




最近在还原并排查之前活动的一个吞吐量上不去且网络延时很长的问题,在应用层显而易见,但是却不知道原因,只能追踪到协议层甚至更底,不过因为有其他的事情的耽误,这个事情并没有结束。在追查的时候碰到不少困难,再一次浏览了Netflix高级架构师,大名鼎鼎的性能优化大师Brendan Gregg的blog,这是一个澳大利亚人,从其Bios也能看出也是一个很逗逼的家伙,浏览的时候得到不少启示,无意中看到其在去年8月份写的关于Load Average解惑的一篇博文,读完后感觉令人叹为观止,大师对这个东西我相信比谁都了解,但是那种寻根究底的严谨态度令人难以望其项背,为了搞明白它的出处,甚至追踪到了内核开发者在1993年的邮件记录。我简单翻了一下,借花献佛,充斥一下我的公众号帮我装点一下门面吧。另外可以从大师的视角来加深对平均负载的理解。
Load Average(以下简称平均负载)是一个工程上非常关键的指标---我所在的公司花费了数百万美元去基于平均负载和其他的一些指标用于云实例的自动扩展。但是在Linux上,我们仍然觉得迷一样,Linux的Load Average不只是用来跟踪可运行的任务,还包括一些不可中断状态(译者注:ps状态为D,通常为IO)的任务,为什么呢?我从来没有看到任何对此的解释。基于此,我想解决这个不为人知的答案,然后将其总结出来让其他人参考从而去理解【注:大师就是大师,我不入地狱谁入地狱的感觉】。
Linux的Load Average就是“系统平均负载”,意为正在运行的线程对系统资源的需求,是运行的线程数加等待线程数的平均值。这个度量会比系统当前实际处理中的要高。大部分工具会显示三个平均值,分别是1、5、15分钟的。
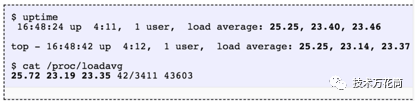
一些解释:
如果平均值为0.0,则系统当前处于空闲;
如果1分钟负载均值比5、15分钟高,说明负载在上升;
2反之,则负载在下降;
如果平均负载比CPU数量高,你可能遇到性能问题了(根据实际情况而定)
这三个数作为一个集合,对于你确定负载是上升还是下降来说很有用。当需要单个值时他们也很有用,比如作为云服务自动扩展的规则。但是如果脱离了其他的几个指标来获取更多信息就困难了,例如给出一个光杆值23-25,仅凭数字本身没有任何意义,除非知道了CPU个数或许能有点用,并且知道这个是CPU计密集型的负载任务。
历史
期初平均负载值仅仅代表是对CPU资源的需求:正在运行的加上等待运行的进程数量。早在1973年8月,在RFC546里面有一个很好的解释,标题为“TENEX(一个很古老的操作系统) Load Averages”:
TENEX的平均负载是对CPU资源需求的度量。平均负载是在给定的一段时间内运行中的进程数量的平均值。例如,每小时的平均负载是10(单CPU)意味着在这1小时内的任何时间都可以看到一个进程在运行,而另外的9个都在等待CPU(未被IO阻塞,译注:即Runnable,一切资源都就绪,就在等CPU时间片被调度,如果被IO阻塞,处于不可中断的sleeping状态)
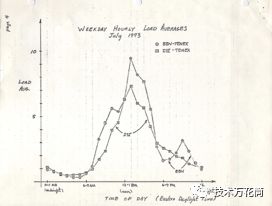
这个版本的RFC在ietf(https://tools.ietf.org/html/rfc546)上链接到一个在1973年关于平均负载的一张手绘图的PDF扫描件显示,在几十年前平均负载就已经被监控了。
如今,一些很老的操作系统都可以在网上找到关于其平均负载的源码,这是TENEX(70年代初)SCHED.MAC的DEC宏汇编程序的一个代码片段:
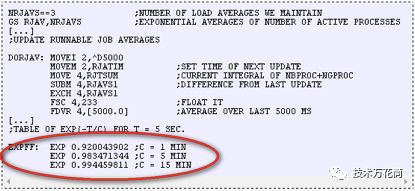
下面是今天Linux的代码(include/linux/sched/loadavg.h)

