




本章openGauss数据库源码解析系列文章——AI技术部分最后一章,包括“指标采集、预测与异常检测”、“AI查询时间预测”、“DeepSQL”等相关内容的介绍,全文阅读预计需要60分钟,欢迎收藏阅读。
五、指标采集、预测与异常检测
数据库指标监控与异常检测技术,通过监控数据库指标,并基于时序预测和异常检测等算法,发现异常信息,进而提醒用户采取措施避免异常情况造成严重后果。
5.1 使用场景
用户操作数据库的某些行为或某些正在运行的业务发生了变化,都可能会导致数据库产生异常,如果不及时发现并处理这些异常,可能会导致严重的后果。通常,数据库监控指标(metric,如CPU使用率、QPS等)能够反映出数据库系统的健康状况。通过对数据库指标进行监控,分析指标数据特征或变化趋势等信息,可及时发现数据库异常状况,并及时将告警信息推送给运维管理人员,从而避免造成损失。
5.2 实现原理
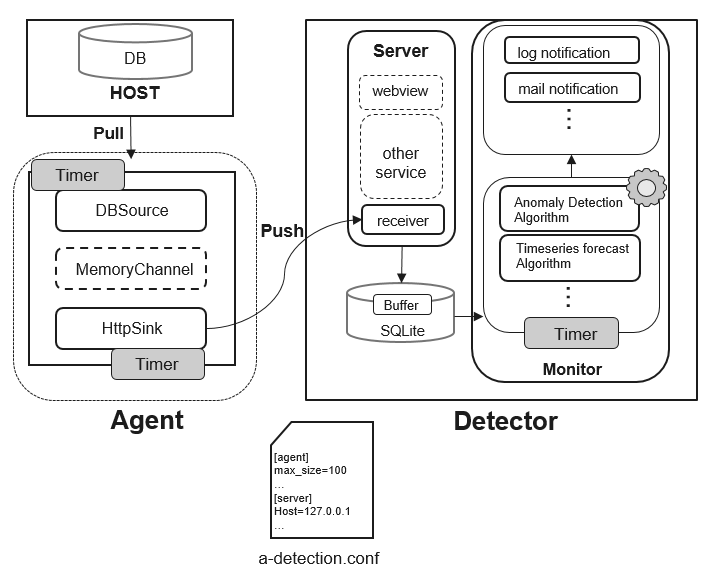
图1 Anomaly-Detection框架
指标采集、预测与异常检测是通过同一套系统实现的,在openGauss项目中名为Anomaly-Detection,它的结构如图1所示。该工具主要可以分为Agent和Detector两部分,其中Agent是数据库代理模块,负责收集数据库指标数据并将数据推送到Detector;Detector是数据库异常检测与分析模块,该模块主要有三个作用。
(1) 收集Agent端采集的数据并进行转储。
(2) 对收集到的数据进行特征分析与异常检测。
(3) 将检测出来的异常信息推送给运维管理人员。
1. Agent模块的组成
Agent模块负责采集并发送指标数据,该模块由DBSource、MemoryChannel、HttpSink三个子模块组成。
(1) DBSource作为数据源,负责定期去收集数据库指标数据并将数据发送到数据通道MemoryChannel中。
(2) MemoryChannel是内存数据通道,本质是一个FIFO队列,用于数据缓存。HttpSink组件消费MemoryChannel中的数据,为了防止MemoryChannel中的数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当超过容量上限时,过多的元素会被禁止放入队列中。
(3) HttpSink是数据汇聚点,该模块定期从MemoryChannel中获取数据,并以Http(s)的方式将数据进行转发,数据读取之后从MemoryChannel中清除。
2. Detector 模块组成
Detector模块负责数据检测,该模块由Server、Monitor两个子模块组成。
(1) Server是一个Web服务,为Agent采集到的数据提供接收接口,并将数据存储到本地数据库内部,为了避免数据增多导致数据库占用太多的资源,我们将数据库中的每个表都设置了行数上限。
(2) Monitor模块包含时序预测和异常检测等算法,该模块定期从本地数据库中获取数据库指标数据,并基于现有算法对数据进行预测与分析,如果算法检测出数据库指标在历史或未来某时间段或时刻出现异常,则会及时的将信息推送给用户。
5.3 关键源码解析
1. 总体流程解析
