




点击上方蓝色文字关注我吧
目录
1、进程架构的概述
2、内存架构的概述
3、核心进程简介
4、核心进程源码解析
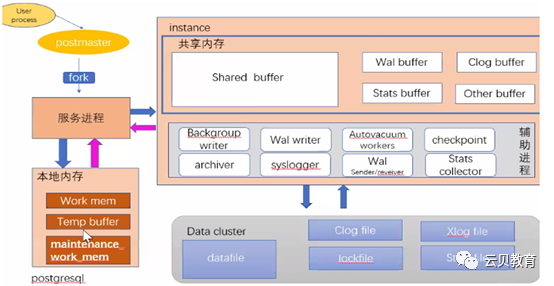
进程架构概述 –体系架构概览
记忆方法:3 + 5 + 8 + 5
postgres 118495 1 /opt/pgsql10.12/bin/postgrespostgres 18674 118495 postgres: logger processpostgres 18686 118495 postgres: checkpointerprocesspostgres 18687 118495 postgres: writer processpostgres 18688 118495 postgres: wal writerprocesspostgres 18689 118495 postgres: autovacuum launcherprocesspostgres 18690 118495 postgres: stats collectorprocesspostgres 18691 118495 postgres: bgworker: logicalreplication launcherpostgres 46841 118495 postgres: postgres postgres[local] idle
进程 | 说明 |
服务器进程 | 所有后台/后端进程的父进程 |
后端进程 | 处理客户端发出的语句请求 |
后台进程 | 负责数据库的管理任务 |
复制相关进程 | 流复制相关 |
内存架构概述
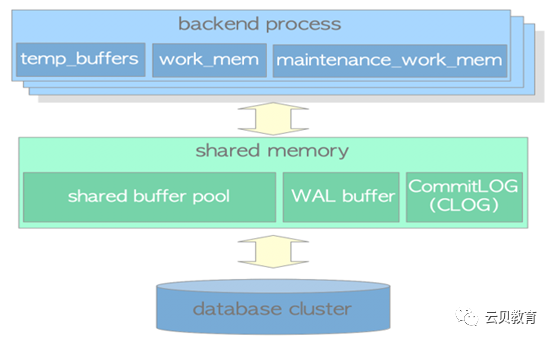
组件 | 描述 |
work_mem | ORDER BY 和 DISTINCT 操作对元组进行排序 |
maintenance_work_mem | 维护操作(VACUUM、REINDEX、alter等) |
temp_buffers | 使用这个区域来存储临时表。 |
shared buffer pool | 数据缓冲区 |
WAL buffer | WAL记录缓冲区 |
commit log | 事务提交日志缓冲区 |
进程、参数概览
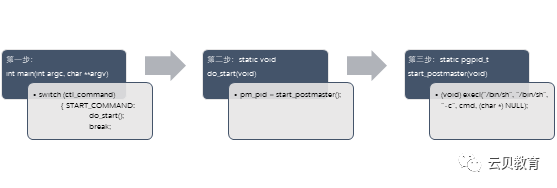
postgres(postmaster)概述
postgres 服务器进程是PostgreSQL 服务器中所有进程的父进程。在早期版本中,它被称为”postmaster”。
通过pg_ctlstart,postgres 服务器进程将启动。它在内存中分配一个共享内存区域,启动各种后台进程,必要时启动复制
关联进程和后台工作进程,并等待来自客户端的连接请求。
每当收到来自客户端的连接请求时,它就会启动一个后端进程。(后端进程处理连接的客户端发出的所有请求)
一个postgres服务器进程监听一个网络端口,默认端口是5432。虽然同一台主机上可以运行多个PostgreSQL服务(不同集
簇),但是每个服务器之间应该设置监听不同的端口号。
核心进程源码浅析
postgres(postmaster)源码浅析 1
src/bin/pg_ctl/pg_ctl.c复制
postgres(postmaster)源码浅析 2
src/backend/postmaster/postmaster.c复制
ListenAddresses/* The TCP listen address(es) */char *ListenAddresses;if (ListenAddresses) (IP地址才能判断为真)char *rawstring;List *elemlist;ListCell *l;int success = 0;
bacend process/** BackendStartup -- start backend process** returns: STATUS_ERROR if the fork failed,STATUS_OK otherwise.** Note: if you change this code, also considerStartAutovacuumWorker.*/static intBackendStartup(Port*port)复制
