




如果有100个因为单词,如果使用二分搜索树保存就是100个节点,每个节点保存的就是一个单词,查询每个单词花费的时间复杂度大概是O(log100).
使用Trie这种数据结构,每个结果保存的是要给字母,查询是和多少个单子无关,只和单子长度有关.
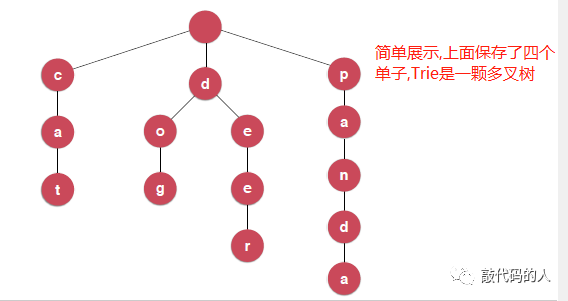
如果在英语中不考虑大小写的话,每个节点都会有26个指向下个节点的指针
class Node{char c;Node next[26];}复制
但是考虑到使用语言,情境的不同,我们表示从一个节点到下一个节点是一个映射的过程,而且去下一个节点之前,我们已经知道了这个字母是什么,所以节点可以这样设计
在英语单词中pan和panda这是两个单词,光靠叶子节点不能区分,所以添加一个标志,代表是不是一个单词的结
class Node{boolean isWord;Map<Character,Node> next;}复制
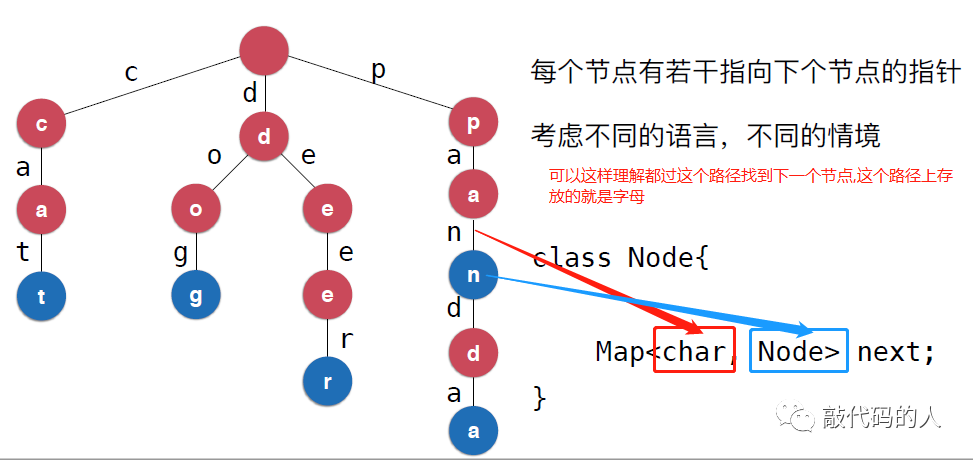
节点设计说明:
private class Node {// 我们设计时,不一定存放的一定是26个因为字母// 所以每一个节点指向的是n个节点// 所以每个节点存放的是一个映射Map,// map中的存放的是一个字符,及对应的下一个node// 可以这样理解,这个节点中存放的是可以去下一个节点的路标// 正好映射中存放的一一对应的关系,Character就是连接下一个不同节点的路径Map<Character, Node> next;// 这里没有设计 char c;// 因为这个节点需要存放的字符,就是上一个节点找过的路标,就是Character// char c// 我们trie存放的是一个单词,所以需要设计一个表示单词结尾的符号boolean isWord;// 构造函数public Node(boolean isWord) {this.isWord = isWord;next = new TreeMap<>();}// 无参public Node() {}}复制
基础框架设计:
public class Trie{//内部类//设计成员变量private Node root;private int size;//构造函数public Trie(){root = new Node();size = 0;}//获取trie中存储的单词数量public int getSize(){return size;}}复制
向trie中添加字符串
思路分析:
我们节点存放的是一个一个字符,但是添加的是一个一个单词,也就是字符串
我们需要把一个一个字符串拆成一个一个字符,组织成一个一个节点,添加进去
添加时,取出字符串第一个节点,以二叉树的根节点为第一个节点的下一个节点插入
判断当前节点中有没有可以根据需要插入的字符,可以到达的节点
如果有,跳过,当前节点往下移
没有,把字符做成节点挂接(就是上一个节点,添加一个根据字符能到新添加节点的路径),当前节点下移
循环,直至字符串最后一个字符,并把最后一个节点,最后单词标志(isWord = true)
//想trie中添加一个新的单词wordpublic void add(String word){//定义当前trie的节点为根几点Node cur = root;//遍历每一个字符串的每一个字符for(int i = 0; i < word.length();i++){//取出每一个字符比较char c = word.charAt(i);//当前节点是否有能根据c,到达的下一个节点if(cur.next.get(c) == null){//没有找到下一个节点cur.next.put(c, new Node());}//当前节点网下移cur = cur.next.get(c);//判断最后节点位置isword是否为trueif(!cur.isWord){cur.isWord = true;size++;}}}复制
查询trie中是否存在单词word
思路分析:
和添加大致一样,拆成字符遍历
如果下一个节点没有找到,直接返回false;
来到以后一个节点不能直接返回true,(因为如果直接有一个单词是abcd,但是查找的是ab)
这样情况也能到达单词最后一个字符,但是trie中并没有ab
最后判断,isWord
//查询单词word是否存在trie中public boolean contains(String word){Node cur = root;for(int i = 0; i <word.length();i++ ){char c = word.charAt(i);if(cur.next.get(c) == null){return false;}cur = cur.next.get(c);}return cur.isWord;}复制
查找trie中是否有单词以prefix为前缀
思路分析:
和查找一个单词一样
但是查找到最后直接返回true
// 查询单词word是否存在trie中public boolean isPrefix(String word) {Node cur = root;for (int i = 0; i < word.length(); i++) {char c = word.charAt(i);if (cur.next.get(c) == null) {return false;}cur = cur.next.get(c);}return true;}复制
喜欢,转发
明天见

文章转载自敲代码的人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
2505次阅读
2025-04-09 15:33:27
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1164次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
846次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
659次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
577次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
561次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
539次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
475次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
457次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
451次阅读
2025-04-30 12:17:50
