




HDFS是hadoop的三驾马车之一,是一种大规模分布式文件存储系统。
使用HDFS存储的场景是:当数据集大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区,并存储到若干台独立的计算机上。
HDFS的设计特点:
• 超大文件
• 流式数据访问
• 低成本
• 数据一致性
• 高吞吐率
• 易扩展
• 高容错
下面我们解剖一下HDFS的设计实现,来分析HDFS是如何体现其特点的。
(说明:以下内容 基于 hadoop v2.7.7)
提醒:本次内容有点多,是后续hadoop学习的基础,是从原理上了解什么是大数据的基础,必须努力啃下这块无聊的硬骨头
PS:为方便查看,建议大家在PC上看这篇内容。
本篇内容概述:
先了解一下 HDFS的数据存储思路,为了解HDFS总体架构铺平道路。
再了解一下HDFS的写文件、读文件的流程,最后了解一下HDFS的高可用架构。基本覆盖了HDFS的相关内容。为后续MapReduce、YARN的学习打下基础。

我们先了解一下HDFS的存储思路,方便理解HDFS的总体架构。
场景:一个大小为10GB的文件,是如何存储到HDFS中的

从HDFS的设计思路上,主要用于解决超大文件的存储(上面图中以存储10GB文件为例)
第一步:在存储前会先对待存储文件进行块切分,上面示例中每块大小是 128MB(每块大小可配置),总共需要切分80块。
第二步:NameNode会记录当前待存储文件的分块信息,并根据DataNode各个节点的存储情况,给出每个数据块的存储位置。
第三步:根据NameNode的分配策略,80个数据块分别存储到对应的DataNode节点,并向NameNode汇报存储结果。
说明:
(1)上面示意图只是描述了每个数据块1个副本的存储情况,生产环境中为提高数据的可用性,一般会设置1个以上的副本(默认是3份)。多副本存储思路和上面思路类似。
(2)有朋友估计在想,如果不够128MB的整数倍怎么办。
HDFS的处理思路是,最后一块仍然会作为一个独立的数据块,但磁盘的实际占用以最后一块实际大小为准。
(3)每个DataNode可指定1个或多个磁盘目录,当指定多个磁盘目录时,随着写入数据越来越多,容易出现各目录下数据不均衡的问题。为避免不均衡问题,可参考以下配置策略:
多目录配置方法
<property><name>dfs.datanode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value></property>复制
hadoop写入文件有两种策略:
1. 轮询方式(默认)
RoundRobinVolumeChoosingPolicy
2. 根据可用空间的大小来判断写入
AvailableSpaceVolumeChoosingPolicy
通过以下参数来设置使用哪种策略来写入(下面配置是采用策略2)