BackendProcesses 概述
后端进程,也称为postgres,由 postgres 服务器进程启动并处理由一个连接的客户端发出的所有语句。
它通过单个 TCP 连接与客户端通信,并在客户端断开连接时终止。
由于只允许操作一个数据库,因此在连接到 PostgreSQL 服务器时,必须明确指定要使用的数据库。
允许多个客户端同时连接;配置参数max_connections控制客户端的最大数量(默认为 100)。
如果WEB应用等很多客户端频繁重复连接和断开与PostgreSQL服务器的连接,会增加建立连接和创建后端进
程的成本,因为PostgreSQL没有实现本地连接池功能。这种情况对数据库服务器的性能有负面影响。为了处理这种情况,通常使用池中间件(pgbouncer 或pgpool-II)。
Backend Processes 源码浅析
src/backend/tcop/postgres.c复制
为用户交互连接调用InteractiveBackend()static intInteractiveBackend(StringInfo inBuf){intc; /* character read from getc() *//** display a prompt and obtain input from theuser*/printf("backend>");复制
BackendProcesses 相关参数浅析
max_connections 活跃的并发连接数,最大连接数。
superuser_reserved_connections 为管理员保留的连接数。
tcp_keepalives_idle复制
规定在操作系统向客户端发送一个TCP keepalive消息后无网络活动的时间总量。如果指定值时没有单位,则以秒为单位。值0(默认值)表示选择操作系统默认值。指定不活动多少秒之后通过 TCP 向客户端发送一个 keepalive 消息。0 值表示使用默认值。这个参数只有在支持TCP_KEEPIDLE或等效套接字选项的系统或Windows 上才可以使用。在其他系统上,它必须为零。在通过 Unix 域套接字连接的会话中,这个参数被忽略并且总是读作零。
tcp_keepalives_interval复制
规定未被客户端确认收到的TCP keepalive消息应重新传输的时间长度。如果指定值时没有单位,
则以秒为单位。值0(默认值)表示选择操作系统默认值。这个参数只有在支持TCP_KEEPINTVL或等效套接字选项的系统或Windows 上才可以使用。
在其他系统上,必须为零。在通过 Unix域套接字连接的会话中,这个参数被忽略并总被读作零。
tcp_keepalives_count复制
指定服务器到客户端的连接被认为中断之前可以丢失的TCP keepalive消息的数量。值0(默认值)表示选择操作系统默认值。这个参数只有在支持TCP_KEEPCNT或等效套接字选项的系统上才可以使用。在其他系统上,必须为零。在通过 Unix 域套接字连接的会话中,这个参数被忽略并总被读作零。
tcp_user_timeout复制
指定传输的数据在TCP连接被强制关闭之前可以保持未确认状态的时间量。如果指定值时没有单位,则以毫秒为单位。值0(默认值)表示选择操作系统默认值。这个参数只有在支持TCP_USER_TIMEOUT的系统上才被支持;在其他系统上,它必须为零。在通过Unix-domain套接字连接的会话中,此参数将被忽略并且始终读取为零。
checkpointerprocess 概述
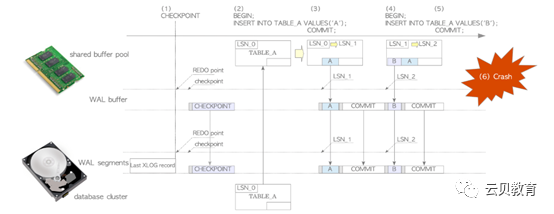
本图摘自” The Internals of PostgreSQL fordatabase administrators and system developers”
checkpointerprocess 源码浅析
src/backend/postmaster/checkpointer.csrc/include/catalog/pg_control.h复制
CheckpointerMain函数是checkpointer进程的入口.