智能索引推荐工具的路径是openGauss-server/src/gausskernel/dbmind/tools/anomaly_detection,下面的代码详细展示了程序的入口。
def forecast(args):…# 如果没有指定预测方式,则默认使用’auto_arima’算法if not args.forecast_method:forecast_alg = get_instance('auto_arima')else:forecast_alg = get_instance(args.forecast_method)# 指标预测功能函数def forecast_metric(name, train_ts, save_path=None):…forecast_alg.fit(timeseries=train_ts)dates, values = forecast_alg.forecast(period=TimeString(args.forecast_periods).standard)date_range = "{start_date}~{end_date}".format(start_date=dates[0],end_date=dates[-1])display_table.add_row([name, date_range, min(values), max(values), sum(values) len(values)])# 校验存储路径if save_path:if not os.path.exists(os.path.dirname(save_path)):os.makedirs(os.path.dirname(save_path))with open(save_path, mode='w') as f:for date, value in zip(dates, values):f.write(date + ',' + str(value) + '\n')# 从本地sqlite中抽取需要的数据with sqlite_storage.SQLiteStorage(database_path) as db:if args.metric_name:timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)forecast_metric(args.metric_name, timeseries, args.save_path)else:# 获取sqlite中所有的表名tables = db.get_all_tables()# 从每个表中抽取训练数据进行预测for table in tables:timeseries = db.get_timeseries(table=table, period=max_rows)forecast_metric(table, timeseries)# 输出结果print(display_table.get_string())# 代码远程部署def deploy(args):print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))# 格式化代码远程部署指令command = 'sh start.sh --deploy {host} {user} {project_path}' \.format(user=args.user,host=args.host,project_path=args.project_path)# 判断指令执行情况if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:print("\nExecute successfully.")else:print("\nExecute unsuccessfully.")