<property><name>dfs.datanode.fsdataset.volume.choosing.policy</name><value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value></property>复制
写入策略选择建议:
如果每个目录的大小是一样的,可使用默认策略;
如果各个目录大小不一致,避免小磁盘使用率过高,使用策略2。

了解了HDFS的存储思路后,下面咱们分析一下HDFS的总体架构
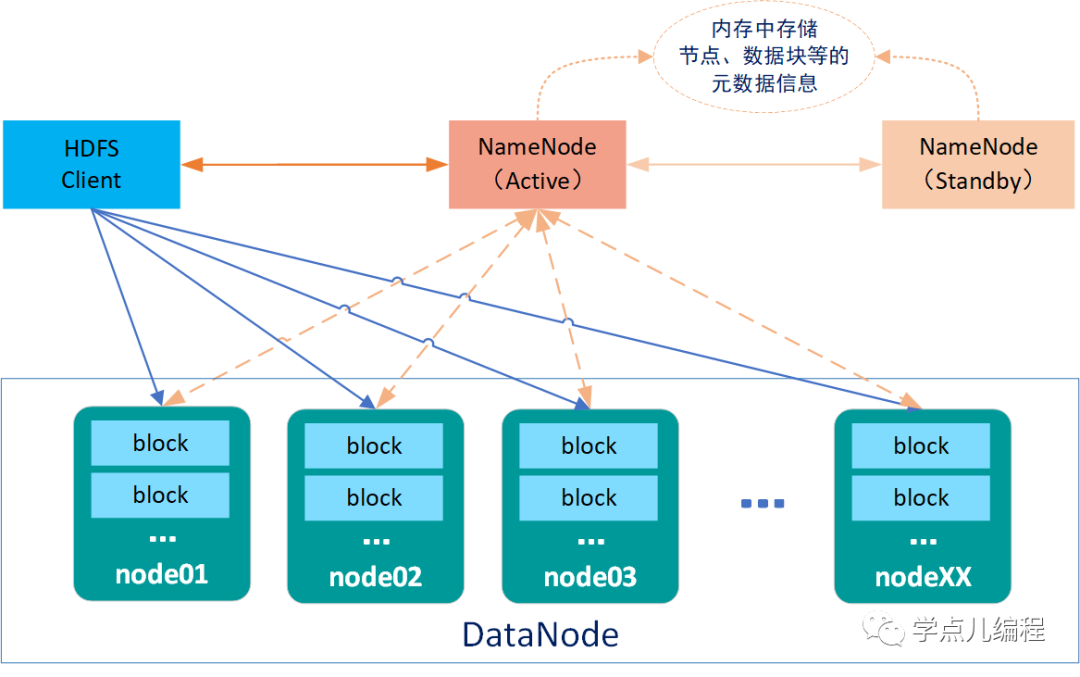
在解释总体架构图之前,我们先了解HDFS的几个核心概念
| Client | • 对待存储文件进行切分 • 与NameNode交互交换文件元数据信息 • 与DataNode交互,读取或写入数据 • 管理HDFS(基于nameNode对dataNode上的数据进行管理) |
| Block数据块 | • 文件写入到HDFS会被切分成若干个Block块 • 数据块大小固定(默认大小128MB),可自定义修改 • HDFS的最小存储单元 • 若一个块的大小小于设置的数据块大小,则不会占用整个块的空间 • 默认情况下每个Block有三个副本 |
NameNode 元数据文件 | 1、NameNode内存中保存一份最新的镜像信息(fsimage + edits) • edits:编辑日志,客户端对目录和文件的写操作首先被记到edits日志中,如:创建文件、删除文件等 2、NameNode定期将内存中的新增的edits与fsimage合并保存到磁盘 |
Active NameNode | • nameNode主节点(只有一个) • 管理HDFS文件系统的命名空间 • 维护文件元数据信息 • 管理副本策略(默认3个副本) • 处理客户端(client)的读写请求 |
Standby NameNode | • Active NameNode的热备节点 • 周期性同步edits编辑日志,定期合并fsimage与edits到本地磁盘 • Active NameNode有故障时,可快速切换为新的Active |
| DataNode | • 工作节点,可以启动多个 • 存储数据块和数据校验和 • 执行客户端(client)的读写请求操作 • 通过心跳机制定期向NameNode汇报运行状态和所有块列表信息 • 在集群启动时DataNode向NameNode提供存储的Block块列表信息 |
理解了HDFS的几个核心概念后,HDFS总体架构就不难理解了。简单描述就是:HDFS采用Master(nameNode节点)/Slave(dataNode)的架构存储数据,主要由HDFS Client、NameNode、DataNode和Standby NameNode四部分组成,HDFS Client通过nameNode操作dataNode。
通过上面的介绍,也就清楚“为什么HDFS不适合存储小文件”了: 1、元数据信息存储在NameNode内存中,内存大小有限 |

下面,我们再介绍一下HDFS的写流程,了解一下写操作过程到底经历了什么。
