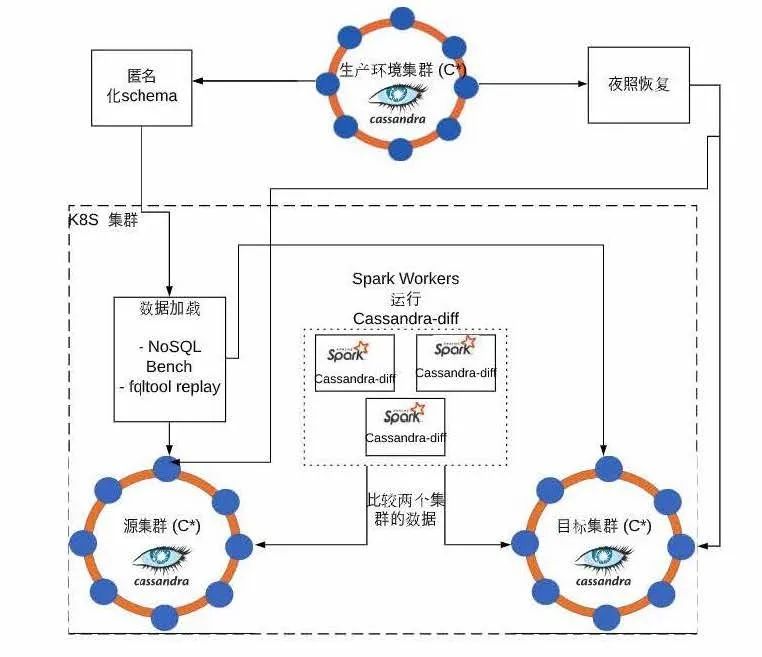
首先,测试架构中包括了夜照恢复,这个功能能够把想要测试的某个数据点在生产环境中恢复到测试环境中的源集群和目标集群。
第二,如果不希望别人知道schema的情况,我们有一个匿名化的工具帮助隐藏schema,这样其他做测试的人就看不出来可能包含的敏感的信息,比如客户数据等。
第三步就是将不同的数据加载到源集群或目标集群。在加载过程中我们会使用到一些工具,主要包括NoSQLBench和fqltool。fqltool是一个full query log,会存储所有通过CQL interface的query,之后可以再进行回放。在后面我会再具体介绍这两种工具。
在Cassandra-diff运行中,有时数据量会非常大,这里我们就用到了Spark。以Spark集群的形式,我们将Cassandra程序运行在Spark Workers上,然后再由Spark Workers运行Cassandra-diff来确保源集群和目标集群中的数据是准确的。
在实际应用时,夜照恢复可能是可选项,如果只是测试则完全不必要。匿名化Schema则取决于是否有生产环境,也不一定绝对需要。所以整个测试架构中的核心就是数据加载和Cassandra-diff。
整个测试环境可以运行在一般的服务器环境之下,也可以运行在Kubernetes集群中。我们现在正在努力实现这些工具的自动化,将他们放到Kubernetes集群中,使得所有社区成员都可以使用。
接下来,我会就其中几个重要的工具进行介绍。
02
匿名化schema

其实匿名化schema的概念非常简单。
在上面的PPT中,源schema的keyspace的名字是cassandradiff,匿名化后变为ks_0,使得测试人员完全无法辨认原来的keyspace名字。
除此之外,包括数据库的名字、表的名字等等都被匿名化了。这样一来,我们就可以放心地将数据导出并用来测试。
03
加载数据
加载数据主要用到两种工具,其中一个是NoSQLBench。
NoSQLBench本来是一个用来做性能测试的工具,我们用它来加载数据的原因是它是决定性的(deterministic),即当开发人员配置好相关的配置文件,NoSQLBench能确保多次生成的数据是一致的,方便测试比较。
另外一个使用NoSQLBench的原因是它可以基于匿名schema随机生成数据。
阅读《技术基础 | NoSQLBench入门教程》了解关于NoSQLBench的更多细节。
第二种加载数据的方式是FQL(Full Query Log,所有查询日志)。
FQL是Cassandra 4.0中的新功能,它会记录所有从CQL interface输入的命令。通常情况下,FQL是用来做调试和性能测试的。而4.0中的另一个亮点功能审核日志Audit log就是基于FQL开发的。
阅读《活动精彩实录 | Cassandra 4.0新特性介绍》了解更多关于审核日志的细节。
FQL只会记录成功的命令,不成功的命令不会被记录。另外,FQL的运行对于集群性能的影响非常小,主要是因为FQL使用了非常简单且性能很好的BinLog格式和高性能的Chronicle Queue。
在以前,出现问题时我们需要模拟用户的使用过程,但是想要快速有效地复制之前的情况是一件很难的事情,因为每个运行环境和每个客户的使用方法都有不同。而FQL相当于做了一个完整的记录,当我们再遇到问题,就可以用replay功能来进行诊断和修复。
在4.0版本中,我们就可以使用fqltool这一工具来操作FQL。当我们使用replay功能时,我们可以指定想要replay的数据库或表,得到的结果会被存储到指定的路径、集群或者节点。
04
Cassandra-diff
我们通过NoSQLBench或是FQL将数据加载到两个不同集群里面之后,有可能这两个集群的Cassandra版本不同,也可能配置不同。
在Cassandra的yaml文件中有很多配置,我们曾经做过调研,如果将yaml文件中不同的配置进行排列组合,大约能得到超过十亿种组合。
而Cassandra-diff则可以帮助比较两个版本或配置不同的集群所得到的结果是否相同。
使用Cassandra-diff的主要目的是确保数据库的准确性,然后在数据库不准确时查找出现的问题。具体实现方法是将整个集群的token切分,然后将不同的部分分配给不同的spark worker,进而比较每个token的数据。
05
Property based testing (PBT)
在Cassandra 4.0中,我们采用了一个新的写测试用例的方式。
在这之前,大家熟悉的是单元测试(unit test or example based test)——假设我们需要测试加法功能是否正确运行,我们可能以1+3为例进行测试,从结果是否为4判断功能是否正确运行。
但是PBT与单元测试不同,PBT考虑的是问题本质的属性,通过对属性的深入理解提出到达解集的不同路径,从而进行验证。
PBT将一个测试分为三步:输入策略、结果检查、错误收敛。
在这里举一个简单的例子来帮助理解:加法的属性。属性一:比如我们需要求得a、b之和,无论是a+b还是b+a,其结果应该是相同的;属性二:a+1+1与a+2应该得到相同的结果;属性三:a+0和a应该是一样的。
所以说,我们要的是像这样的属性而非具体的例子。
在数据库的测试中来讲,我们可以再举一个例子:如果硬盘出现故障,就会发生数据损害。数据损害就是一个属性,可以利用checksum来诊断数据损害。也就是说,数据受损后的checksum与受损前是不同的。
总的来说,PBT可以帮助我们更好、更多地发现问题,并且由于PBT产生的数据是随机的,所以也能更广泛地覆盖测试的范围。
本文内容版权归DataStax所有
未经书面允许禁止转载

DataStax在中国
技术资讯 | 行业动态 | 活动信息
阅读这篇文章有收获?
请通过点赞、分享和在看告诉我们