MySQL InnoDB存储引擎的Adaptive Hash Index通过缓存查询条件和数据页的对应关系实现了快速定位符合条件的数据,极大提升了优势场景下的系统性能。
Adaptive Hash Index(AHI)是MySQL InnoDB存储引擎的一个重要特性,通过该特性,系统在某些场景下,可以实现性能的大幅度提升。这一特性从MySQL5.5版本提供该特性以来,官方也一直在持续优化和完善,这次的分享我们就来详细了解一下这个特性,使大家对它有更为深入和全面的认识。
1.1 Adaptive Hash Index(AHI)简介自适应哈希索引,是InnoDB存储引擎为了加速大表单点查询而研发的一个特性。其核心思想就是通过缓存频繁查询的键值和其在B树中的对应信息来直接定位数据页,达到节省从根节点寻路定位的开销并提升查询性能的目的。MySQL 5.5 版本开始提供AHI特性,并在后续版本持续改进。在最新的8.0.33版本中依然将该特性默认开启。

而在Klustron分布式数据库的存储节点1.2版本,采用的是MySQL8.0.26版本,可以通过配置打开AHI。以下是Klustron分布式数据库的整体架构图: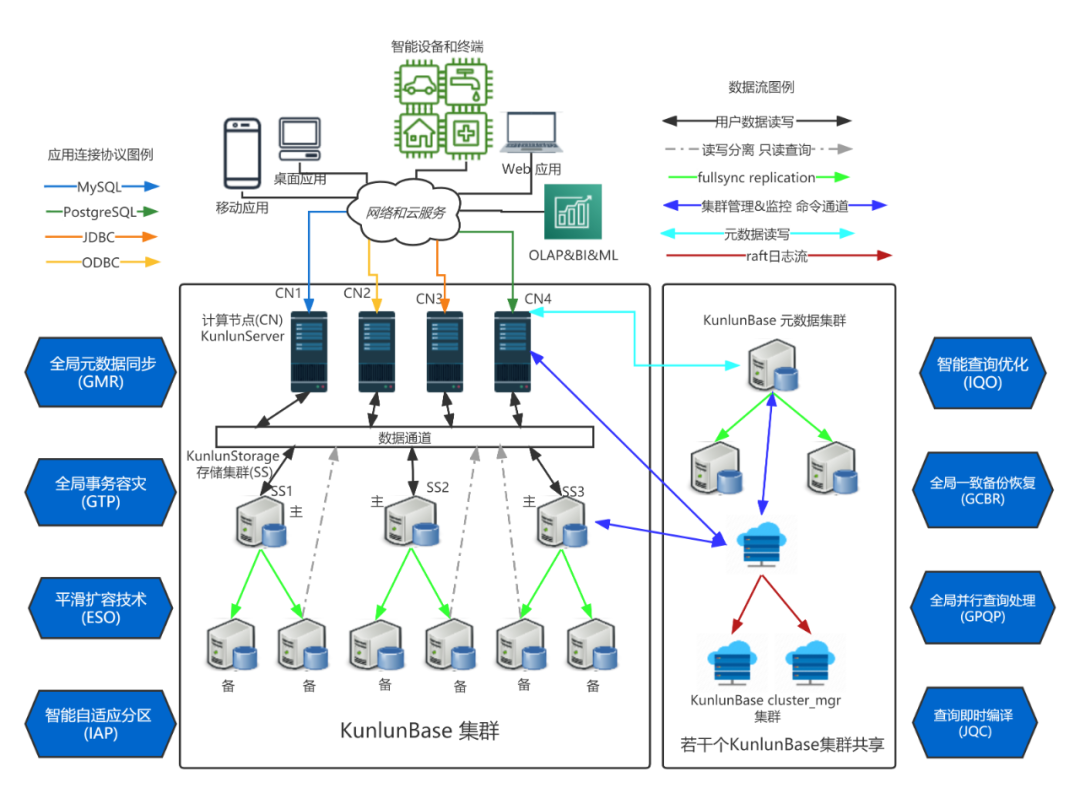
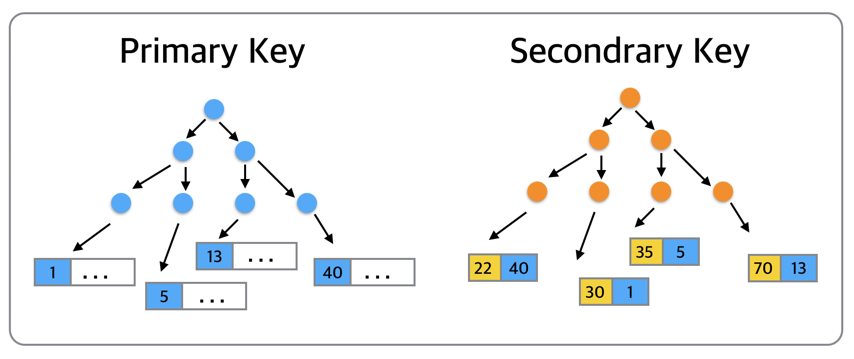
首先,我们来看一下上图中两个InnoDB内部的B树结构,左边的primary key主键索引,右边是secondary key二级索引。当我们需要找到主键值为5的记录时,就需要从主键索引B数的根节点开始,一直搜索到叶子,找到最下面的左边第二页,然后定位到记录(5…)。而当我们想要查找二级索引键值为35的那条记录的时候,就会先搜索左边的二级索引B树,然后定位到(35,5)这条二级索引记录,再通过对应的主键5到左边的主键索引中找到(5…)这条完整的数据记录。