




前言
昨天和前天在搭建 mask-rcnn 环境的时候发现发现无论怎么搭环境都会报下面一个错:
AttributeError: module 'tensorflow' has no attribute 'log'复制
后来在 github 里的 issue 中找到了答案,就是 tensorflow 的版本过高了(高于了 2.0).
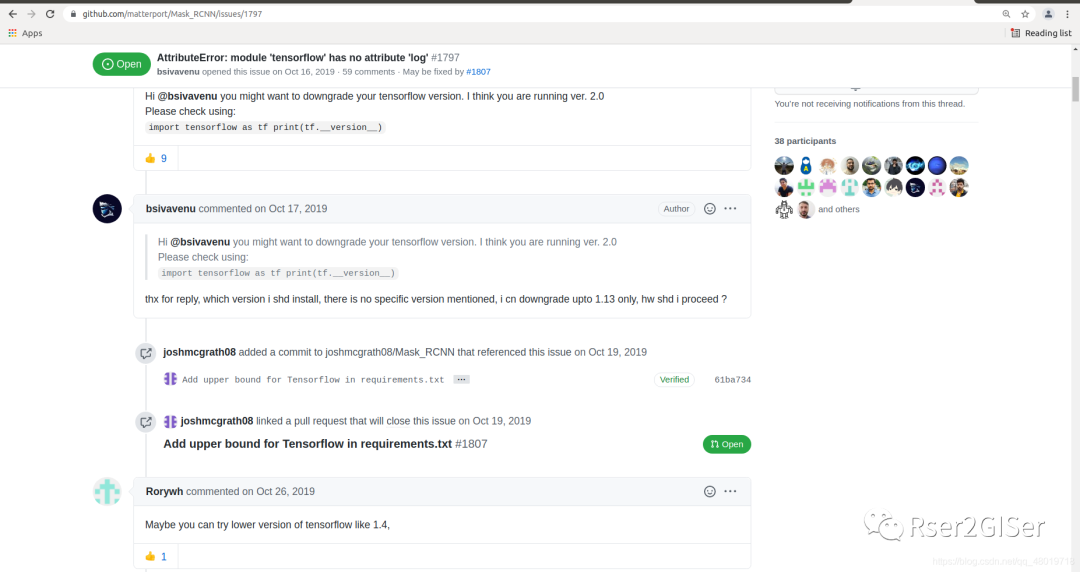
这就带来了一个问题, tensorflow 需要 degrade 到 1.3.0 到 2.0 之间的版本,所以我想按照指示将其 degrade 到 1.15.0 ,查官网,发现 tensorflow 1.15.0 对应的 Python、CUDA 和 CUDNN 的版本对应的关系。
选择 1.15.0 是因为没法选择 CUDA 9.0 不支持 Ubuntu 18.04 的版本,所以换了 1.15.0
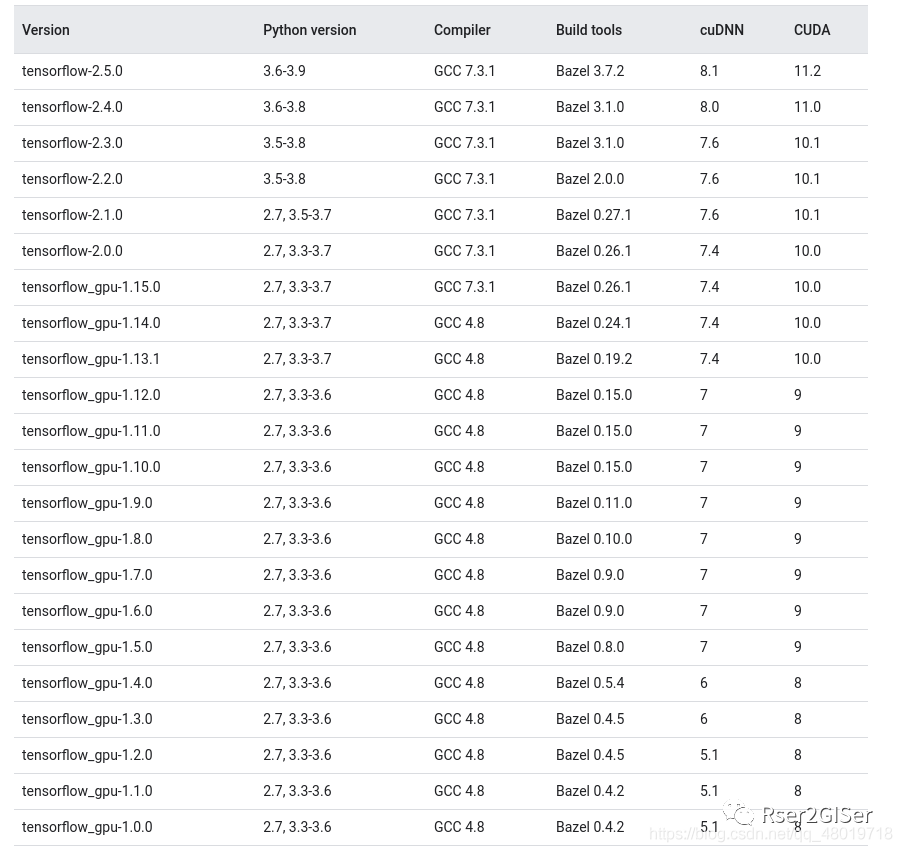
看到 tensorflow 1.15.0 对应的 Python 版本为 3.6, 对应的 CUDA 为 10.0,CUDNN 为7.4 ,所以会出现多个版本的 Python 和多个版本的 CUDA、CUDNN 共存的问题。
多个版本的 Python 共存的问题
说实话,一开始我以为要去 anaconda 去多下几个发行版,后来偶然翻 issue 的时候发现 conda create -n env-name python=x.x.x