…# 展示当前监控的参数def show_metrics():…# 项目总入口def main():…
2. 关键代码段解析
(1) 后台线程的实现。
前面已经介绍过了,本功能可以分为三个角色:Agent、Monitor以及Detector,这三个不同的角色都是常驻后台的进程,各自执行着不同的任务。Daemon类就是负责运行不同业务流程的容器类,下面介绍该类的实现。
class Daemon:"""This class implements the function of running a process in the background."""def __init__(self):…def daemon_process(self):# 注册退出函数atexit.register(lambda: os.remove(self.pid_file))signal.signal(signal.SIGTERM, handle_sigterm)# 启动进程@staticmethoddef start(self):try:self.daemon_process()except RuntimeError as msg:abnormal_exit(msg)self.function(*self.args, **self.kwargs)# 停止进程def stop(self):if not os.path.exists(self.pid_file):abnormal_exit("Process not running.")read_pid = read_pid_file(self.pid_file)if read_pid > 0:os.kill(read_pid, signal.SIGTERM)if read_pid_file(self.pid_file) < 0:os.remove(self.pid_file)
(2) 数据库相关指标采集过程。
数据库的指标采集架构,参考了Apache Flume的设计。将一个完整的信息采集流程拆分为三个部分,分别是Source、Channel以及Sink。上述三个部分被抽象为三个不同的基类,由此可以派生出不同的采集数据源、缓存管道以及数据的接收端。
前文提到过的DBSource即派生自Source、MemoryChannel派生自Channel,HttpSink则派生自Sink。下面这段代码来自metric_agent.py,负责采集指标,在这里将上述模块串联起来了。