检查点结构体定义
/*
*检查点XLOG记录的主体。这是在这里声明的,因为我们在这里保存了最新版本的副本pg_control可能的灾难恢复。更改此结构需要PG_CONTROL_VERSION。
*/typedef structCheckPoint{XLogRecPtr redo;/* 创建存盘时下一个可用的RecPtr(即重做点)*/TimeLineID ThisTimeLineID; /*当前时间线 ID TLI */TimeLineID PrevTimeLineID; /*当前一个时间线*/boolfullPageWrites; /* 当前整页写入的状态*/uint32 nextXidEpoch; /* 下一个事物ID的高位*/TransactionId nextXid; /*下一个空闲事物ID */Oid nextOid; /* 下一个空闲Oid*/MultiXactId nextMulti; /*下一个空闲 MultiXactId */MultiXactOffset nextMultiOffset;/* 下一个空闲 MultiXact 偏移量 */TransactionId oldestXid; /* 集簇范围最小的 datfrozenxid */Oid oldestXidDB; /* 带有最小datfrozenxid的数据库 */MultiXactId oldestMulti; /* 集簇范围内最小的datfrozenxid */Oid oldestMultiDB; /* 带有最小datminmxid的数据库 */pg_time_t time;/* 存盘时间栈*/TransactionId oldestCommitTsXid; /* oldest Xid with valid commit *timestamp */TransactionId newestCommitTsXid; /* newest Xid with valid commit * timestamp*//**最老的XID仍在运行。这只需要从在线检查点初始化热备用模式,所以我们只需要为在线检查点计算这一点,并且仅当wal_级别为副本时。否则它将设置为InvalidTransactionId。*/TransactionId oldestActiveXid;} CheckPoint;复制
checkpointerprocess 相关参数浅析
writer process 概述
BgWriterprocess 源码浅析
src/backend/postmaster/bgwriter.c复制
*/voidBackgroundWriterMain(void){sigjmp_buf local_sigjmp_buf;MemoryContextbgwriter_context;bool prev_hibernate;WritebackContextwb_context;/** Properly accept or ignore signals thepostmaster might send us.** bgwriter doesn't participate in ProcSignalsignalling, but a SIGUSR1* handler is still needed for latch wakeups.*/…………………}复制
BgWriterprocess 相关参数浅析
bgwriter_delay = 200ms # 10-10000ms between rounds复制
bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round复制
bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffersscanned/round复制
bgwriter_flush_after = 512kB # measured in pages, 0 disables复制
wal writerprocess 概述
wal writerprocess 源码浅析
WalWriterMain();src/backend/postmaster/walwriter.c/*WalWriter process,主入口函数是WalWriterMain(void)*/Void WalWriterMain(void){sigjmp_buf local_sigjmp_buf;MemoryContextwalwriter_context;int left_till_hibernate;bool hibernating;/** Properly accept or ignore signals thepostmaster might send us** We have no particular use for SIGINT at themoment, but seems* reasonable to treat like SIGTERM.*/pqsignal(SIGHUP,WalSigHupHandler); /* set flag to read config file */pqsignal(SIGINT,WalShutdownHandler); /* request shutdown*/pqsignal(SIGTERM,WalShutdownHandler); /* requestshutdown */pqsignal(SIGQUIT,wal_quickdie);/* hard crash time */pqsignal(SIGALRM,SIG_IGN);pqsignal(SIGPIPE,SIG_IGN);pqsignal(SIGUSR1,walwriter_sigusr1_handler);pqsignal(SIGUSR2,SIG_IGN); /* not used */… …
wal writerprocess 相关参数浅析 1
wal writerprocess 相关参数浅析 2
autovacuumlauncher process /workers 概述 1
autovacuumlauncher process /workers 概述 2
autovacuumlauncher process /workers 源码浅析
