




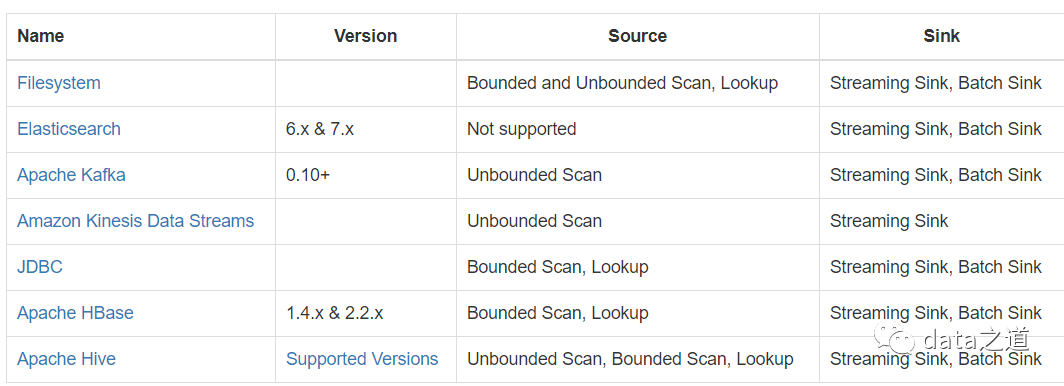
背景
分区并发控制
scan.partition.column: 分区字段,必须是日期、时间戳、数字类型.
scan.partition.num: 分区总数.
scan.partition.lower-bound: 分区字段最小值.
scan.partition.upper-bound: 分区字段最大值.
Flink根据配置的column、lower-bound、upper-bound属性值在SQL里加上对应的查询条件:

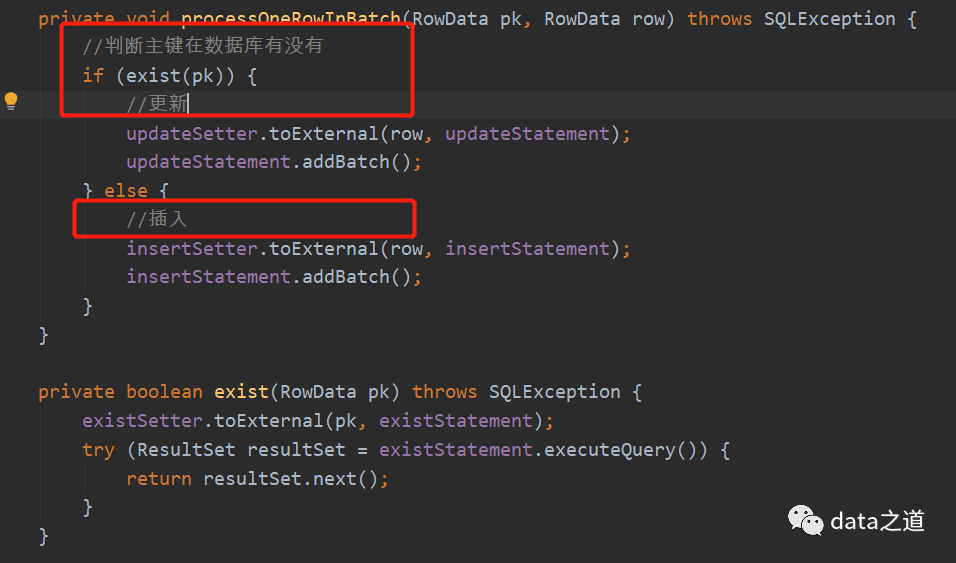
写入一致性
周期性增量查询
while (!this.taskCanceled && !format.reachedEnd()) {OT returned;if ((returned = format.nextRecord(reuse)) != null) {output.collect(returned);}}
reachedEnd和nextRecord方法的实现:
public boolean reachedEnd() throws IOException {//判断还有没有数据return !hasNext;}public RowData nextRecord(RowData reuse) throws IOException {try {if (!hasNext) {return null;}RowData row = rowConverter.toInternal(resultSet);//update hasNext after we've read the recordhasNext = resultSet.next();return row;} catch (SQLException se) {throw new IOException("Couldn't read data - " + se.getMessage(), se);} catch (NullPointerException npe) {throw new IOException("Couldn't access resultSet", npe);}}
public boolean reachedEnd() throws IOException{if (hasNext) {return false;} else {//轮询查数据if (isPolling()) {try {//轮询间隔TimeUnit.MILLISECONDS.sleep(getPollingInterval());resultSet.close()//从LongMaximum累加器里获取保存的最大值,然后查询数据queryForPolling(endLocationAccumulator.getLocalValue().toString());return false;} catch (SQLException e) {}}return true;}}//根据最大值,重新查询数据protected void queryForPolling(String startLocation) throws SQLException {boolean isNumber = StringUtils.isNumeric(startLocation);//根据增量字段的类型,转换并设置到PreparedStatementswitch (type) {case TIMESTAMP:Timestamp ts = isNumber ? new Timestamp(Long.parseLong(startLocation)) : Timestamp.valueOf(startLocation);pstmt.setTimestamp(1, ts);break;case DATE:Date date = isNumber ? new Date(Long.parseLong(startLocation)) : Date.valueOf(startLocation);pstmt.setDate(1, date);break;default:if(isNumber){pstmt.setLong(1, Long.parseLong(startLocation));}else {pstmt.setString(1, startLocation);}}//执行查询sqlresultSet = ps.executeQuery();//移动ResultSet游标hasNext = resultSet.next();}public RowData nextRecord(RowData reuse) throws IOException {try {if (!hasNext) {return null;}RowData row = rowConverter.toInternal(resultSet);//获取增量字段的值Object obj = resultSet.getObject(incrementColumn);if(obj != null) {if((obj instanceof java.util.Date|| obj.getClass().getSimpleName().toUpperCase().contains(ColumnType.TIMESTAMP.name())) ) {obj = resultSet.getTimestamp(incrementColumn).getTime();}//将增量字段值保存到LongMaximum累加器endLocationAccumulator.add(new BigInteger(String.valueOf(obj)));}
//update hasNext after we've read the recordhasNext = resultSet.next();return row;} catch (SQLException se) {throw new IOException("Couldn't read data - " + se.getMessage(), se);} catch (NullPointerException npe) {throw new IOException("Couldn't access resultSet", npe);}}
文章转载自data之道,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