def agent_main():…# 初始化通道管理器cm = ChannelManager()# 初始化数据源source = DBSource()http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)source.channel_manager = cmhttp_sink.channel_manager = cm# 获取参数文件里面的功能函数for task_name, task_func in get_funcs(metric_task):source.add_task(name=task_name,interval=params['source_timer_interval'],task=task_func,maxsize=params['channel_capacity'])source.start()http_sink.start()
(3) 数据存储与监控部分的实现。
Agent将采集到的指标数据发送到Detector服务器上,并由Detector服务器负责存储。Monitor不断对存储的数据进行检查,以便提前发现异常。
这里实现了一种通过SQLite进行本地化存储的方式,代码位于sqlite_storage.py文件中,实现的类为SQLiteStorage,该类实现的主要方法如下:
# 通过时间戳获取最近一段时间的数据def select_timeseries_by_timestamp(self, table, period):…# 通过编号获取最近一段时间的数据def select_timeseries_by_number(self, table, number):…
其中,由于不同指标数据是分表存储的,因此上述参数table也代表了不同指标的名称。
异常检测当前主要支持基于时序预测的方法,包括Prophet算法(由Facebook开源的工业级时序预测算法工具)和ARIMA算法,他们分别被封装成类,供Forecaster调用。
上述时序检测的算法类都继承了AlgModel类,该类的结构如下:
class AlgModel(object):"""This is the base class for forecasting algorithms.If we want to use our own forecast algorithm, we should follow some rules."""def __init__(self):pass@abstractmethoddef fit(self, timeseries):pass@abstractmethoddef forecast(self, period):passdef save(self, model_path):passdef load(self, model_path):pass
在Forecast类中,通过调用fit()方法,即可根据历史时序数据进行训练,通过forecast()方法预测未来走势。
获取到未来走势后如何判断是否是异常呢?方法比较多,最简单也是最基础的方法是通过阈值来进行判断,在我们的程序中,默认也是采用该方法进行判断的。
5.4 使用示例
Anomaly-Detection工具有start、stop、forecast、show_metrics、deploy五种运行模式,各模式说明如表1所示。
表1 Anomaly-Detection使用模式及说明
模式名称 | 说明 |
start | 启动本地或者远程服务 |
stop | 停止本地或远程服务 |
forecast | 预测指标未来变化 |
show_metrics | 输出当前监控的参数 |
deploy | 远程部署代码 |