src/backend/postmaster/autovacuum.c* Main loop for the autovacuum launcherprocess.*autovacuum进程主循环*/NON_EXEC_STATIC voidAutoVacLauncherMain(int argc, char *argv[]){* 在某个worker仍然在启动时,不能启动新的worker,因此休眠一段时间;* 另外一个worker在ready后会第一时间唤醒我们.* 只需要等待autovacuum_naptime参数设置的时间(单位秒)(最大为60s).* 注意,在这里不能够连接一个特定的数据库不存在任何问题,因为worker在* 尝试连接时,通过startingWorker指针销毁自己.* 通过postmaster检测到问题(如fork()失败)会报告并且进行不同的处理,* 这里唯一的问题是可能导致这里的处理逻辑在AutoVacWorkerMain的早起触发错误,* 而且是在worker通过startingWorker指针清除WorkerInfo前.*/waittime = Min(autovacuum_naptime, 60) * 1000;if (TimestampDifferenceExceeds(worker->wi_launchtime, current_time,waittime)){}… …}复制
autovacuumlauncher process /workers 相关参数浅析
stats collectorprocess 概述
stats collectorprocess 源码浅析
src/backend/postmaster/pgstat.c复制
intpgstat_start(void){time_t curtime;pid_t pgStatPid;复制
if (pgStatSock == PGINVALID_SOCKET)return 0;复制
curtime = time(NULL);if ((unsigned int) (curtime - last_pgstat_start_time) <(unsigned int) PGSTAT_RESTART_INTERVAL)return 0;last_pgstat_start_time = curtime;复制
bgworker:logical replication launcher 概述
1)满足业务上需求,实现某些指定表数据同步
2)报表系统,采集报表数据
3)PostgreSQL 跨版本数据同步
4)PostgreSQL 大版本升级
5)可从多个上游服务器,做数据的聚集和合并
使用发布者/订阅者模型,使用订阅复制槽技术,可并行的传输WAL日志,通过在订阅端回放WAL日志中的逻辑条目,保持复制表的数据同步,这里不是“SQL”复制,而是复制SQL操作的结果。
bgworker:logical replication launcher 相关参数浅析
这些设置控制逻辑复制订阅的行为。发布者的值无关紧要。
请注意,wal_receiver_timeout和 wal_retrieve_retry_interval配置参数还影响逻辑复制工作。
指定逻辑复制工作的最大数量。这包括应用工作和表同步工作。
逻辑复制工作进程是从max_worker_processes 定义的进程池中取出的。
默认值是4。
每个订阅的最大同步工作者数量。此参数控制订阅初始化期间或添加新表时初始数据副本的并行数量。
目前,每个表只能有一个同步工作进程。
同步工作进程是从max_logical_replication_workers 定义的进程池中取出的。默认值是2。
通常,使用CREATE SUBSCRIPTION 创建订阅时会自动创建远程复制槽,使用DROP SUBSCRIPTION 删除订阅时会自动删除该槽。
复制槽提供了一种自动化的方法来确保主控机在所有的后备机收到 WAL段之前不会移除它们,主库随时知道从库应用wal 的情况 , 哪怕从库掉线,主库依然保留 wal日志这种机制的缺点是,如果从库掉线很久, 那么主库的wal日志 会一直保留以至于撑暴硬盘, 这时监控需要做到位。
max_replication_slots = 10 #max_replication_slots 值最少需设置成 1,设置后重启数据库生效。
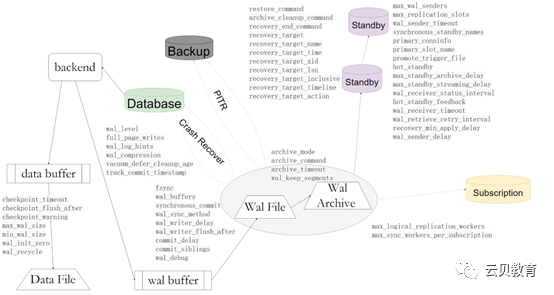
WALSender/reveiver 概述
WALSender/reveiver 源码浅析1
PostgresMain
后台进程postgres的主循环入口 — 所有的交互式或其他形式的后台进程在这里启动.
其主要逻辑如下:
1.初始化相关变量
2.初始化进程信息,设置进程状态,初始化GUC参数
3.解析命令行参数并作相关校验
4.如为walsender进程,则调用WalSndSignals初始化,否则执行其他信号初始化
5.初始化BlockSig/UnBlockSig/StartupBlockSig
6.非Postmaster,则检查数据库路径/切换路径/创建锁定文件等操作
7.调用BaseInit执行基本的初始化
8.调用InitProcess/InitPostgres初始化进程
9.重置内存上下文,处理加载库和前后台消息交互等
10.初始化内存上下文
11.进入主循环
11.1切换至MessageContext上下文
11.2初始化输入的消息
11.3给客户端发送可以执行查询等消息
11.4读取命令
11.5根据命令类型执行相关操作
WALSender/reveiver 源码浅析2
voidPostgresMain(int argc, char *argv[],const char *dbname,const char *username){/** Set up signal handlers and masks.* 配置信号handlers和masks.** Note that postmaster blocked all signals before forking child process,* so there is no race condition whereby we might receive a signal before* we have set up the handler.* 注意在fork子进程前postmaster已阻塞了所有信号,* 因此就算接收到信号,但在完成配置handler前不会存在条件争用.