瞧,Linux都使用了硬编码的方式来定义1/5/15分钟的常量。在一些老的系统中都有类似的平均负载的指标,如Multics,它的调度队列均值是指数型的。
关于这三个数
这三个数字是1/5/15分钟(第1、第5、第15)的平均负载。它们除了不是真正的平均值外,它们也并非1/5/15分钟(第0-1分钟、第0-5分钟、第0-15分钟)。可以在上面的源码中看出,1/5/15分钟在等式中作为常数(译注:这个常量的计算方法为[(1<<11)/exp(5s/1min)])使用,用于计算每5s内均值的阻尼指数移动求和(译注:我也不知道这么翻译对不对,如果不对请指正)。
如果你有一个空闲的系统开始运行一个单线程的CPU密集型任务(单线程循环),那么60秒后第一分钟的平均负载会是多少?如果它是一个普通的平均值,应该是1.0,下面是这个实验的图表:
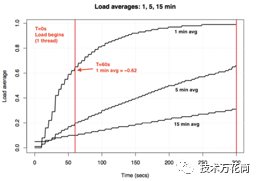
实验显示这个所谓的一分钟负载均值,在一分钟时只达到0.62。更多关于这个表达式和类似的试验,请参考Neil Gunther博士的文章How It Works和Linux源码的大量注释
https://github.com/torvalds/linux/blob/master/kernel/sched/loadavg.c
Linux不可中断任务
当平均负载第一次在Linux中出现的时候,它就像其他操作系统一样代表对CPU资源的需求。但是在后续的Linux变更中将其改为不但包含可运行的任务,还包含了不可中断任务(TASK_UNINTERRUPTIBLE or nr_uninterruptible),代码中使用这个状态是为了避免任务被信号中断(译者注:磁盘IO任务通常不能被中断,只能等待IO完毕,锁也是,锁如果被强制中断,则会导致线程安全等问题),包含被磁盘IO阻塞的任务和锁。在ps和top命令中经常见到状态为D的进程状态。
将不可中断态纳入意味着不只是CPU,磁盘IO也会导致Linux平均负载升高。在每个人都对其他操作系统及其CPU平均负载习以为常的时候,Linux将该状态纳入,让人深深的迷惑了。为什么Linux要这么做?
有很多关于平均负载的文章,很多文章指出Linux的nr_uninterruptible抓住了点,但是我从来没看到任何解释,甚至没有人质疑Linux为什么这么做。我自己的猜测是为了在更普遍的层面上反映对系统资源的需求,而不仅仅是CPU层面。
搜索很久以前的Linux补丁
要想知道为什么有些东西在Linux变更很简单,可以读取git的提交记录并阅读提交的注释。我检查了loadavg.c的历史,但是发现不可中断态的变更在该源文件在上传git之前就发生了。我检查了更老的文件,但是情况依旧,代码分散在不同的文件中,为了快捷一些,我找了个快捷方法,在git上对整个Linux内核的资源库做了一个” git log -p”的dump,面对多达4GB的文本数据,我开始往后寻找这段代码何时第一次出现。发现最早的修改在2005年,在这一年Linus(即linustorvalds,linux内核的作者)首次将Linux内核2.6.12-rc2版本导入到git,但是代码变更比这个时间还要早。
通过Linux的两个历史代码库https://git.kernel.org/pub/scm/linux/kernel/git/tglx/history.git和https://kernel.googlesource.com/pub/scm/linux/kernel/git/nico/archive/,发现提交的注释也丢失了。
至少可以试图找到这个改变是什么时候发生的,我搜索了位于kernel.org上的源码的tar包(译注:就是将历次更新的tar包进行一个比较,从而发现差异)然后发现这个变更始于版本0.99.15,并不是0.99.13---然而版本0.99.14已经不见了。我希望从linus为0.99.14版本的发布注释中找到解释,但是也失败了:
对上次发布的正式版本的改动实在太多了,根本没法说清楚(或者根本记不起来了)-----来自linus
Linus提到了大的变更,但是并不包含对loadavg的修改。
根据日期,我又查阅了内核邮件列表归档(http://lkml.iu.edu/hypermail/linux/kernel/index.html,内核开发维护者通过邮件沟通的往来邮件归档)去寻找这个实际的patch,但是最早的email始于1995年的7月,当时的管理员写道:
为了使得系统上邮件归档扩展更有效率,我意外的毁掉了当前的归档集,哎呀我的娘呀(译注:管理员可能是想优化系统,从而误操作将邮件归档删掉了)。
我开始迷茫了,不过谢天谢地的是,我找到了一些较早的linux开发者的邮件列表归档,这些归档是从服务器的备份中恢复的,以tar包摘要的形式存储。我搜索了超过98000份email中的超过6000份摘要,其中3w份始于1993年。但是从这些记录中仍然没有发现这个变更,此时我真正的认为这个最开始的patch可能已经永远的丢失了,这个变更的原因或许仍然是一个迷。
期初的不可中断态
幸运的是,我最终在oldlinux.org网站上一个1993年被压缩的邮箱文件中找到了变更,这是内容:
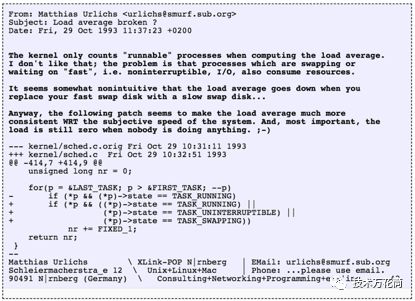
看到近24年前的这个变更背后的思路真是让人惊讶。
这确认了loadavg被有意的变更为对系统其他资源需求的一种反映,并非仅仅是CPU,Linux将其从“CPU平均负载”改成了“系统平均负载”。
【内核在计算loadavg时只统计可运行的进程数量,我不认为如此,问题在于进程正在被交换到磁盘或者等待被快速交换,例如不可中断状态,IO,都会消耗资源。看起来当你把低速的交换磁盘用高速的替换掉后,loadavg的下降程度并不直观…无论怎样,以下的patch看起来能使得loadavg和系统的客观性能更一致,并且更重要的是,当没有人使用系统时,load仍然是0】
邮件中他使用的低速交换的例子很有道理:通过降低系统性能(比如低速交换),对系统资源(以运行中任务+可运行任务队列来衡量)的需求就应该升高。然而,实际平均负载会降低,原因是他们只跟踪CPU运行时状态,同时并不跟踪交换状态,Matthias认为这并不合理,因此他就修复了这个问题。
现代的不可中断态
但是,linux的平均负载有时会飚高,这难道不是超出了磁盘IO的解释吗?是的,不过我猜测由于使用TASK_UNINTERRUPTIBLE状态的代码导致(译注:也就是说现在的平均负载的计算不仅仅包含磁盘IO,还有更多的状态,因为不可中断态包含很多种类),该代码在1993年时并不存在。在Linux的0.99.14版本中,有13处路径下的代码直接设置了TASK_UNINTERRUPTIBLE和TASK_SWAPPING(swapping状态在后续被移除掉了)状态。现在在4.12版本中,有将近400处代码设置了TASK_UNINTERRUPTIBLE,并包含一些锁原语。一个可能就是这众多路径下的某些代码不应该被纳入进平均负载中。下次如果我的系统如果负载看起来太高,我会看看是不是这个原因,能否被修复。
我给Matthias发了邮件去询问他,时隔24年之后,他对当初load average的修改是怎么看的。他居然在1小时内就给我回复了,让我开心了一天,他写道:
loadaverage的要点在于,以一个普通人的视角得到一个和当前系统繁忙程度相关的数字。TASK_UNINTERRUPTIBLE态代表进程等待如磁盘读写之类的事件,这会导致系统负载升高。一个磁盘读写繁重的系统性能可能会很糟糕,但是只通过TASK_RUNNING计算出的平均负载只有0.1,这对任何人都没有帮助。
所以Matthias仍然认为这么做有道理,至少他给予了TASK_UNINTERRUPTIBLE它本来的意思。