Anomaly-Detection工具运行模式使用示例如下所示。
① 使用start模式启动本地collector服务,代码如下:
python main.py start –role collector
② 使用stop模式停止本地collector服务,代码如下:
python main.py stop –role collector
③ 使用start模式启动远程collector服务,代码如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用stop模式停止远程collector服务,代码如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 显示当前所有的监控参数,代码如下:
python main.py show_metrics
⑥ 预测io_read未来60秒的最大值、最小值和平均值,代码如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 将代码部署到远程服务器,代码如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
5.5 演进路线
Anomaly-Detection作为一款数据库指标监控和异常检测工具,目前已经具备了基本的数据收集、数据存储、异常检测、消息推送等基本功能,但是目前存在以下几个问题。
(1) Agent模块收集数据太单一。目前Agent只能收集数据库的资源指标数据,包IO、磁盘、内存、CPU等,后续还需要在采集指标丰富度上作增强。
(2) Monitor内置算法覆盖面不够。Monitor目前只支持两种时序预测算法,同时针对异常检测额,也仅支持基于阈值的简单情况,使用的场景有限。
(3) Server仅支持单个Agent传输数据。Server目前采用的方案仅支持接收一个Agent传过来的数据,不支持多Agent同时传输,这对于只有一个主节点的openGauss数据库暂时是够用的,但是对分布式部署显然是不友好的。
因此,针对以上三个问题,未来首先会丰富Agent以便于收集数据,主要包括安全指标、数据库日志等信息。其次在算法层面上,编写鲁棒性(即算法的健壮性与稳定性)更强的异常检测算法,增加异常监控场景。同时,需要对Server进行改进,使其支持多Agent模式。最后,需要实现故障自动修复功能,并与本功能相结合。
六 、AI查询时间预测
在前面介绍过“慢SQL发现”特性,该特性的典型场景是新业务上线前的检查,输入源是提前采集到的SQL流水数据。慢SQL发现功能主要主要应用在多条SQL语句的批量检查上,要求之前执行过SQL语句,因此给出的结果主要是定性的,在某些场景下可能难以满足用户对于评估精度的要求。
因此,为了弥补上述场景的不足,满足用户更精确的SQL时间预测需求,同时为AI优化器做铺垫,实现了本章所述的功能。
由于实际业务场景具有复杂的特质,现有的数据库静态代价估计模型往往统计结果失准,从而选择了一些执行计划较差的路径。因此,针对上述复杂场景,需要数据库的代价估计模型具备自我更新的能力。本特性主要功能为基于查询语句的历史数据,对当前执行的SQL语句进行查询耗时和基数的估算。
6.1 使用场景