的时候可以指定 python 的版本(其实一开始就知道能指定 python 版本,但是不知道这样能不能算数…),也就是说, anaconda 创建 virtualenv 的时候能够自动下载 python 对应的版本,所以,无需再下 anaconda 对应的发行版,只需要让 anaconda 自动去下相应版本的 python 就可以了(即 conda 创建虚拟环境的时候会自动安装对应的 python 版本)。
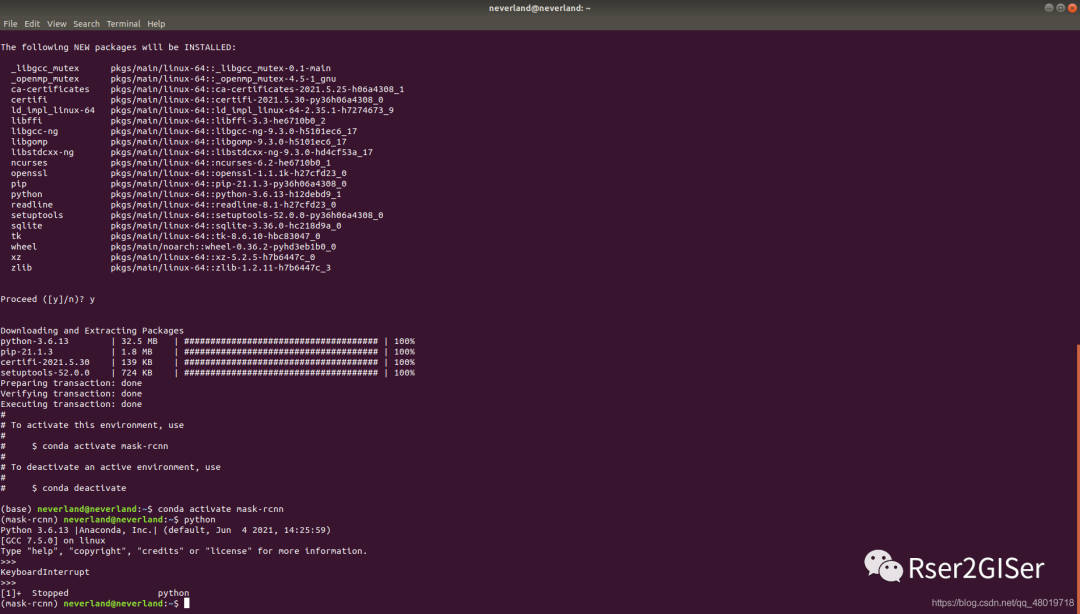
我尝试激活了一下 mask-rcnn
的虚拟环境,并且启动 python 的 env,发现 python 的版本为 3.6.13
即是我要的 python 3.6 的版本。
多个 CUDA 共存的问题
在这我查找的一段资料原文是:
Installing multiple versions won’t cause any of the previous versions to get overwritten, so no need to worry. Each version you install will overwrite the configurations that cause the operating system to use a certain version, but by default they all get installed under /usr/local in separate directories by their version numbers.