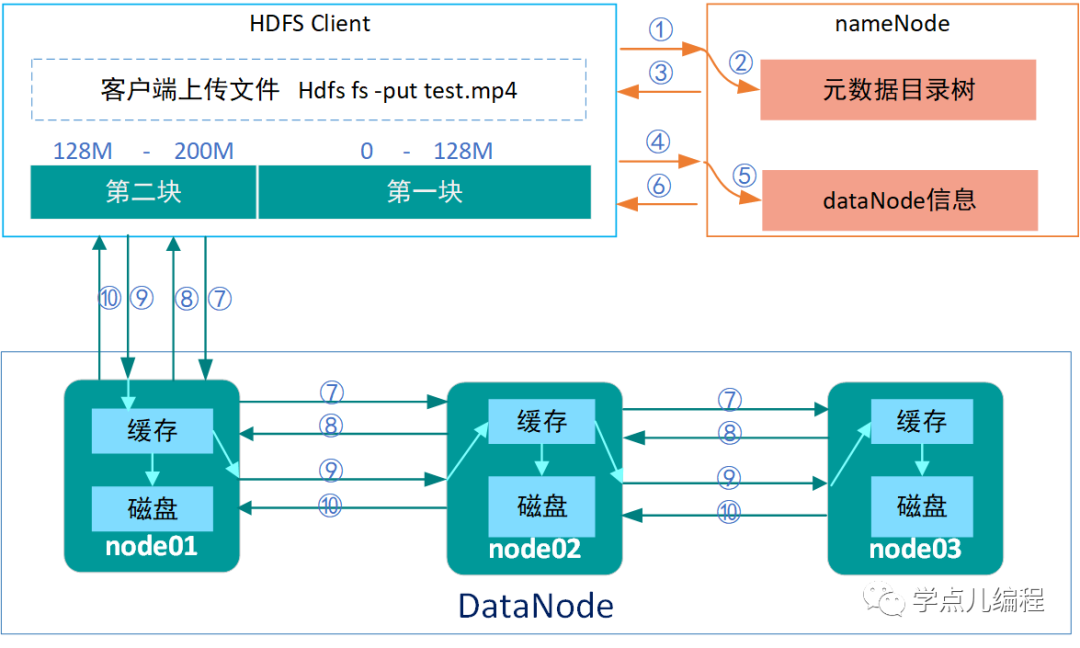
上面写流程(十个步骤)的解释如下(*认识HDFS的写文件过程):
①client客户端向nameNode发起上传文件请求(通过RPC调用)
通过DistributedFileSystem的create()方法指明一个预创建的文件的文件名
②nameNode检查“元数据目录树”,判断文件是否可以上传(是否有同名文件|是否有创建权限等)
③nameNode响应client客户端是否可以上传(若能上传能执行第④步 及后续步骤,同时namenode会为该文件创建一个新的记录)
DistributedFileSystem会返回一个FSDataOutputStream以供客户端写入数据,
FSDataOutputStream被封装为一个DFSOutputStream用于处理namenode与datanode之间的IO。
DFSOutputStream把待写入的数据分成包(packet), 放入一个中间队列——数据队列(data queue)中去。DataStreamer从数据队列中取数据,同时进入下面第④步(开始向namenode申请一个新的block来存放它已经取得的数据)。
理论清楚了,对于具体的代码,就很简单了(几行代码即可完成)
FileSystem fileSystem = FileSystem.get(new Configuration());
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("path"));BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(fsDataOutputStream));复制
④client客户端向nameNode发起第一块block如何存储的请求 (每一块会有相同的请求过程)
⑤nameNode查询dataNode信息(存活|远近|忙碌等状态)
⑥nameNode返回合适的dataNode信息给client客户端(假设是node01,node02,node03)
namenode选择一系列合适的datanode(个数由文件的replica数决定)构成一个管道线(pipeline),这里我们假设replica为3,所以管道线中就有三个datanode。
⑦⑧client客户端请求与最近的dataNode节点(假设为node01)建立传输通道,同时告知其还要传给node02和node03(node01和node02,node02和node03之间也会建立传输通道)。
接下来,DataOutputStream把数据流式的写入到管道线中的第一个datanode中,第一个datanode再把接收到的数据转到第二个datanode中,以此类推(直接到所有replica写完)。
⑨client客户端收到通道建立成功的消息后,开始向node01发送block1的数据,以一个个package(64k)为单位通过通道向node01写数据,node01收到数据会将其存在本地缓存中,一边向node02传数据,一边将缓存中的数据保存到磁盘上。