而如下图所示,AHI通过建立主键5到数据所在数据页的hash索引,可以直接定位到记录(5…)所在的数据页,也就是左边数第二个数据页。如此,在查找记录的时候就省略了从根节点到叶子节点的搜索过程。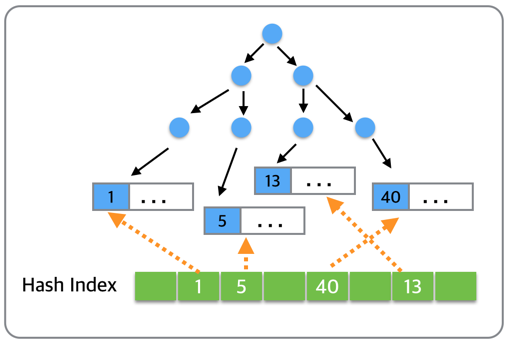
如下图所示,AHI的主要数据结构是多个哈希表,可以看做它是B+树索引的hash索引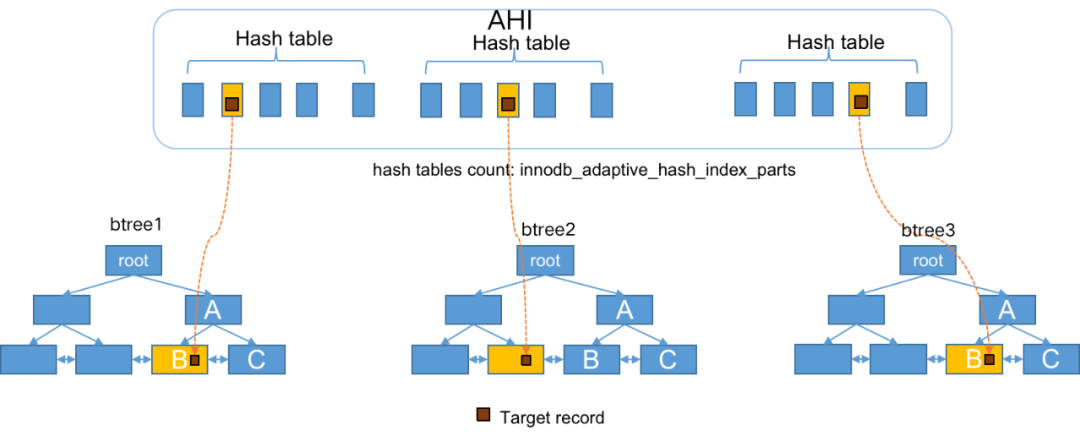
•通过参数innodb_adaptive_hash_index_parts指定分区(哈希表)个数•条件2:索引上的某个查询条件被使用>100次(index->search_info)•条件3:索引上的某个叶子数据页被经常查询(次数超过该页记录数的1/16)•其他条件:没有为该数据页构建索引,或有数据变化等•索引上的某个查询条件符合常用模式(index->search_info)•根据查询条件生成hash值并找到对应记录所在的物理页AHI的主要优势在于B树层数多时节省定位叶节点的开销,所以,其优势场景应该是读多写少,并且是叶节点定位占比多的场景,比如:CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0‘,
`c` char(120) NOT NULL DEFAULT ‘’,
`pad` char(60) NOT NULL DEFAULT ‘’,
PRIMARY KEY (`id`),
KEY `k_1` (`k`) ) ENGINE=InnoDB;
可以看到表里有一个主键(id)和一个二级索引列(k),每个k可能对应多个主键,即k存在重复值, 因此对k的查询可能需要多次回表。我们定义k的重复度为每个唯一k对应多少行主表数据,查询SQL为SELECT SUM(ASCII(c)) FROM sbtest1 WHERE k=?