但是现在TASK_UNINTERRUPTIBLE和更多的东西相匹配(译注:也就是说这个态不单单代表了磁盘IO,随着Linux的发展,其包含了更多的含义,如网络IO等)。我们是否应当将load average改为只是对CPU和磁盘IO的资源需求?Scheduler的维护者Peter Zijstra已经发给我了一个聪明的办法去探索一下:将task_struct->in_iowait包含进平均负载中,而不是TASK_UNINTERRUPTIBLE,这样的话平均负载和磁盘IO更匹配。它引出了另一个问题,那就是到底什么是我们真正想要的?是我们想用线程的方式来衡量对系统的需求,还是仅仅以对物理资源的需求来衡量?如果是前者,那么应该包括在不可中断锁上面等待的线程,因为这些线程对系统资源有需求,它们并不是空闲的。所以或许Linux的平均负载已经在以我们所期望的方式在工作。
为了能更好的理解不可中断态的代码,我想要衡量它们的实际方法。我们可以检测不同的案例,测算系统在上面耗费的时间,然后分析它们是否都有意义。
衡量不可中断任务
下面是一个线上实际的生产服务器的Off-CPU(没有使用CPU)火焰图(http://www.brendangregg.com/blog/2016-01-20/ebpf-offcpu-flame-graph.html),时间跨度为60s并且只显示内核的调用栈,我过滤了只包含TASK_UNINTERRUPTIBLE态的。它提供了很多不可中断态的代码调用路径的示例。如果你是off-CPU火焰图的新手,你可以在每个帧上点击放大,检查帧塔上的完整调用栈(译注:纵向的是函数调用栈)。X轴的大小和花费在阻塞off-CPU上的时间成比例,从左往右的排序没有实际意义。蓝颜色代表不占用CPU的栈(我使用了暖色代表占用CPU的栈),采用了随机的颜色饱和度差异来区分不同的帧。在这个案例中,我只是显示了内核栈。

如上图所示,60s中只有926ms花费在不可中断睡眠上面,只让平均负载增加了0.015,系统并未产生较多的磁盘IO操作。
下面这个图持续了10s,但是却更有意思。
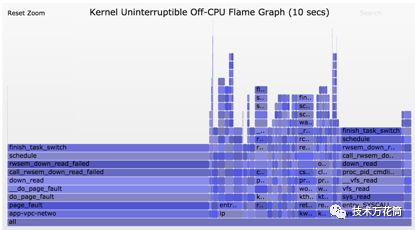
右侧比较宽的帧塔显示systemd-journal进程在执行proc_pid_cmdline_read()(读取/proc/PID/cmdline)方法时被阻塞了,并且贡献了0.07的平均负载值。在左侧有一个很宽的page fault帧塔,这个帧的调用结束于rwsem_down_read_failed()方法(贡献了0.23的平均负载值).我已经通过火焰图的搜索功能将这些函数以粉色高亮显示。这是rwsem_down_read_failed()函数的代码节选:
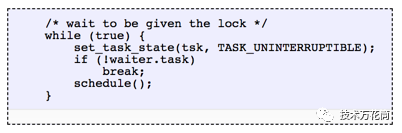
这是使用TASK_UNINTERRUPTIBLE的锁获取代码,Linux具有可中断及不可中断版本的互斥锁获取函数(例如信号量的mutex_lock()和mutex_lock_interruptible ()以及down()和down_interruptible),可中断版本的函数允许任务在获得锁之前被信号中断,然后醒来去处理该信号。不可中断锁的睡眠时间通常不会给系统增加较多的负载,但是在这个案例中却增加了0.3。如果更多的话,这就值得我们分析去看看能否去减少锁争用(比如在这里我会开始挖掘system-journal和proc_pid_cmdline_read()的原因),这应当会提升系统性能且降低负载。
将这些代码的逻辑包含在平均负载中是否有意义?是的,这一坨线程正在工作中,突然就被一个锁阻塞住了。他们并不是处于空闲中,他们需要系统资源,尽管是软件资源而非硬件资源。
剖析Linux平均负载
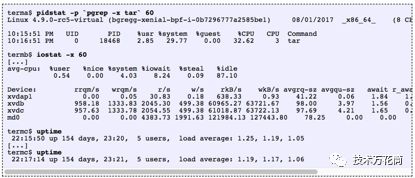