⑩客户端在传送数据时会有一个package的应答队列,各个副本都写完后node01每收到一个package后就向client客户端发回消息(node01不用等待node02发回应答信息才给客户端发送信息,客户端只保证node01收到了数据就行,后面的事它交给了node01)
上面是第一个block传输过程,该block在所有相关dataNode节点上都写完后,client客户端会告诉nameNode写完了,并再次请求nameNode上传第二个block,直到当前上传文件的所有block上传完成。整个文件都写完时Namenode会有一个提交操作,该该文件就被访问了。
写入过程中的其他逻辑:
(1)每写完一个数据块都会重新向nameNode申请合适的datanode列表(保证系统中datanode数据存储的均衡性)。
(2)不是每写完一个datanode就返回一个确认应答,而是直到最后一个datanode写入完毕后,统一返回应答包。如果某些datanode出现故障,那么返回的应答就是正常的datanode确认应答和故障datanode的故障异常。(所以:数据写入过程中,数据块的校验是在最后一个dataNode完成)。
(3)nameNode在选择上传副本的dataNode的逻辑:
综合考虑datanode的可靠性,写入带宽,读出带宽等因素。
默认情况下,在运行客户端的那个节点上存放第1个副本,如果客户端运行在集群之外,则随机选择一个节点存放第1块,但namenode会尽量选择那些情况好的datanode(存储不太满,当时不太忙,带宽比较高)。
第2个副本存放在与第1个副本所在机架不同的另一个机架上的datanode中(随机选择另一机架上的另一情况较好的datanode),
第3个副本存在与第2个副本相同机架但不同datanode的另一个datanode上。
所有有关块复制的决策统一由 NameNode 负责,NameNode 会周期性地接受集群中数据节点 DataNode 的心跳和块报告。一个心跳的到达表示这个数据节点是正常的。一个块报告包括该数据节点上所有块的列表。

下面,我们再介绍一下HDFS的读流程,了解一下读操作过程经历了什么。
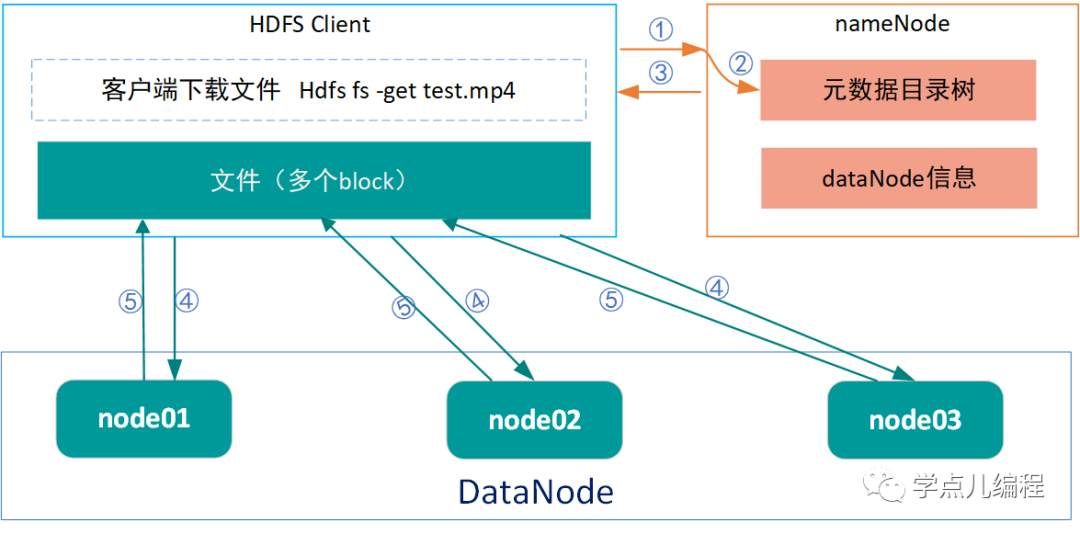
上面读流程(五个步骤)的解释如下(*认识HDFS的读文件过程):
①client客户端向nameNode发起下载文件请求(通过RPC调用)
②nameNode查询元数据信息及block位置信息
③nameNode响应client客户端,将数据所在的dataName信息返回给client客户端。
④client客户端根据数据所在的dataNode,挑选一台距离自己最近的dataNode,并向其发出下载文件的请求(若所需数据不在一台dataNode上保存,则分别向多台dataNode发出请求)。
⑤dataNode响应客户端请求,将数据返回给客户端。