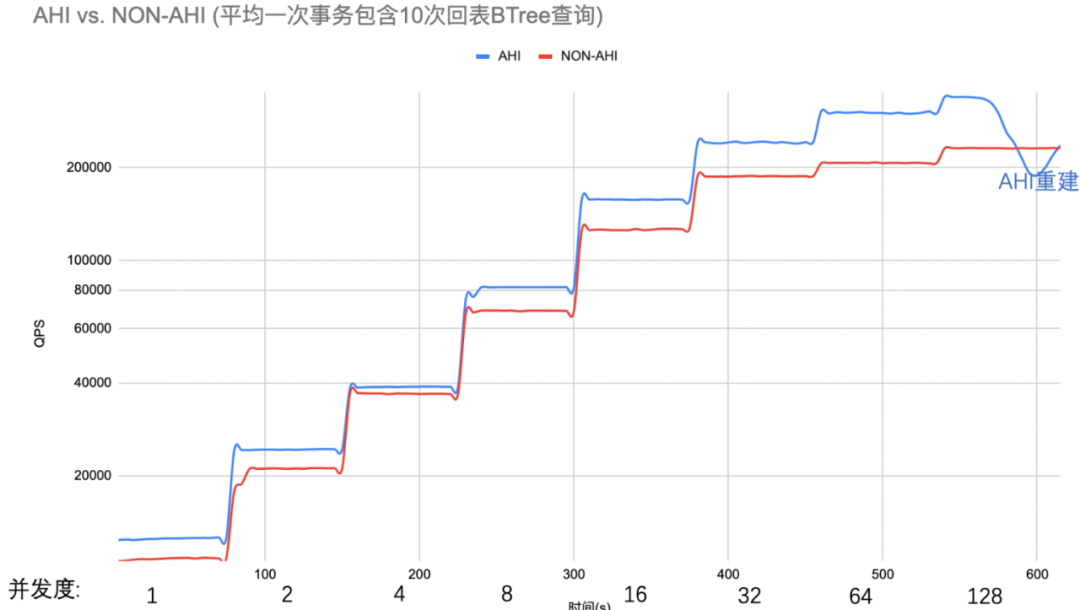
我们可以看到,K重复度10,AHI提升QPS平均24%,最高47%。性能提升还是很明显的。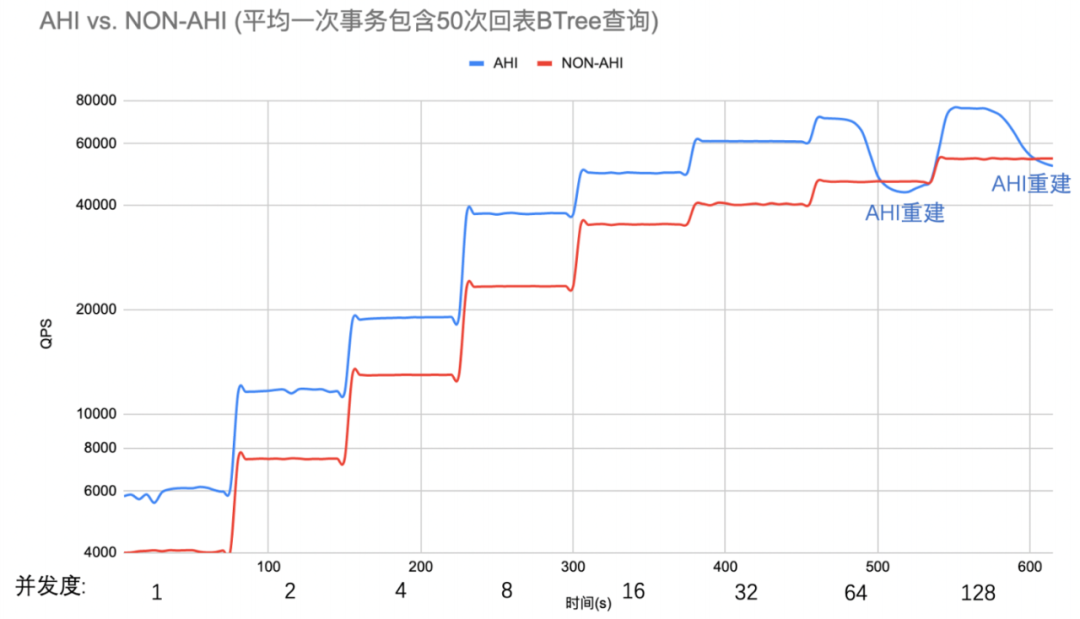
而当K重复度50的时候,AHI提升QPS平均43%,最高63%,性能提升就更为显著。SELECT SUM(ASCII(c)) from sbtest1 where id in(…)
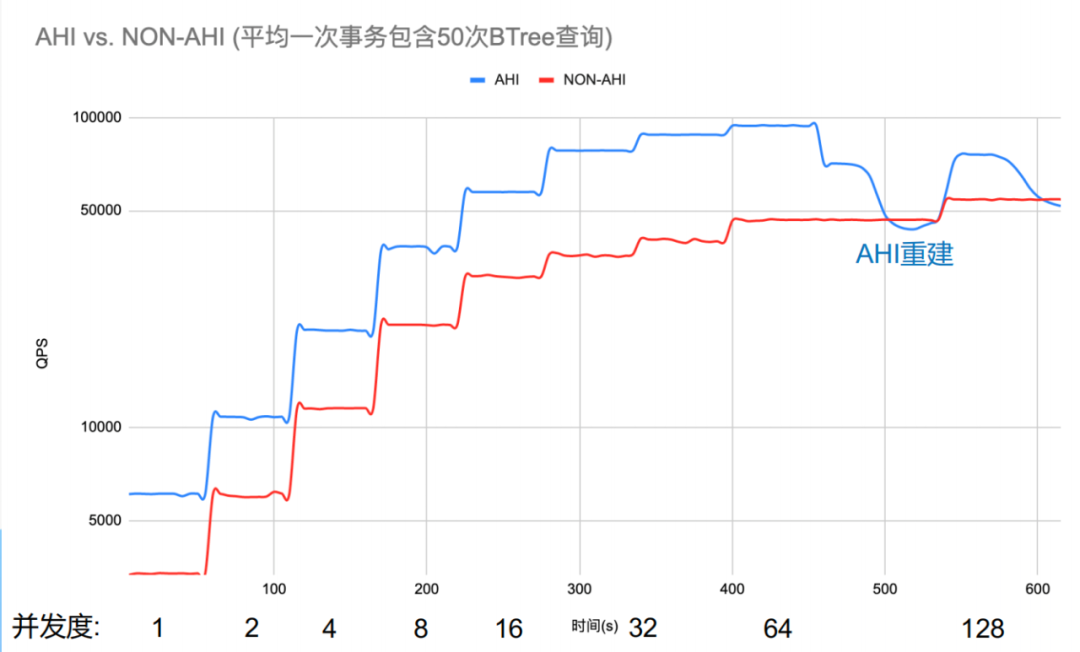
In列表长度为50时,AHI提升QPS平均74%,最高123%。是不是很Nice?所以,AHI在其优势场景下,对QPS的提升是非常有效的,这应该也是官方一直默认开启的原因吧。
虽然AHI有着能显著提升系统性能的好处,但也不是完美无缺的,所以,上面我们介绍了AHI的优势部分,接下来我们再讲讲它存在的一些问题,让大家对它有更全面的了解。
•Drop
table时,需要清理AHI,这个动作非常耗时,如下图所示1亿行数据,select.lua 100并发运行 600s后,执行drop table需要66秒左右