Linux的平均负载值能被全部的分解到不同的组件上去吗?这里有个案例:在一个空闲的具有8个CPU的系统上,我运行了tar命令去压缩一些未缓存的文件。它花费了几分钟,大部分都被阻塞在读磁盘上面。下面是从三个不同的终端窗口上收集到的状态:
我也只针对不可中断态采集了一个off-CPU火焰图:

最后的一分钟的平均负载为1.19,我们将其分解为如下:
0.33是tar进程占用的CPU时间(pidstat)【译注:用户态cpu*平均负载】
0.67是tar进程的不可中断态的磁盘读的负载,是推测出来的(off-cpu火焰图显示这个为0.69,我推测是off-cpu收集数据有些延迟导致跨越的时间范围不同)【译注:off-CPU的总耗时为41.464/60=0.69,而pidstat的监测显示tar耗费了32.62%的cpu时间,因此有67%左右的CPU由不可中断线程耗费,因此为0.67,作者说的收集数据有延迟意思是指iostate采集是周期性的,不一定在进程开始就立刻采集】
0.04是其他消耗CPU的进程(iostat用户态加内核态,从pidstat减tar进程CPU)【译注:0.54+4.03是io在用户态和核心态的cpu时间,总和4.57是分派到8核CPU上的平均值,因此一个CPU的话就是36.56%,pidstat显示tar消耗了32.62%d的cpu,因此仍然存在3.94%的差异,因此这3.94%可以认为是其他进程贡献的负载】
0.11是来自内核进程(kworker,内核中的工作者线程)的不可中断磁盘读消耗的时间,刷新写磁盘(火焰图上左侧的两个帧塔)【译注:显示kworkers的offcpu为(3.68+3.1)/60=0.11】
这些加到一起是1.15,我仍然少算了0.04,某些可能是因为舍入或者测量的间隔导致的误差,但是更多的有可能是由于平均负载是一个指数式阻尼移动求和的原因(译注:并非线性变化)。反而我使用的其他工具(如pidstat,iostat)的负载都是正常的。在1.19之前,第一分钟的负载为1.25,因此仍然有什么东西拖慢了我们。到底是多少呢?从我早些的火焰图中,在第一分钟的标记中,62%的该指标来自这一分钟,另外剩下的其他的是较老的。所有为0.62*1.15+0.38*1.25=1.18,这样的和系统报告的1.19很接近了。
这就是在一个系统上有一个线程(tar)和其他少量线程(有时是内核的工作者线程)运行时linux报告的平均负载为1.19,这很有道理。如果还是用“CPU平均负载”来衡量,这个系统的负载就成了0.37(通过iostat的摘要信息推测出),这对CPU资源的需求反馈是正确的,但是却隐藏了其他线程对系统资源的需求。
理解Linux的平均负载
我是随着各种操作系统成长起来的,提起平均负载都是指CPU平均负载,所以Linux系统的做法一直使我比较迷惑。或许真正的原因一直是“平均负载”这个词和IO一样含混不清。哪种IO?磁盘、网络还是文件?同理,“平均负载”是什么?CPU平均负载还是系统平均负载?这样来区分的话使得我是这么理解的:
在linux上,平均负载是“系统平均负载”,是从整个系统层面来衡量正在运行的和等待运行(CPU、磁盘、不可中断锁)的线程数量。优点:包含了对不同系统资源的需求。
在其他的操作系统上,平均负载指的是“CPU平均负载”,衡量正在CPU运行中和等待CPU可运行状态(译注:一切资源就绪,等待CPU时间片,或者是就绪状态)的线程数量。优点:容易理解,方便寻找原因(只和CPU有关)
需要指出有另外几种可能的类型:“物理资源平均负载”,只包含物理资源(CPU和磁盘)。
或许有一天我们会扩展linux平均负载,可以让用户选择他们想使用的:单独的CPU平均负载、磁盘平均负载、网络平均负载等等。或者可以将不同维度的指标混合起来使用。
什么是好的或者坏的平均负载?