从多个datanode获得的数据不断在客户端追加,形成完整的数据。
读取过程中的其他逻辑:
(1)nameNode返回给client客户端的dataNode信息中,包含每个block块的最佳dataNode。
(2)读取数据过程中,若与dataNode通信遇到错误,会尝试从该block块的另一个临近dataNode读取数据,同时会记住该故障dataNode,不会反复读取该节点上后续的block块。
(3)block块分散在集群中的所有datanode中,这种设计会使HDFS可扩展到大量的节点。同时,nameNode仅需要响应位置的请求(这些信息存储在内存中,非常高效),而无需响应数据请求,避免nameNode成为瓶颈。

HDFS集群中一般都存储着大量的数据,HDFS有一套稳固的高可用方案来确保不出现数据丢失或集群崩溃。我们一起分析一下HDFS的高可用原理:
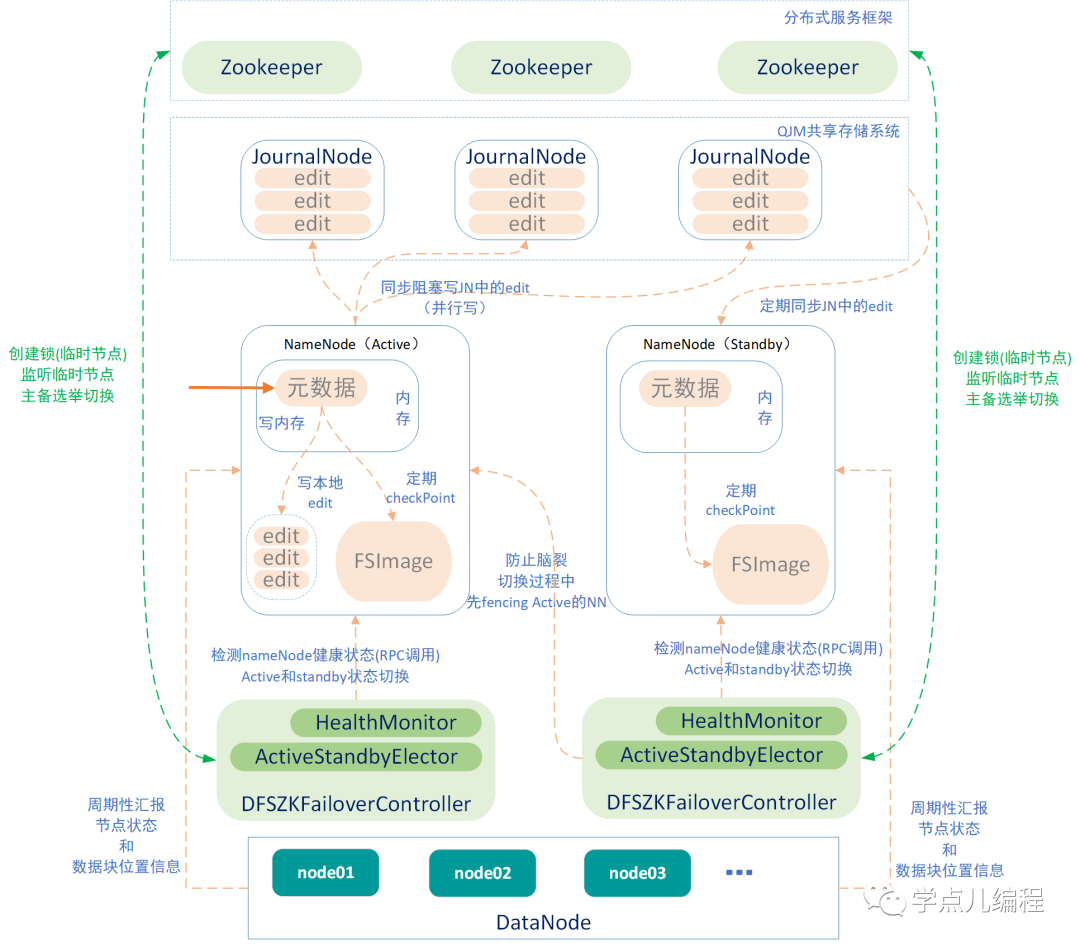
整个HDFS文件系统,nameNode如果挂掉,hadoop生态系统中依赖于HDFS的功能都不可用了。 而且集群重新启动的时间很可能会比较长的(和存储的文件数量成正比)。高可用的关键点就是nameNode节点。
通过上一篇:Hadoop之Hadoop的前世今生,适合什么场景?我们知道了hadoop各个版本间的区别。
在2.0之前只局限于离线MR批处理,2.0版本基于三个Journal Node集群(奇数台) 实现了QJM共享存储系统,负责存储edits日志文件。
基本概念扫盲: fsimage和eidts是nameNode两个非常重要的文件,fsimage和edits log文件是经过了序列化的,无法直接查看。
nameNode启动时候,会先将fsimage中的文件系统元数据信息加载到内存,然后根据eidts中的记录将内存中的元数据同步至最新状态;所以,这两个文件一旦损坏或丢失,将导致整个HDFS文件系统不可用。类似于数据库中的检查点,为了避免edits日志过大(会导致解析加载到内存中会很耗时),需要将fsimage和edits 日志文件合并成新的fsimage文件: |
下面我们从几个场景介绍nameNode高可用流程
1、元数据同步过程
我们把nameNode中存储的信息称为元数据,当client客户端的更新(添加/删除)请求来了后,nameNode中元数据同步过程如下:
| 1 | HDFS会同步向active nameNode 和 2个Journal Node 的磁盘上写edits日志文件,如果Journal Node集群中大多数节点都写成功了(上图中大多数节点为2台)后则会告诉namenode集群写成功了,(如果存在没写成功的节点,会从已写成功的节点上同步数据) |
| 2 | namenNode得到Journal Node集群写成功的消息后,会把更新同步到自己的内存中文件系统元数据。 |
| 3 | nameNode(active)会把元数据信息定期设置检查点,保存到磁盘的fsimage文件中。 |