AI查询分析的前提是需要获取执行计划。首先需要根据用户需求在查询执行时收集复杂查询实际查询计划(包括计划结构、算子类型、相关数据源、过滤条件等)、各算子节点实际执行时间、优化器估算代价、实际返回行数、优化器估算行数、SMP并发线程数、等信息。将其记录在数据表中,并进行持久化管理包括定期进行数据失效清理。
本功能主要分为两个方面,一个是行数估算,一个是查询预测,前者是后者预测好坏的前提。目前openGauss基于在线学习对执行计划各层的结果集大小进行估算,仅起到展示作用,并未影响到执行计划的生成。后续可帮助优化器更准确地进行结果集估算,从而获取更优的执行计划。
当前阶段本需求会提供系统函数来进行预测,并加入到explain中进行实际比较验证。
6.2 现有技术
当前学术界在AI4DB领域,对基于机器学习的行数估算和查询时延预测有许多尝试。
1. 传统方法
正如数据库优化器专家Guy Lohman在博客Is query optimization a “solved” problem中所说,传统数据库查询性能预测的“阿喀琉斯之踵”便是中间结果集大小的估算。对于行数估算传统基于统计信息行数估算方法主要基于三类假设。
(1) 数据独立分布假设。
(2) 均匀分布假设。
(3) 主外键假设。
而实际场景中数据往往存在一定的相关性和倾斜性,此时上述假设可能会被打破,导致传统数据库优化器在多表连接中间结果集大小估算中可能会存在数个数量级的误差。
2000年以来,以基于采样的估算、基于采样的核密度函数估算、基于多列直方图为代表的统计学方法被提出,用于解决数据相关性带来的估算问题。然而这些方法都存在一个共性问题,就是模型无法进行增量维护,而收集这些额外的统计信息会增加巨大的数据库维护开销,虽然在一些特定的问题场景(如多列Range条件选择率)取得了很大的准确率提升,但并没有被各大数据库厂商广泛采用。
传统性能预测方法主要依赖代价模型,在以下几个方面存在明显劣势。
(1) 准确性:随着底层硬件架构和优化技术不断演进,实际性能预测模型的复杂度远不可以用线性模型来建模。
(2) 可扩展性:代价模型的开发成本较高,不能面面俱到地对用户具体场景进行优化。
(3) 可校准性:代价模型灵活性仅局限于各资源维度线性相加时使用的系数,以及部分惩罚代价,灵活性较差,用户实际使用时难以校准。
(4) 时效性:代价模型依赖统计信息的收集和使用,目前缺乏增量维护方法,导致数据流动性较大的场景下统计信息长期处于失效状态。
2. 机器学习方法
机器学习模型在模型复杂度、可校准性、可增量维护性几个维度的优势能够弥补传统优化器代价模型的不足,基于机器学习的查询性能预测逐渐成为数据库学术界和产业界的主流研究方向之一。
除前文8.3节慢SQL发现部分介绍过相关方法外,清华大学的Learned Cost Estimator模型基于Multi-task Learning和字符条件的Word-Embedding方法进一步提升了预测准确率。
至此,机器学习方法虽然从实验效果上看达到了较高的准确率,但现实业务场景持续性的数据分布变化对模型的在线学习能力提出了要求。openGauss采用了数据驱动的在线学习模式,通过内核不断收集历史作业性能信息,并在AI Engine侧使用了R-LSTM(recursive long short term memory,递归长短期记忆网络)模型对算子级查询时延和中间结果集大小进行预测。
6.3 实现原理