一些人看起来找到了一些规律适用于他们的系统及工作负载情况:他们知道当负载超过X时,应用程序延迟升高并且用户开始抱怨,但是并不真正这样。
对CPU平均负载,有人会把这个负载值除以CPU的数量,这时他们会说如果这个值超过了1.0,你的系统在超负荷状态运行,可能会导致性能问题。这有点模棱两可,这个值是一个长期(至少1分钟)的平均值,会隐藏这期间的一些变化。一个系统的平均负载1.5可能会运行的很好,然而另外一个在某分钟内突然到达1.5有可能性能很差。
我曾经管理着一个双CPU的邮件服务器,全天的CPU平均负载在11-16之间(load/CPU比率在5.5-8之间)。使用的延迟可以让人接受且并没有任何人抱怨。这是一个比较极端的例子:大多数系统承受的load/CPU的比率只有2。
对于Linux系统的平均负载,由于覆盖了不同的资源类型因此更容易引起歧义,所以你不能仅仅去除以CPU数量。相对来说这样做更有用:如果你知道系统在20的负载下运行的很好,现在是40,这时你需要去深入追查一下其他的指标(译注:如vmstat、iostat、pidstat、netstat等,参考下节更加的指标)看看会发生什么。
更佳的指标
当Linux的平均负载升高时,你知道你需要更多的资源(cpu、磁盘、一些锁等),但是你并不确定到底是哪些。你可以使用其他的一些指标去辨别,例如cpu的:
每个CPU的使用率,如mpstat -P ALL 1
每个进程的CPU使用率,top/pidstat 1,etc
每个线程的运行队列(调度器)延迟,/proc/PID/schedstats, delaystats, perf sched
CPU运行队列延迟,/proc/schedstat, perf sched
CPU运行队列长度,vmstat 1
前面两个属于使用率指标,后面三个属于饱和度,指标。使用率指标对判断工作负载状况很有用,饱和度指标对定位性能问题很有帮助。最有用的CPU饱和度指标就是运行队列(或者调度器)延迟:一个线程/任务在可运行状态不得不等待被调度的等待时间。你可以去计算一个性能问题的量级,例如,一个线程花在等待调度器延迟的百分比时间。衡量运行队列的长度可以认为存在问题,但是很难去推断这个量级。
调度状态功能在Linux 4.6版本做成了内核可调整的(sysctl kernel.sched_schedstats),但是默认是关闭的。延迟记账(译注:linux内核进程调度的一种线程时间记录机制)暴露了相同的调度器延迟指标,存在于cpustat中,我已经建议加入到htop中,这样可以使得用户更加容易使用,比从/proc/sched_调试输出中获取等待时间度量更容易:
awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug |
除了CPU指标之外,你也可以从磁盘设备中查找使用率和饱和率。我会关注以下的指标:
Physical Resources
component | type | metric |
CPU | utilization | system-wide: vmstat 1, "us" + "sy" + "st"; sar -u, sum fields except "%idle" and "%iowait"; dstat -c, sum fields except "idl" and "wai"; per-cpu: mpstat -P ALL 1, sum fields except "%idle" and "%iowait"; sar -P ALL, same as mpstat; per-process: top, "%CPU"; htop, "CPU%"; ps -o pcpu; pidstat 1, "%CPU"; per-kernel-thread: top/htop ("K" to toggle), where VIRT == 0 (heuristic). [1] |
CPU | saturation | system-wide: vmstat 1, "r" > CPU count [2]; sar -q, "runq-sz" > CPU count; dstat -p, "run" > CPU count; per-process: /proc/PID/schedstat 2nd field (sched_info.run_delay); perf sched latency(shows "Average" and "Maximum" delay per-schedule); dynamic tracing, eg, SystemTap schedtimes.stp "queued(us)" [3] |
CPU | errors | perf (LPE) if processor specific error events (CPC) are available; eg, AMD64's "04Ah Single-bit ECC Errors Recorded by Scrubber" [4] |
Memory capacity | utilization | system-wide: free -m, "Mem:" (main memory), "Swap:" (virtual memory); vmstat 1, "free" (main memory), "swap" (virtual memory); sar -r, "%memused"; dstat -m, "free"; slabtop -s c for kmem slab usage; per-process: top/htop, "RES" (resident main memory), "VIRT" (virtual memory), "Mem" for system-wide summary |
Memory capacity | saturation | system-wide: vmstat 1, "si"/"so" (swapping); sar -B, "pgscank" + "pgscand" (scanning); sar -W; per-process: 10th field (min_flt) from /proc/PID/stat for minor-fault rate, or dynamic tracing [5]; OOM killer: dmesg | grep killed |
Memory capacity | errors | dmesg for physical failures; dynamic tracing, eg, SystemTap uprobes for failed malloc()s |