| 4 | nameNode(standby)定期从Journal Node同步edits日志文件,形成文件系统元数据放到内存中。 注意,此时standby namenode不在磁盘上存储edits文件,但会定期根据内存中的元数据信息形成检查点,保存到磁盘的fsimage文件中。 即standby namenode不再存储edits,而Journal Node专门用于edits的分布式集群存储。 |
2、主备切换(active nameNode 和 standby nameNode的切换)
目标:active nameNode挂掉后,让 standby nameNode 切换为 active nameNode。
技术支撑:由主备切换控制器(DFSZKFailoverController)来实现,简称 ZKFC。
实现原理与切换流程:
(1)每个nameNode对应一个ZKFC控制器,是nameNode上独立存在的一个进程,ZKFC在启动时会构建HealthMonitor 和 ActiveStandbyElector 两个组件。
(2)HealthMonitor通过RPC远程调用,定期检测当前nameNode的健康状况,实现active和standby的状态切换(各个nameNode节点上的ActiveStandbyElector会同时向zookeeper写一个相同的临时节点,谁先写成功谁就是active节点,没写成功的就会standby节点)。
(3)ZK会一直监听该临时节点(即:实时监控active节点的存活状态)。成功写临时节点的服务器挂掉后(服务器和zookeeper之间的心跳就中断了),该临时节点会自动删除。当临时节点删除后standby的ActiveStandbyElector会立即写入该临时节点成为active。
(4)另一种情况:运行过程中,如果HealthMonitor检测当前nameNode的健康状况异常时,会告诉ZKFC控制器,ZKFC会调用ActiveStandbyElector组件,ActiveStandbyElector会发起一次选举。由于active nameNode异常不能参与选举了,则此时的standby nameNode就变成active nameNode了。
3、nameNode的脑裂现象
脑残成因:由于namenode的负载过高 或 JAVA进行全量的垃圾回收(Full GC) 或 网络抖动时,可能会造成服务器 和zookeeper之间的心跳就不能正常发送了,如果这个时间持续比较长,就会出现假死的情况。 其实还活着,外界认为他挂掉了。
这个时候zookeeper就会认为这个服务器挂掉了,此时如果standby被选为active,就出现两个 active的情况了,就是双主的情况(也就是脑裂的现象)。
脑裂影响:影响数据强一致,造成数据混乱。
避免方式:通过fencing隔离机制进行设置。会依次执行以下三种操作来避免脑裂的出现:
(1)新的active节点会通过SSH远程到老的active上,通过active转换为standby的方法进行转换,将老的active转换为standby。