** Also note: it's best not to use any signals that are SIG_IGNored inthe* postmaster. If such a signalarrives before we are able to change the* handler to non-SIG_IGN, it'll get dropped. Instead, make a dummy* handler in the postmaster to reserve thesignal. (Of course, this isn't* an issue for signals that are locally generated, such as SIGALRM and* SIGPIPE.)* 同时注意:最好不要使用在postmaster中标记为SIG_IGNored的信号.* 如果在改变处理器为non-SIG_IGN前,接收到这样的信号,会被清除.* 相反,可以在postmaster中创建dummy handler来保留这样的信号.* (当然,对于本地产生的信号,比如SIGALRM和SIGPIPE,这不会是问题)*/if (am_walsender)//wal sender进程?WalSndSignals();//如果是,则调用WalSndSignalselse//不是wal sender进程{//设置标记,读取配置文件pqsignal(SIGHUP, PostgresSigHupHandler); /* set flag to read config* file */复制
WALSender/reveiver 源码浅析3
//中断信号处理器(中断当前查询)pqsignal(SIGINT, StatementCancelHandler); /* cancel current query *///终止当前查询并退出pqsignal(SIGTERM, die); /* cancel current query and exit *//** In a standalone backend, SIGQUIT can be generated from the keyboard* easily, while SIGTERM cannot, so we make both signals do die()* rather than quickdie().* 在standalone进程,SIGQUIT可很容易的通过键盘生成,而SIGTERM则不好生成,* 因此让这两个信号执行die()而不是quickdie().*///bool IsUnderPostmaster = falseif (IsUnderPostmaster)//悲催时刻,执行quickdie()pqsignal(SIGQUIT, quickdie); /*hard crash time */else//执行die()pqsignal(SIGQUIT, die); /* cancel current query and exit *///建立SIGALRM处理器InitializeTimeouts(); /* establishesSIGALRM handler *//** Ignore failure to write to frontend. Note: if frontend closes* connection, we will notice it and exit cleanly when control next* returns to outer loop. Thisseems safer than forcing exit in the* midst of output during who-knows-what operation...* 忽略写入前端的错误.* 注意:如果前端关闭了连接,会通知并在空中下一次返回给外层循环时退出.* 这看起来会比在who-knows-what操作期间强制退出安全一些.*/pqsignal(SIGPIPE, SIG_IGN);pqsignal(SIGUSR1, procsignal_sigusr1_handler);pqsignal(SIGUSR2, SIG_IGN);pqsignal(SIGFPE, FloatExceptionHandler);复制
WALSender/reveiver 相关参数浅析1
主库
wal_level = logical
max_wal_senders = 32
max_standby_archive_delay = 300s
max_standby_streaming_delay = 300s
当热后备机处于活动状态时,这个参数决定取消那些与即将应用的 WAL 项冲突的后备机查询之前,后备服务器应该等待多久
wal_receiver_status_interval = 10s
指定在后备机上的 WAL 接收者进程向主服务器或上游后备机发送有关复制进度的信息的最小频度,它可以使用pg_stat_replication视图看到。后备机将报告它已经写入的上一个预写式日志位置、它已经刷到磁盘的上一个位置以及它已经应用的最后一个位置。这个参数的值是报告之间的最大时间量。每次写入或刷出位置改变时会发送状态更新,或者至少按这个参数的指定的频度发送。因此,应用位置可能比真实位置略微滞后。如果指定值时没有单位,则以秒为单位。默认值是10 秒。将这个参数设置为零将完全禁用状态更新。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
hot_standby_feedback = on
指定一个热后备机是否将会向主服务器或上游后备机发送有关于后备机上当前正被执行的查询的反馈。这个参数可以被用来排除由于记录清除导致的查询取消,但是可能导致在主服务器上用于某些负载的数据库膨胀。反馈消息的发送频度不会高于每个wal_receiver_status_interval周期发送一次。默认值是off。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
hot_standby = on
指定在恢复期间,你是否能够连接并运行查询,默认值是on。这个参数只能在服务器启动时设置。它只在归档恢复期间或后备机模式下才有效。
WALSender/reveiver 相关参数浅析2
archiverprocess 概述
archiverprocess 源码浅析
