




《Redis设计与实现》读书笔记(三十六)
——Redis 慢查询日志实现
(原创内容,转载请注明来源,谢谢)
一、基本功能
redis的慢查询日志,用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度。
redis服务器中,有两个配置选项与此相关。
1)slowlog-log-slower-than,该选项确定超过多少微秒的命令请求,会被记录到日志。
2)slowlog-max-len,该选项指定服务器最多保存多少条慢查询日志。超出这个条数的,则会先删除最旧的一条日志,再新增一条日志。
可以用config setslowlog-log-slower-than 100来设置超过100毫秒的命令,或config set slowlog-max-len 100来设置慢查询日志最多纪录100条等。
可以通过sloglogget,来获取当前的慢查询日志。
二、慢查询记录的保存
服务器状态中,有几个和慢查询相关的属性,保存在redisServer结构体中。
struct redisServer{
//....其他内容
long long slowlog_entry_id;//下一条慢查询日志的id
list *slowlog;//所有慢查询日志的链表
long long slowlog-log-slower-than;//服务器配置的slowlog-log-slower-than值
unsigned long slowlog-max-len;//服务器配置的slowlog-max-len值
};
slowlog_entry_id初始化的值是0,每创建一条新的慢查询日志,这个属性的值就会变成最新的日志id的值,之后每创建一个慢查询日志,程序会对这个属性的值增1,作为新的慢查询日志的id。
slowlog链表,保存了服务器中所有的慢查询日志,链表中的每一个节点,就是一个slowlogEntry结构,每个结构代表一个慢查询日志。
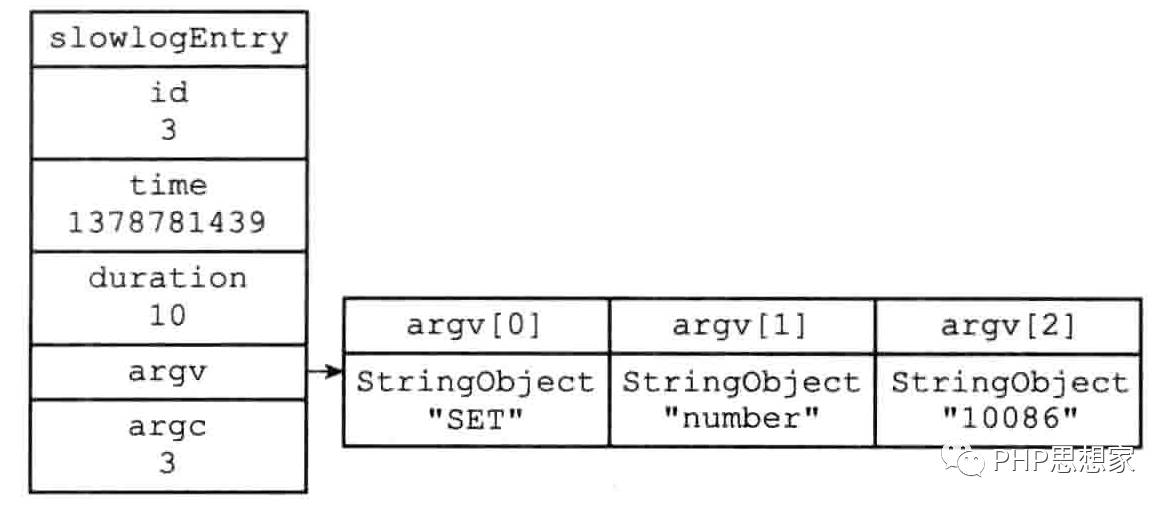
typedef struct slowlogEntry{
long long id;//唯一标识符
time_t time;//命令执行时间,是unix时间戳
long long duration;//命令执行消耗时间,毫秒为单位
robj **argv;//命令与命令参数
int argc;//命令数量
}slowlogEntry;
例如下图的慢查询日志:

其slowlogEntry结构如下图所示:
整体属性如下图所示:
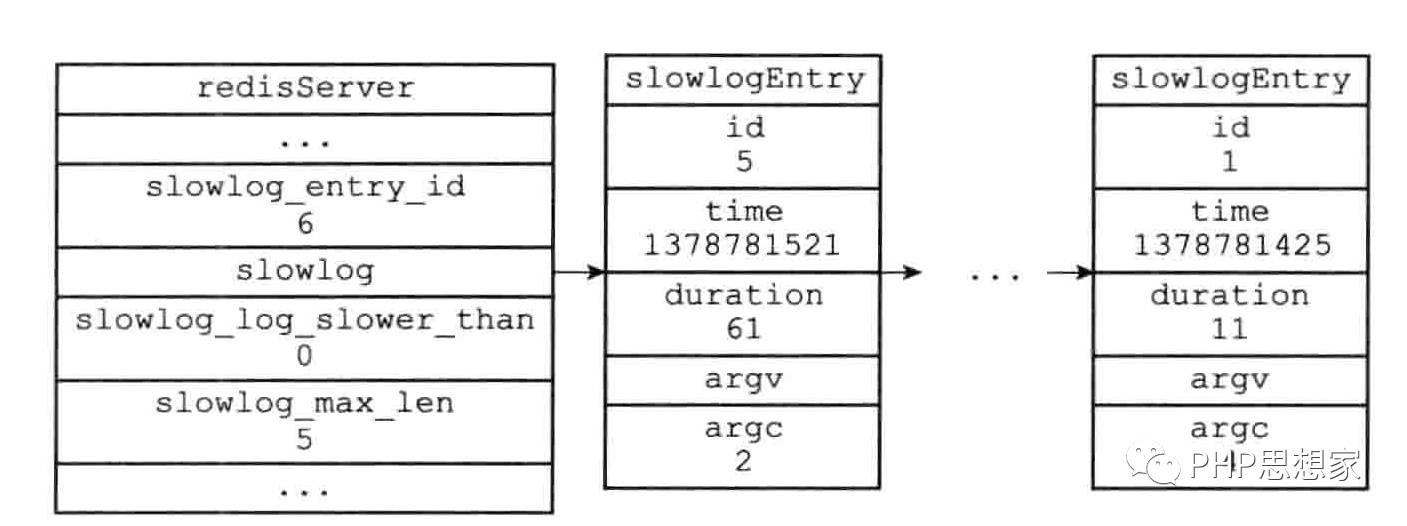
id越大的排在链表的表头,因此slowlog链表是使用插入到表头的方式来添加新日志。
三、慢查询日志的阅览和删除
如果没有指定返回的log的数量,默认返回整个慢查询日志。如果有指定,则会返回指定数量。但是如果指定的数量超出总数量,还是会返回整个慢查询日志。
四、添加新日志
每次执行前和执行后,redis服务器都会用微秒的方式,记录unix时间戳,差距就是执行服务器命令的耗时。
这个耗时会传给slowlogPushEntryIfNeeded函数,用于判断是否需要将查询命令记录到慢查询日志,以及目前的日志长度是否超出设定的范围,再将slowlog_entry_id值加1。
五、总结
1、慢查询功能用于记录执行时间超过设定时间的命令,可以通过配置文件配置需要记录的命令执行时间,单位是毫秒;配置慢查询日志的总记录数,超出这个数会删除最旧的日志后,添加一条新记录。
2、打印和删除慢查询日志可以通过遍历slowlog链表完成,该链表的长度就是保存慢查询日志的数量。新的日志会添加到表头,这样以便于如果链表长度超出总的长度,删除最旧的日志。
——written by linhxx 2017.10.02