(而不开AHI,drop table 需要10s左右)•Drop大表持有相关锁超过600秒时,其他线程会一直等待直到信号超时600s,mysqld自动crash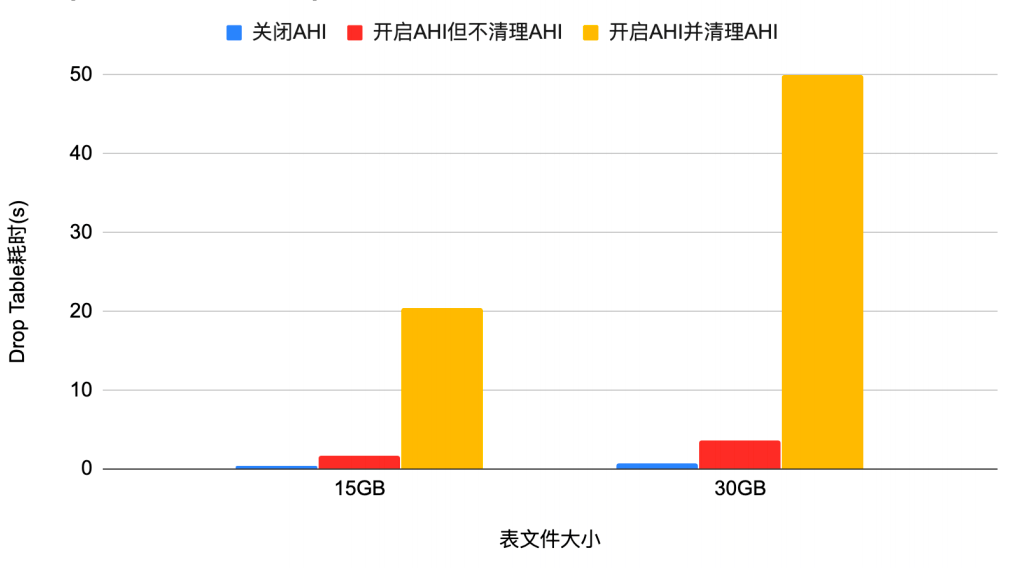
DROP TABLE清理Buffer Pool的关键流程•找到index的每个在AHI中有记录的page(在BP中)所以,当被drop的表在AHI中有很多缓存记录时就需要逐条删除,这个动作非常耗时。1:升级到8.0.23及之后的版本(https://dev.mysql.com/worklog/task/?id=14100)Klustron数据库1.2版本存储节点使用的是8.0.26版本所以不存在这个问题。只能有一个线程对hash table进行修改,其他并发构建AHI线程等待这个hash table的X锁,阻塞了查询的关键路径。如下图所示,测试过程中有一个明显的性能低谷,这个就是AHI构建瓶颈导致的。2. 根据统计信息作出决定是否把当前页面的记录加入AHI的hash
table3. 将记录加入hash table中时需要对索引对应的AHI分区进行加X锁。所以,高并发情况下,只有一个线程能插入AHI记录,其他线程都被阻塞。1:升级到8.0.30及之后的版本(https://bugs.mysql.com/bug.php?id=100512)