src/backend/postmaster/pgarch.c/**pgarch_start*在启动时或现有archiver died从postmaster处调用。尝试启动一个新的归档进程。返回子进程的PID,如果失败则返回0。注意:如果失败,将从postmaster主循环再次调用我们。*/intpgarch_start(void){time_t curtime;pid_t pgArchPid;/*如果从上次归档开始太快,请不要执行任何操作。这是一个安全阀,用于防止在执行时archiver立即dying 的情况下持续重生。请注意,因为我们将从postmaster主循环重新调用,所以稍后我们将获得另一个机会。*/curtime= time(NULL);if((unsigned int) (curtime - last_pgarch_start_time) <(unsignedint) PGARCH_RESTART_INTERVAL)return0;last_pgarch_start_time= curtime;… …复制
archiverprocess 相关参数浅析
logger process 概述
logger process 源码浅析
src/backend/postmaster/syslogger.c/* syslogger process 主入口 */NON_EXEC_STATIC voidSysLoggerMain(int argc, char *argv[]){#ifndef WIN32char logbuffer[READ_BUF_SIZE];int bytes_in_logbuffer =0;#endifchar *currentLogDir;char *currentLogFilename;int currentLogRotationAge;pg_time_t now;now = MyStartTime;#ifdef EXEC_BACKENDsyslogger_parseArgs(argc, argv);#endif /* EXEC_BACKEND */am_syslogger = true;init_ps_display("logger", "", "","");/* 如果重新启动,我们的STDRR已经被重定向到我们自己的输入管道中。这当然是无用的,更不用说它干扰检测管EOF。把stderr只想到/dev/null 。假设 syslogger 中生成的所有的消息将通过elog.c发送到 write_syslogger_file 。*/if (redirection_done){int fd = open(DEVNULL,O_WRONLY, 0);/* 关闭可能看起来是多余,但实际上并不是:我们要确保管道即使打开失败也会关闭。我们可以在stderr 指向任何地方运行,但我们不能负担额外的管道输入描述符。由于我们只是试图将这些重置为DEVNULL,所以在这里从close/dup2调用中检查失败没有多大意义,如果它们失败,那么可能文件描述符被关闭,并且任何写入都将进入 bitbucket 。*/复制
logger process 相关参数浅析
log_destination = 'csvlog';
logging_collector = on;
log_directory = 'pg_log';
log_filename = 'postgresql-log.%a';
log_truncate_on_rotation = on;
当logging_collector被启用时,这个参数将导致PostgreSQL截断(覆盖而不是追加)任何已有的同名日志文件。不过,截断只在一个新文件由于基于时间的轮转被打开时发生,在服务器启动或基于尺寸的轮转时不会发生。如果被关闭,在所有情况下以前存在的文件将被追加。例如,使用这个设置和一个类似postgresql-%H.log的log_filename将导致产生 24 个每小时的日志文件,并且循环地覆盖它们。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
log_rotation_age = 1440;
在打开了logging_collector的时候,这个选项设置一个独立日志文件的最大生存期。在数值指定的分钟过去之后,将创建一个新的日志文件。设置为零可以关闭以时间为基础的新日志文件的创建。在打开了logging_collector的时候,这个选项设置一个独立日志文件的最大生存期。在数值指定的分钟过去之后,将创建一个新的日志文件。设置为零可以关闭以时间为基础的新日志文件的创建。
log_rotation_size = 1000000;
在打开了logging_collector的时候,这个选项设置一个独立的日志文件的最大尺寸。在数值指定的千字节写入日志文件之后,将会创建一个新的日志文件。设置为零可以关闭以尺寸为基础的新日志文件的创建。
log_min_duration_statement = 500;
在打开了logging_collector的时候,这个选项设置一个独立的日志文件的最大尺寸。在数值指定的千字节写入日志文件之后,将会创建一个新的日志文件。设置为零可以关闭以尺寸为基础的新日志文件的创建。如果某个语句的持续时间大于或者等于这个毫秒数,那么在日志行上记录该语句及其持续时间。设置为零将打印所有查询和他们的持续时间。设置为-1(缺省值)关闭这个功能。比如,如果你把它设置为250ms,那么所有运行时间等于或者超过 250ms 的SQL 语句都会被记录。打开这个选项可以很方便地跟踪需要优化的查询。只有超级用户可以改变这个设置。对于使用扩展查询协议的客户端,语法分析、邦定、执行每一步所花时间都分别记录。
log_statement = ddl;
控制记录哪些SQL语句。有效的值是none(off), ddl, mod和 all (所有语句)。ddl记录所有数据定义命令,比如CREATE, ALTER和DROP语句。mod记录所有ddl语句,加上数据修改语句INSERT,UPDATE, DELETE, TRUNCATE, 和COPY FROM。如果所包含的命令类型吻合,那么PREPARE, EXECUTE和EXPLAIN ANALYZE语句也同样被记录。对于使用扩展查询协议的客户端,记录发生在接受到扩展信息并包含邦定参数(内置单引号要双写)的时候。
缺省是none。只有超级用户可以改变这个设置。

PG考试本年度
最后一场将在11月20日举行
想考试和培训的同学
可以扫描下方二维码咨询老师

往期回顾
【干货分享】深度解析Write-Ahead Logging

点击“阅读原文”
