搜索引擎做为一个差不多是“resolved problem”,已经很少人再去关注实现,毕竟随着诸如Lucene(包含封装Solr和Elasticsearch)和SphinxSearch这样开源软件的大量使用,几乎95%的场景没有必要自己再去造这样一个轮子。然而,了解一个搜索引擎的实现和设计,仍然在某些方面具备价值:
数据量特别巨大,期望以搜索引擎作为流量入口的服务。
对排序和自定义结构有特定需求的服务。
对性能要求苛刻的业务。
期望提高自身技术储备的基础架构工程师。
尤其说明一下上述第4点,一个完整交付的搜索引擎,基本上会涉及到所有方面的计算机领域,包含体系结构,性能优化,存储设计,并发编程,数据结构,机器学习,而这些领域又是所有大数据基础架构核心领域开发的必备技能,因此参与到引擎的完整设计,可以算是对自身能力的全面提升。
一个搜索引擎由很多组件构成,例如包含实现搜索功能的索引(基本上是倒排索引),文档存放的KV数据库,分词,排序,以及并发服务器。如果再加上搜索引擎所需要的其余功能,那还会包含查询纠错,查询推荐,等等,如果需要构建分布式搜索引擎,那还需要一系列相关的架构组件。谈论搜索引擎实现是个庞大的话题,在学术界这被称为“信息检索”。对于搜索引擎没有概念的同学可以参照笔者数年前准备的豆列
http://www.douban.com/doulist/175805/ ,基本上涵盖了最好的搜索引擎书籍。我们在本公众号的文章中主要谈论点书本外的知识,特别是在工业界和学术界做到的state of the art,因此也希望读者对于搜索引擎有了基本了解之后才来阅读这一系列文章,主要围绕搜索引擎的核心——索引来展开。
索引作为搜索引擎的核心结构,对于搜索的性能起到决定性作用。为了尽可能加速检索过程,大型商业搜索基本上会把索引全部放入内存,因此在海量数据基础上,这需要构建庞大的集群;中小型搜索引擎会把索引放置在磁盘或者SSD上。不论索引放置在哪里,这都是一个通过各种创新来跟IO做斗争的过程,手段包括算法,压缩等等,以期望利用损耗CPU来换取IO时间。
数据结构上,几乎所有的搜索引擎都采用倒排索引提供搜索功能,只有极个别公司采用类似后缀数组的方式构建,例如来自日本的精锐团队Preferred Infrastructure。利用后缀数组构建索引,好处在于索引时无需引入分词功能,可以在巨大的数据集合上提供任意子串检索;另一个好处是搜索复杂度低,因此单机可以容纳更大的数据。然而,后缀数组构建的索引,体积是超过原始文本大小的,因此常常把它们放在SSD上,这样可以用小的IO开销提供比较高速的检索;还有一种做法是引入压缩后缀数组,这样可以在内存中存放足够多的索引数据,从而提供高速检索功能,这样的手法有CSA,FM-Index等不同道路,无一例外的它们都跟succinct数据结构有关。在HDD硬盘上是无法容纳这类索引的,因为后缀数组的检索都是二分查找,每一次触碰HDD磁盘都是一次随机IO,这是性能的巨大杀手。
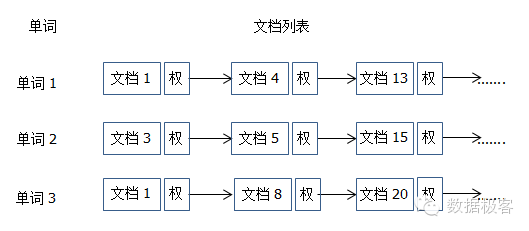
自从Lucene,SphinxSearch这样的开源引擎流行之后,很多人都认为没有继续创新的必要,然而,在追求更快,更实时等硬指标上,总有一些人在不断尝试,他们的努力值得我们钦佩,也是我们谈论的重点。以一个简要倒排索引图先做为本文的收尾,在后续的文章中,我们将直接采用术语而不加任何解释。
如图可见,倒排索引的构成分为2个部分,左边叫做词典,右边叫做文档列表,又称为posting list,搜索的过程就是找到词典的条目,并提取出文档列表从而继续求交或者求和,然后根据排序返回top文档的过程。