即,安装多个 CUDA 并不会导致先前安装的版本被覆盖,而是覆盖了使用的权限——也就是说,你需要用哪个版本的 CUDA 的时候就去给哪个 CUDA 权限就可以了!
所以只是安装 CUDA 的问题,然后再给它指派软链接的事情。
首先下载 CUDA 10.0 ,下载的时候发现 11.0 好像不支持拉下本地文件,而是一定要用 wget
命令,而 10.0 是支持拉下本地文件解压后下载的。可以用 runfile
或者 deb
下载。
所以就用 deb
方式下载吧,比较 dpkg
比较熟练(hhhhhh)。
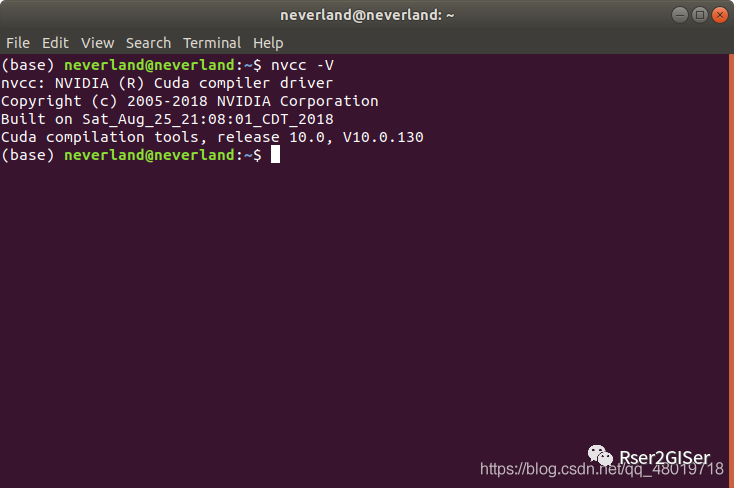
事实上,CUDA 安装几个都是无所谓的,只要在运行的时候选择好需要的 CUDA 即可, CUDA 又可以分为 runtime 和 drivertime,即 nvcc -V
获取到的是 runtime 的 cuda,而 nvidia-smi
获取到的是显卡驱动自带的链接,
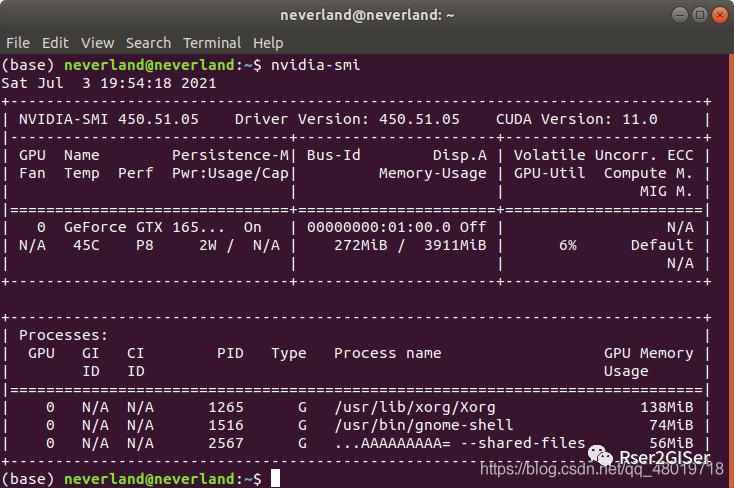
而 nvcc -v
才是我们需要运行时候需要的 cuda 的版本。
一般来说下载完 cuda 后, 在 /usr/local
下会有 cuda 对应版本的文件夹,例如:
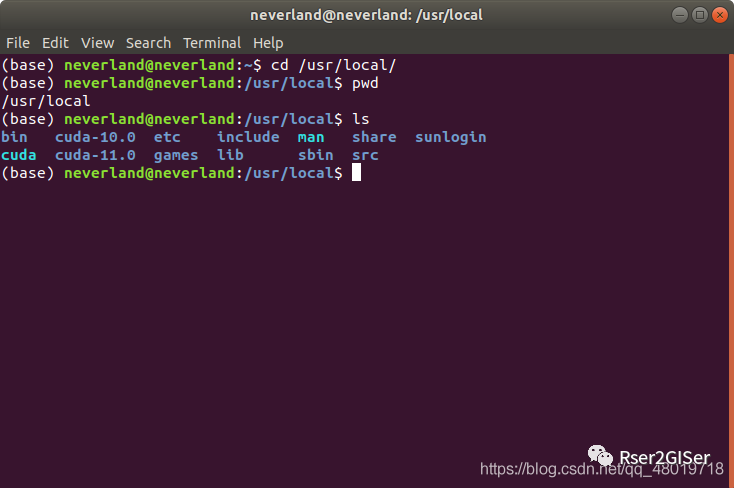
可以看到这里面有 cuda 10.0,cuda 11.0,而由于我需要跑 mask-RCNN
时候的版本是 tensorflow-gpu==1.15.0
,其对应的 cuda 版本为 10.0,所以我需要取消原来的 cuda 11.0 的软链接,然后将 10.0 给链接上,链接的方式为:
sudo rm -rf cuda
sudo ln -s /usr/local/cuda-<verision> /usr/local/cuda复制
实际上,想要对 cuda 进行软链接。只需要先移除 /usr/local
下的 cuda 文件夹,然后用 ln
命令对 cuda 特定的版本进行软链接即可。
唯一无法确定的是 CUDA 安装时候的环境变量的导出问题,网上众说纷纭,官网也没找到合适的答案,只能等待以后慢慢理解了,下面挂一下目前的环境变量导出的方法。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.0/lib64