Q1:想问下是指向到数据页,还是能精确到页的具体偏移呢?
A1:AHI里的记录是查询条件对应叶子数据页,并没有精确到具体偏移,所以,完成定位后还需要做一次页内搜索。
Q2:AHI与 Hash index 有哪些不一样?A2:AHI是B树索引的hash索引,而hash 索引是数据的索引。A3:是的,AHI只存在于内存中,会占用buffer pool的内存空间,但不占用磁盘空间。A4:是的,drop table和truncate table都会有问题1。Q5:我们在实际的工作中,该如何判断是否打开 AHIA5:根据工作负载的情况来判断。如果工作负载是读多写少,而且大部分都是等值或in查询可以考虑打开AHI。如果是写多读少就建议关闭AHI。另外,如果不能升级到8.0.26版本,建议在drop经常访问的大表前,关闭一下AHI。现在,我们发起一轮新的投票,希望就以下问题请教大家,收集大家的反馈。为了感谢您的参与,所有参与问卷调查并留下邮箱联系方式的,由于我们的问卷系统不支持在线抽奖,我们将在后续会统一随机抽取 15 名有效填写者作为幸运参与者,送精美纪念礼品一份,感谢大家参加。同时欢迎大家扫码👇添加小助手(备注:加入Klustron技术交流群)欢迎大家在交流群共同探讨更多问题及主题。