(2)如果上面的转换失败了,会通过SSH 使用 kill -9 把namenode的进程杀掉。
(3)如果kill -9也失败了,在老active上提供配置一个关机脚本 ,前两种方法都失效时,调用该脚本强行关闭服务。
4、HDFS中Secondary NameNode和Standby NameNde的区别
先给出本质区别:
Secondary NameNode是非HA(也就是Hadoop1.X中的概念),Standby NameNode是HA(Hadoop2.X中的概念)。
Secondary NameNode:HDFS单NameNode节点的情况下(非高可用HA),Secondary NameNode负责每隔一段时间(例如:1小时)将旧的fsimage文件和edits log文件merge成新的fsimage并替换,即为NameNode 合并编辑日志edits log,减少 NameNode 启动时间;非实时merge,一旦NameNode挂了,可能会导致元数据丢失。
Standby NameNde:HDFS主从架构情况下(即高可用HA,生产环境都是用HA的),Active NameNode和Standby NameNode,后者会实时同步前者的fsimage,并将merge后的新fsimage文件替换前者中旧的fsimage文件;实时merge,一旦前者挂了,后者能够马上顶上,不会出现元数据丢失。
补充几个知识点:
1、HDFS数据完整性
写入时在每块都会计算一个校验和,dataNode会存储数据块和检验和,最后一个dataNode负责验证该检验和。另外,dataNode后台线程定期检测自己的数据块的,如果出现坏块则通过心跳定期向nameNode汇报,nameNode会标记损坏的数据块,并从其他副本复制一块相同数据,然后让datanode删除原来的坏块。
1、集群中加入和删除datanode
| 加入新节点 | 1、在新的机器上拷贝一份包含配置文件的hadoop安装包(根据情况可能要修改一下相关配置文件) 2、单独启动datanode:sbin/hadoop-daemon.sh start datanode 启动后namenode会感知到 3、如果该节点也是nodeManager,则通过下面命令启动一下 sbin/yarn-daemon.sh start nodeManager |
| 删除坏节点 | 1、将需要移除的datanode的主机名或者IP加入到NameNode的黑名单加入黑名单方法: 2、修改NameNode的hdfs-site.xml文件,设置dfs.hosts.exclude配置的值为需要移除的datanode的主机名或者IP 3、更新黑名单 bin/hadoop dfsadmin –refreshNodes |
4、HDFS“冷” 数据处理
“冷”数据文件是指:很长时间没有被访问过的数据文件(如半年内)
处理方法:
高压缩比算法进行压缩,如Gzip或bzip2
小文件合并


