




对业务数据进行实时同步、实时数据分析的场景越来越多,传统手段用表自动更新审计列(如updated_time)增量抽取数据,这种实现方案需定时调度抽取程序,而且在增量数据大的情况下对数据库也有很大查询压力。本文主要介绍阿里开源的订阅binlog中间件,希望能帮助大家在此基础开发出实时同步程序。
Canal介绍
canal是基于Mysql binlog实现的增量日志解析中间件,提供增量数据订阅&消费功能,要求mysql要开启binlog写入功能,建议配置binlog模式为row。原理比较容易理解:
canal模拟mysql slave和master的交互协议,自己伪装成slave,向mysql master发送dump协议
mysql master收到dump请求后,开始推送binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
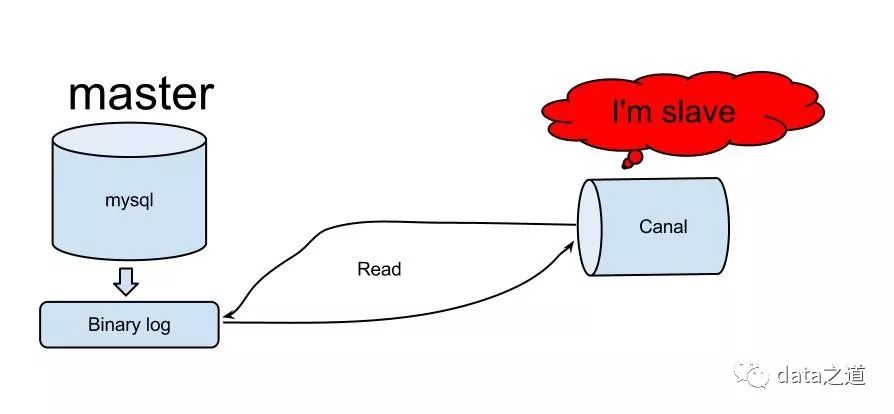
Canal在功能划分上由两部分组成:server端和client端,server负责和master交互、维护元数据;client是客户端api,client和server通过Netty进行socket通信,比如向server发送get请求,会调用server的getWithoutAck方法。
server可以启动多个instance,一个instance负责和一个mysql交互,instance表现为mysql slave实例,接收client请求(subcripition\get\ack),并负责维护元数据(比如当前消费到的binglog file、binlog offset);一个canal client实例只能连接到一个instance:
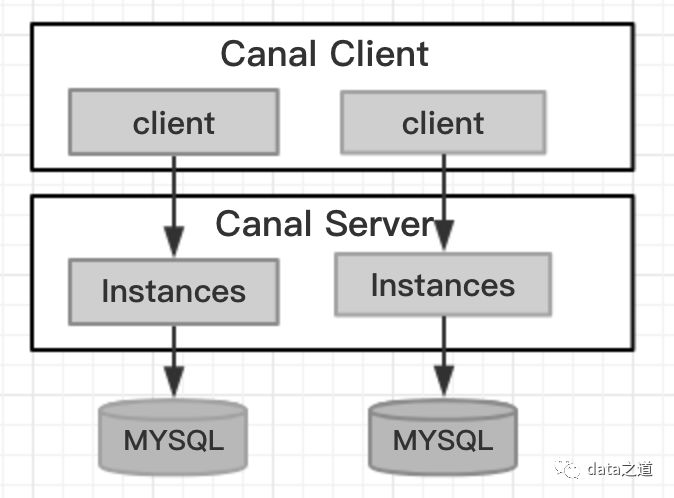
Canal Server有三种配置文件:
1、系统级配置$CANAL_HOME/conf/canal.properties:端口号、连接的zk信息、将内存中cursor刷新到zookeeper的定时策略、实例配置文件自动扫描间隔等;全局实例配置:配置加载方式、是否延迟初始化、spring配置文件路径。延迟启动instance指的是首次client subscribe时启动,否则在server启动时启动。
2、实例级配置$CANAL_HOME/conf/$INSTANCE/instance.properties:配置mysql的slaveId、mysql master信息、认证用户名/密码等
3、spring容器配置$CANAL_HOME/conf/spring:以spring方式(默认)启动canal实例时,spring相关的配置文件。client消费位点的管理有三种模式:
内存模式:位点存放在内存里,重启后会丢失,对应配置文件memory-instance.xml
文件模式:位点存放在文件里,不支持HA机制(不能多个server共享数据),对应配置文件file-instance.xml
zookeeper模式:位点用zk管理,先写内存,定时刷新到zookeeper,保证数据在集群内共享,对应配置文件default-instance.xml
Server部署
1、下载解压canal二进制压缩包
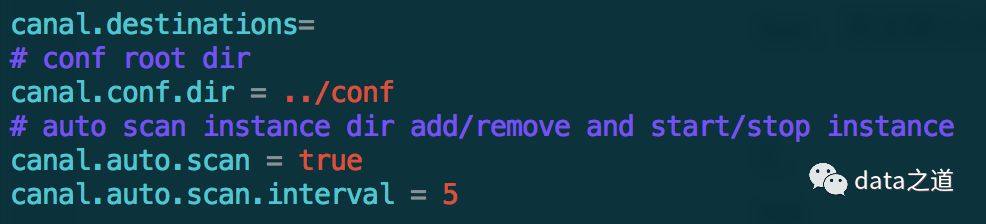
2、server端全局配置,修改canal.properties:
配置canal启动的端口号、连接的zookeeper、数据刷新到zookeeper的频率:

配置全局instance使用spring default加载方式、全局spring配置方式的组件文件:

开启destination自动扫描,扫描conf下的文件夹,根据变化自动触发add/remover/reload destination,默认间隔5秒扫描一次:
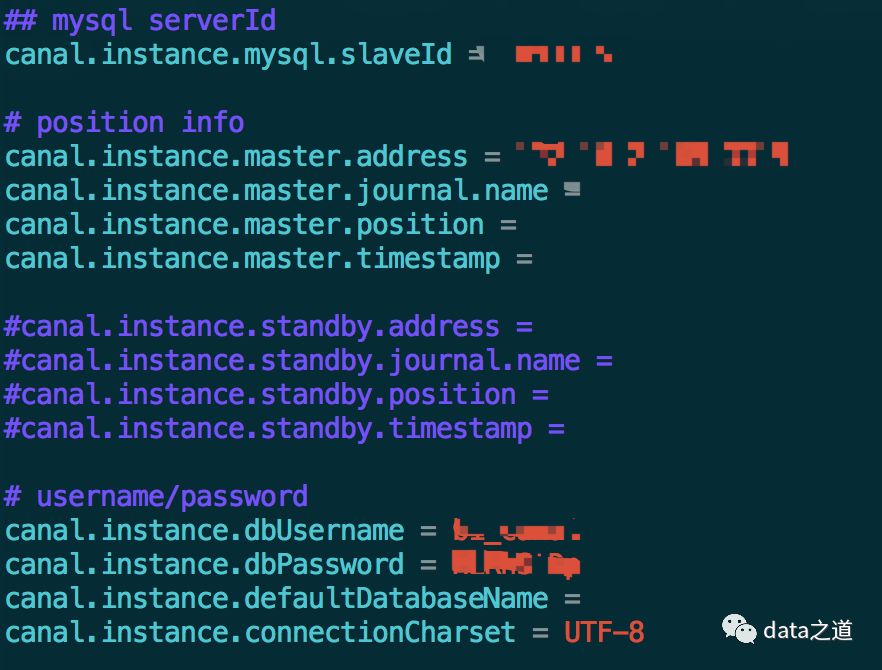
3、instance配置
在conf下创建test/instance.properties 文件,如2描述,不需要重启服务就可以自动启动新增instance,instance名是文件夹名。
配置mysql slaveId、mysql master地址和端口、mysql用户名和密码:
4、启动canal server
bin/startup.sh
5、确认server启动
可通过zookeeper节点信息,了解当前instance的工作节点:
get /otter/canal/destinations/${instance}/running
HA
server和client支持用zookeeper实现HA,会把当前消费到的mysql binlog、position持久化到zk,client端要配置HA,那么server端必须也配置HA。整个HA实现机制主要依赖zookeeper的watcher和EPHEMERAL特性。只要在canal.properties配置了zookeeper集群连接信息,server端就会自动启用HA。
canal server: 在集群模式下,可能会有多个canal server共同处理同一个destination,为了减少对mysql dump的请求,不同server上的同一个instance要求同一时间只能有一个处于running,其他的处于standby状态,其实现原理:
canal server要启动某个canal instance时都先向zk进行一次尝试启动判断(创建running临时节点,谁创建成功谁启动运行)
创建节点成功的server就启动对应的instance,没有创建成功的就处于standby
所有server都监听第一步创建的zk节点(监听runing节点),一旦监听到节点被删除(即之前active的instance出现异常)就重复步骤1、尝试启动instance
在zookeeper上查看test instance当前运行的server:

canal client: 在client HA模式下,同一时刻只能由一个canal client进行get/ack/rollback操作,原理类似server端HA机制。client在连接server端时,有以下操作:
1、ZkClient订阅监听/otter/canal/destinations/{destination}/10001/running节点,这个节点内有当前运行的client信息。当监控到节点数据变化或删除时,会重新在zk上创建running节点:
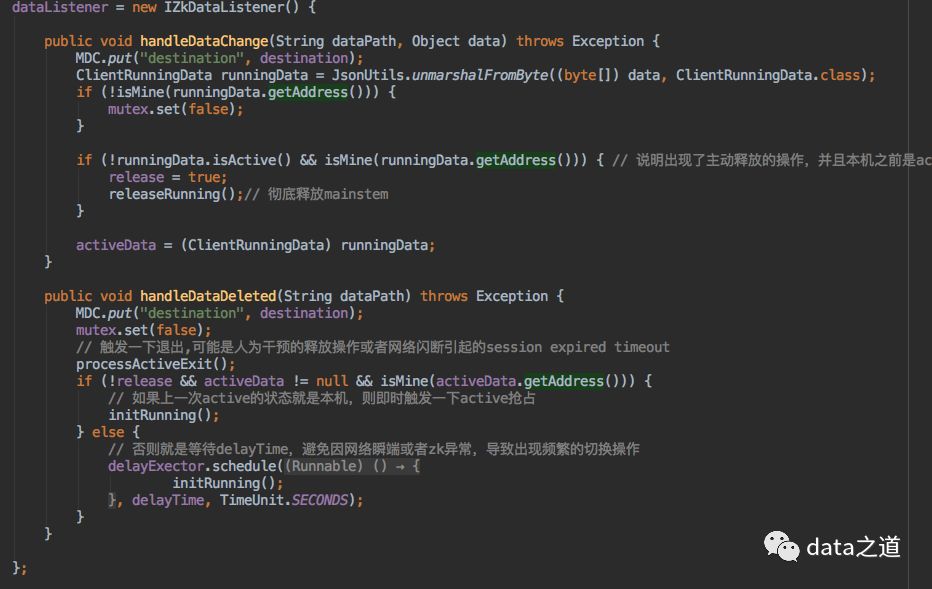
2、创建running临时节点代码:
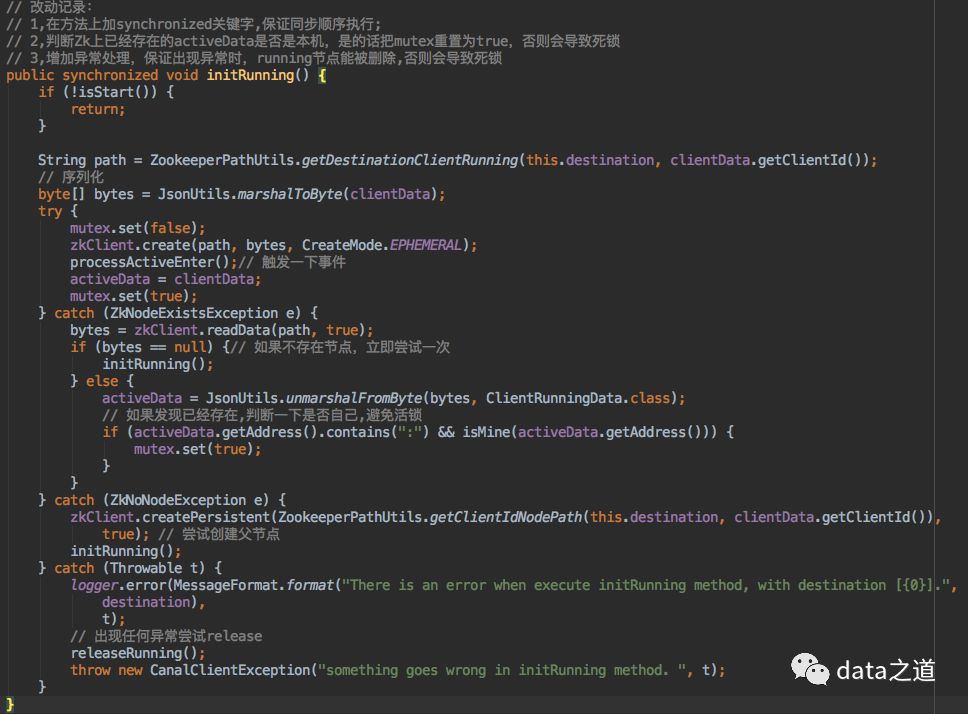
3、如果创建runing节点成功,设置锁状态为true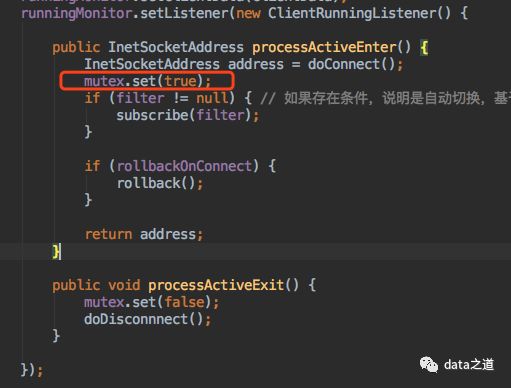 connector进行subscribe、unsubscribe、getWithoutAck、ack、rollback等操作时都有前置判断:进行锁状态判断,这个锁是阻塞锁,只有值是true时才继续操作,false会阻塞操作
connector进行subscribe、unsubscribe、getWithoutAck、ack、rollback等操作时都有前置判断:进行锁状态判断,这个锁是阻塞锁,只有值是true时才继续操作,false会阻塞操作
首次dump binlog程序优化
可以为每个instance设置起始binlog文件、起始binlog偏移量、起始binlog时间戳,其首次dump binlog位置的顺序优先级:binlog file + postition > binlog file + timestamp > binlog file + 4(binlog开始offset) > timestamp。如果没有设置以上起始信息(binlog文件、偏移量、时间戳),会用"show master status"命令获取当前binlog位置。
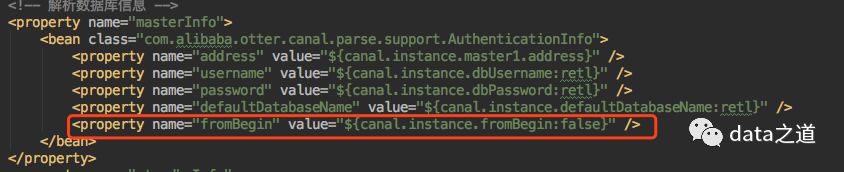