export PATH=$PATH:/usr/local/cuda-10.0/bin复制
CUDNN 的安装
CUDNN 是深层卷积神经网络加速的工具,对于 CUDNN 的安装,其实之前的公众号或者博客也已经讲过了,用 tar
解压的方式其实很简单,其实就是把相应的 *.h
文件拷贝到 cuda 里,然后赋予权限即可。例如:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*复制
就是将 library 文件加压后的 cuda 文件中的 cudnn.h
复制到 cuda/inlcude
里面,把 lib64
里面的 libcudnn*
复制到 lib64
里面去,就安装成功了。然后可以使用下面的方法查看 CUDNN 的版本
查看 CUDNN 的方法
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2复制
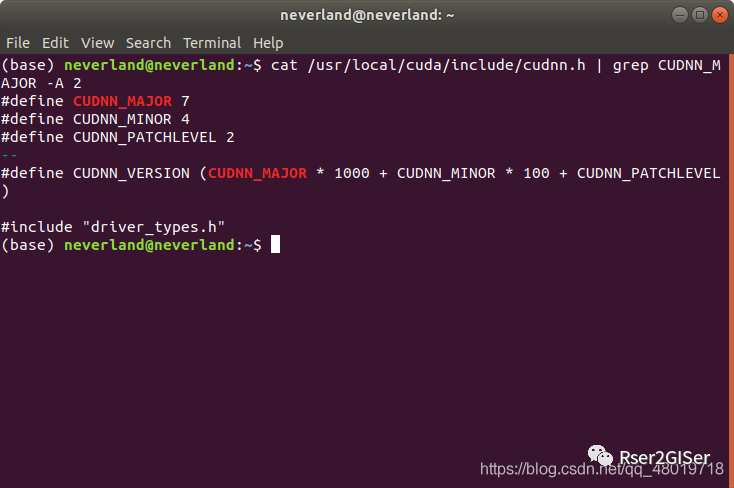
例如,这里面就是 7.4.2
的版本。
关于 Mask-RCNN env 的搭建
Mask-RCNN 实际上也是目标检测中的一种算法,它就是所谓的 fast-rcnn 再进行 mask,我预计我后期的 target 重点在于 training 还有 geocode,即在训练出一种泛化的权重下然后进行 extraction。
关于 Mask-RCNN 的搭建,坑真的好多,一方面自己煞笔了一晚上 ,另一方面,它就是 bug 太多了。
,另一方面,它就是 bug 太多了。
首先,在上面已经讲了可以用 conda create -n mask-rcnn python=3.6
创建一个虚拟环境,专门用来一个深度学习框架的使用,然后,需要把 code 给拉下来,
numpy
scipy
Pillow
cython
matplotlib
scikit-image
keras>=2.0.8
opencv-python
h5py
tensorflow-gpu==1.15.0
keras
imgaug