Network Interfaces | utilization | sar -n DEV 1, "rxKB/s"/max "txKB/s"/max; ip -s link, RX/TX tput / max bandwidth; /proc/net/dev, "bytes" RX/TX tput/max; nicstat "%Util" [6] |
Network Interfaces | saturation | ifconfig, "overruns", "dropped"; netstat -s, "segments retransmited"; sar -n EDEV, *drop and *fifo metrics; /proc/net/dev, RX/TX "drop"; nicstat "Sat" [6]; dynamic tracing for other TCP/IP stack queueing [7] |
Network Interfaces | errors | ifconfig, "errors", "dropped"; netstat -i, "RX-ERR"/"TX-ERR"; ip -s link, "errors"; sar -n EDEV, "rxerr/s" "txerr/s"; /proc/net/dev, "errs", "drop"; extra counters may be under /sys/class/net/...; dynamic tracing of driver function returns 76] |
Storage device I/O | utilization | system-wide: iostat -xz 1, "%util"; sar -d, "%util"; per-process: iotop; pidstat -d; /proc/PID/sched "se.statistics.iowait_sum" |
Storage device I/O | saturation | iostat -xnz 1, "avgqu-sz" > 1, or high "await"; sar -d same; LPE block probes for queue length/latency; dynamic/static tracing of I/O subsystem (incl. LPE block probes) |
Storage device I/O | errors | /sys/devices/.../ioerr_cnt; smartctl; dynamic/static tracing of I/O subsystem response codes [8] |
Storage capacity | utilization | swap: swapon -s; free; /proc/meminfo "SwapFree"/"SwapTotal"; file systems: "df -h" |
Storage capacity | saturation | not sure this one makes sense - once it's full, ENOSPC |
Storage capacity | errors | strace for ENOSPC; dynamic tracing for ENOSPC; /var/log/messages errs, depending on FS |
Storage controller | utilization | iostat -xz 1, sum devices and compare to known IOPS/tput limits per-card |
Storage controller | saturation | see storage device saturation, ... |
Storage controller | errors | see storage device errors, ... |
Network controller | utilization | infer from ip -s link (or /proc/net/dev) and known controller max tput for its interfaces |
Network controller | saturation | see network interface saturation, ... |
Network controller | errors | see network interface errors, ... |
CPU interconnect | utilization | LPE (CPC) for CPU interconnect ports, tput / max |
CPU interconnect | saturation | LPE (CPC) for stall cycles |
CPU interconnect | errors | LPE (CPC) for whatever is available |
Memory interconnect | utilization | LPE (CPC) for memory busses, tput / max; or CPI greater than, say, 5; CPC may also have local vs remote counters |
Memory interconnect | saturation | LPE (CPC) for stall cycles |
Memory interconnect | errors | LPE (CPC) for whatever is available |
I/O interconnect | utilization | LPE (CPC) for tput / max if available; inference via known tput from iostat/ip/... |
I/O interconnect | saturation | LPE (CPC) for stall cycles |
I/O interconnect | errors | LPE (CPC) for whatever is available |
虽然有很多更明确的指标,但是这并不代表平均负载没有用处。它和其他的度量指标被成功的用于云计算微服务的扩展策略中。这可以帮助微服务对不同类型的负载升高进行响应,如cpu或者磁盘IO。