但有的场景需要从最早的binlog消费,这要求先手动查mysql最早binlog文件,然后再在instance.properties配置文件里设置“起始binlog文件”参数值,其过程还是比较繁琐,解决方案是在instance配置文件增加canal.instance.fromBegin参数,修改的核心代码:
1、AuthenticationInfo对象增加fromBegin参数,如果fromBegin=true,表示从最早的binlog开始消费
2、MysqlEventParser增加判断条件代码:
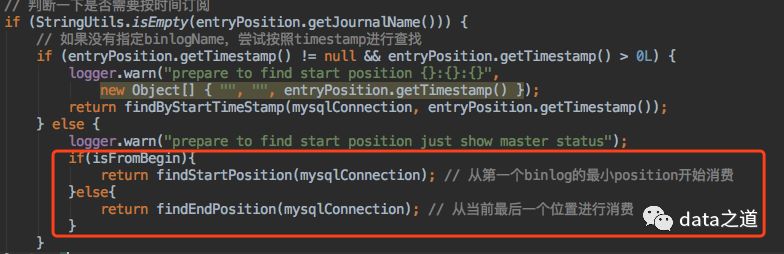
findStartPosition内部用"show binlog events limit 1"命令查询最早binlog位置
3、spring配置文件中的AuthenticationInfo bean增加属性:
Client端开发
a.创建链接,可以直接指定zookeeper地址和instance name,canal client会自动从zookeeper中的running节点,获取当前服务的工作节点:
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", "${instance}", "", "");
链接成功后,canal server会在zookeeper记录当前正在工作的canal client信息,比如客户端ip、端口信息等
b. 和canal server建立连接:
connector.connect();
c. 订阅消费指定的数据库和表,重复订阅时会更新对应的filter信息。如果订阅的是空,会直接使用canal server服务端配置的filter信息:
connector.subscribe("TEST.t_table");
d. 尝试拿batchSize条记录,有多少取多少,但不会阻塞等待一直拿到batchSize条记录才返回:
connector.getWithoutAck(batchSize);
e. 进行batch id的确认。确认之后,小于等于此 batchId 的 Message 都会被确认:
connector.ack(messageId)
f. 回滚到未进行ack的地方,指定回滚具体的batchId:
rollback(messageId)
问题
在实际开发中需要注意的一些点:
重复消费binlog问题,client端ack后server端可能没有及时把position持久化到ZK
HA机制同一时刻一个instance只能被一个client请求,如果确实需要多个client消费同一个instance,怎么处理?
本文为原创,欢迎分享到朋友圈。