jupyter复制
这是我里面 requirements.txt
需要的东西,结果最让我没想到的是,pip install
和 conda install
也存在着区别,pip install
安装着里面相应的库的同时也加入一些必要的依赖库的安装,但是conda install
也安装,同时,它还安装了 cuda-toolkit
还有 CUDNN
的安装,真的是装到气吐血,一堆错误。最关键的一开始还把 tensorflow-gpu==1.15.0
装成了 tensorflow-gpu==1.5.0
,然后一直报错
h5py 的 error,版本太高,需要 degrade 到 version
AttributeError: ‘str’ object has no attribute ‘decode’
pip install h5py==2.10.0复制
tensorflow 的 error
ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
出现这个问题很可能是 tf 的版本和 CUDA 和 CUDNN 没有对应,我出现这个问题就是因为装错了 tf 的版本(曹)。
3. tensorflow 的 error
Error : Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above
出现这个问题可能是 CUDNN 没安装正确,但是我用 cat 命令检查过 CUDNN 的版本了,学长建议我用 conda install 代替 pip install 后来在安装的过程中我确实看到了 cuda-toolkit10.0 还有 CUDNN,但是具体是不是本地不需要装,无法确定,学长建议我还是装一下,反正现在装的挺熟练了....。
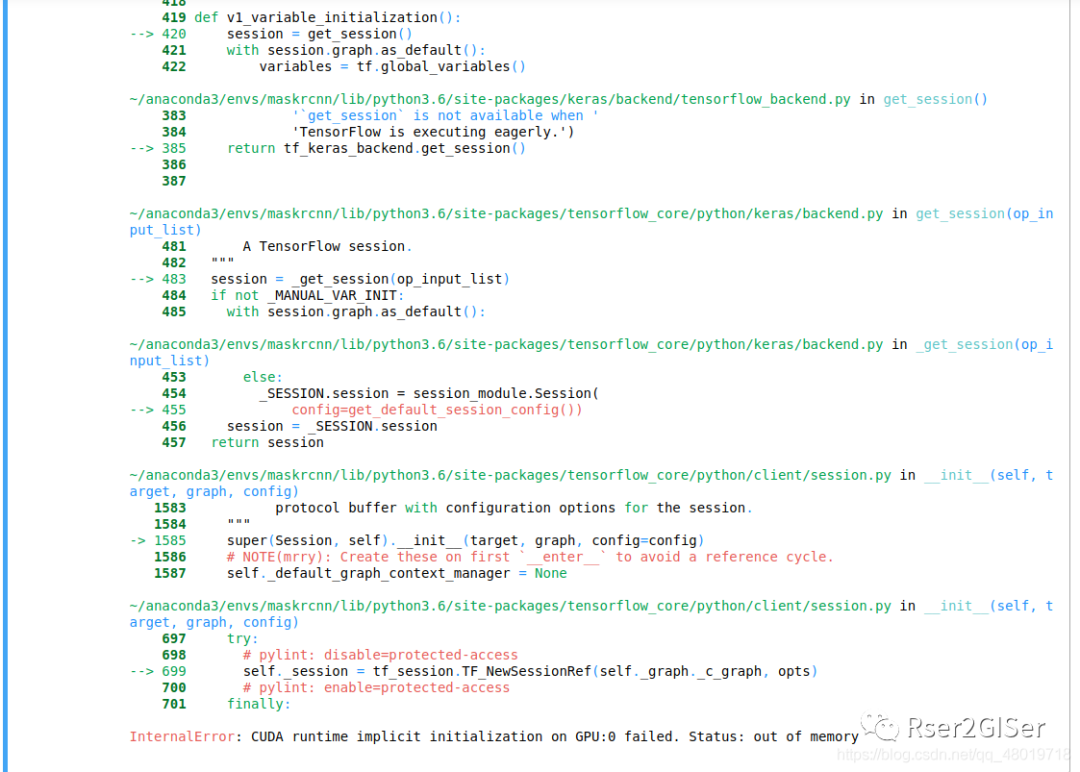
这是终于安装成功的结果了,tf-gpu
正确各种错误也排完了,但是由于电脑显存的问题,无法 inference
,所以…后续租服务器或者用 colab 或者用 pytorch 框架去跑,学长和我说 batch-size
设成 1 勉强能 training,那没办法了,深度学习就是个吃显卡的怪兽~-~