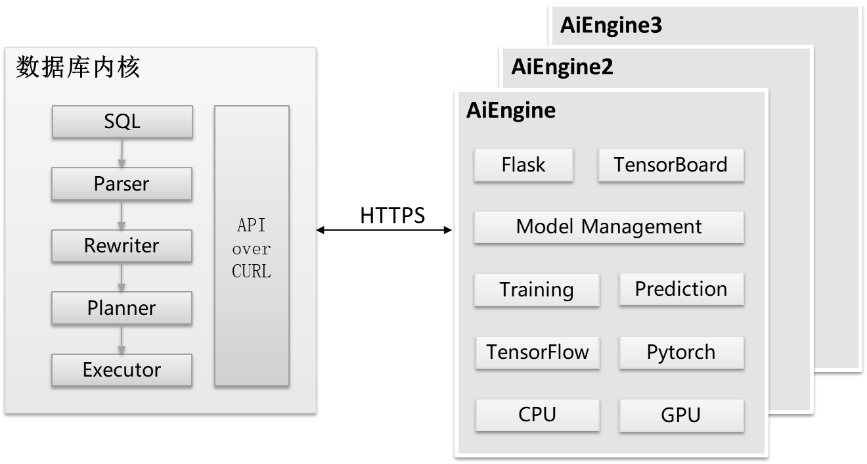
图2 AI查询性能预测架构示意图
总体而言,查询性能预测由数据库内核侧和AI Engine侧两个部分组成,如图2所示。
(1) 数据库内核侧除提供数据库基本功能外还需要对历史数据进行收集和持久化管理,并通过curl向AI Engine侧发送HTTPS请求。
(2) AI Engine提供模型训练、执行预测、模型管理等接口,基于Flask框架的服务端接受HTTPS请求,该流程如图3所示。
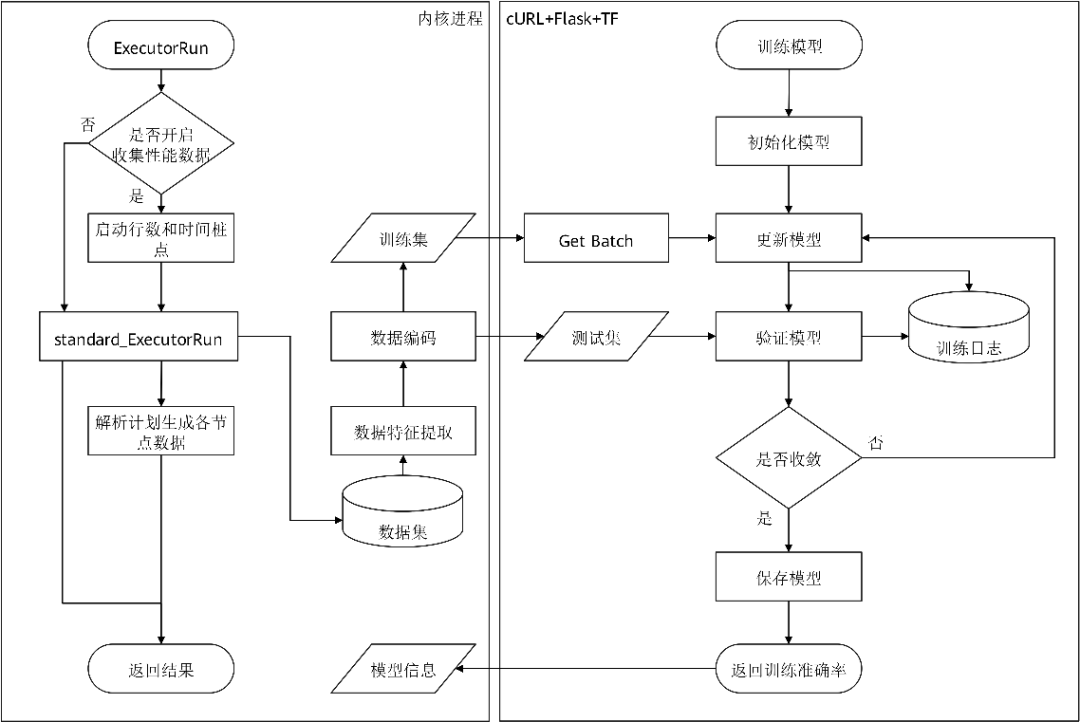
图 3 数据库内核和AI Engine进程关系示意图
开启数据收集相关参数后(其对性能可能有5%左右的影响,取决于实际业务负载情况),历史性能数据被持久化收集在数据库的系统表中,用于模型的训练。
模型训练之前,用户需要对模型参数进行配置(详见6.5使用示例)。用户训练指令下发之后,内核进程会向AI Engine侧发送configure请求,用于初始化机器学习模型。configure流程时序如图4所示。
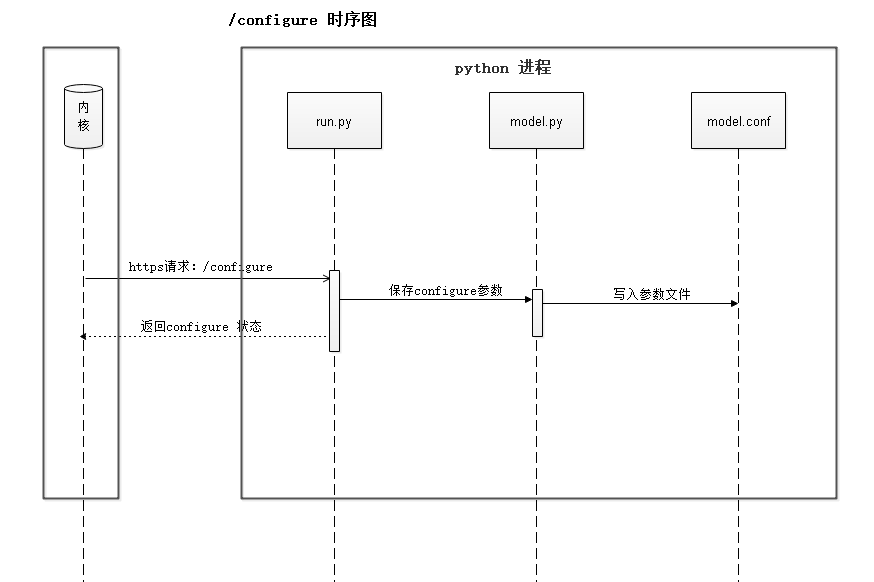
图4 configure流程时序图
模型配置成功后,内核进程向AI Engine侧发送train请求,触发训练,该流程如图5所示。
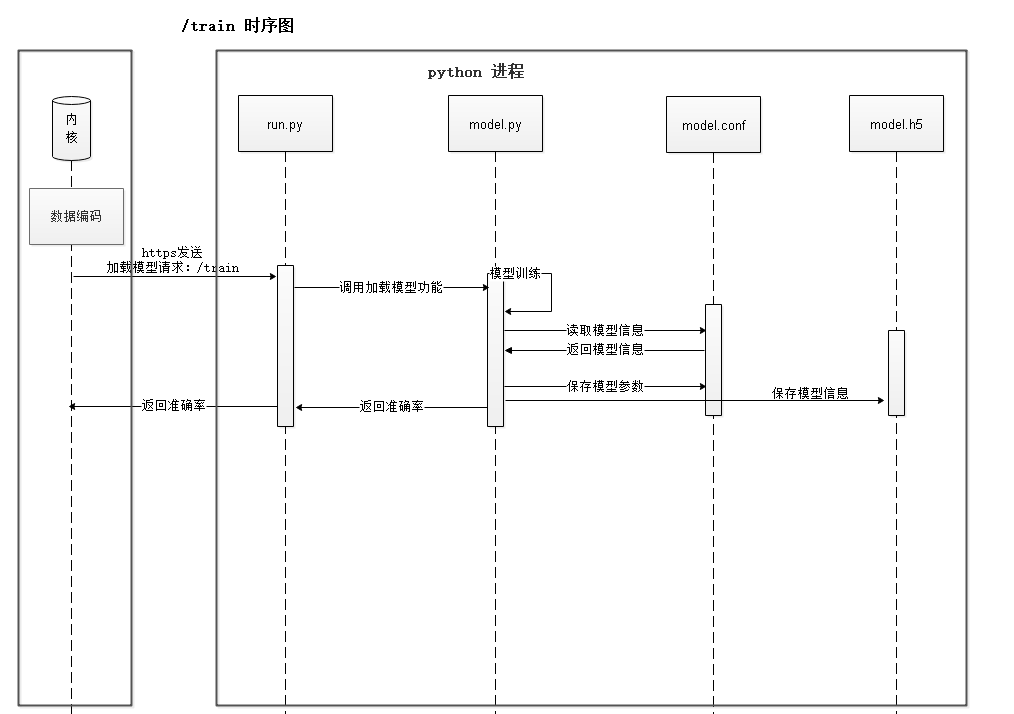
图5 train流程时序图
模型训练之后,用户下发预测指令,数据库会先向AI Engine侧发送setup请求,用于模型加载,加载成功后发送predict请求得到预测结果,如图6所示。
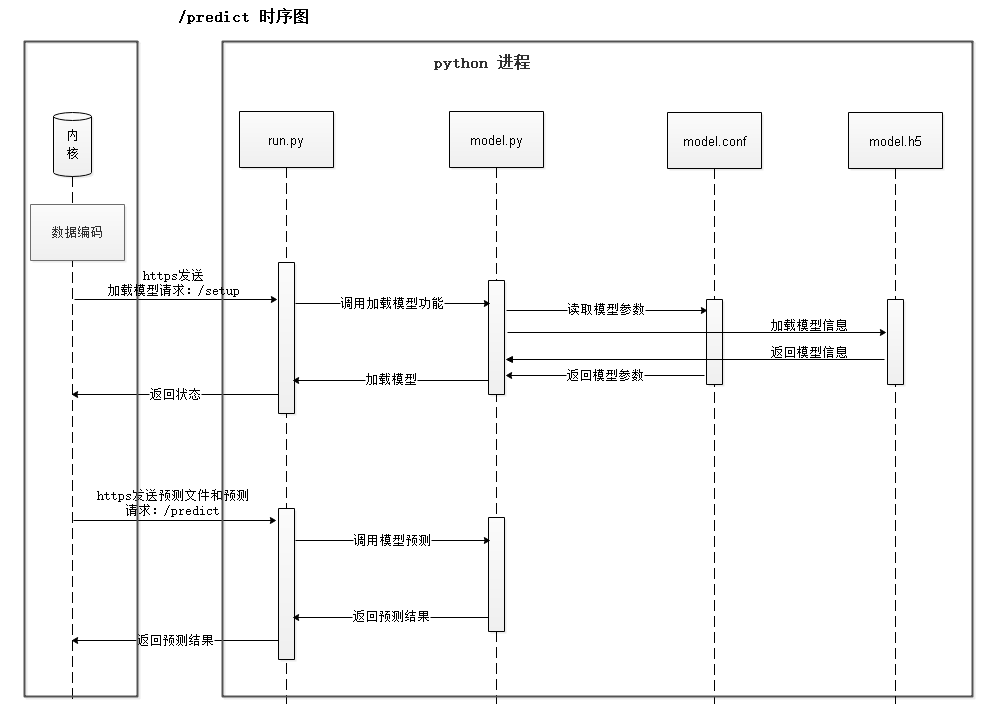
图6 模型预测完整流程时序图,分为setup和predict两个阶段
本特性架构上支持多模型,目前已实现R- LSTM模型,该模型架构如图7所示。
计划中,算子间的执行顺序也会影响算子的性能。基于这种特性,我们使用了LSTM神经网络模型来学习计划中算子间这种有意义的依赖关系,并根据行数/时间预测的场景对模型的结构、损失函数、优化算法等方面进行针对性的优化,提高此场景下学习和预测的准确率。
输入:查询计划树,各节点上的算子类型,对应表名列名以及过滤条件。
输出:行数、startup time、total time、Peak Memory。
在编码(encoding)阶段,每个计划节点(plan node)被编码成固定长度,连接成序列作为输入LSTM神经网络的特征值。
LSTM具有多个重复神经网络模块组成的链式网络,在每个模块中都有三个函数来决定历史时序中的哪些信息将被传递到下一个时序的网络模块中。最后一个模块的输出值即为模型返回的预测结果。
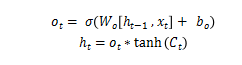
其中,xt是当前时序模块的输入,ht-1是前一个时序的输出信息,使用sigmoid(ð)函数得到当前细胞状态中将要输出的部分ot;Ct表示所有历史时序保留的信息,通过tanh函数处理后与当前状态输出信息ot相乘得到此状态的输出ht,将具有三个元素的一维向量 [startup time, total time, cardinality] 的预测结果同真实数据进行比较,使用ratio-error计算模型的损失函数。
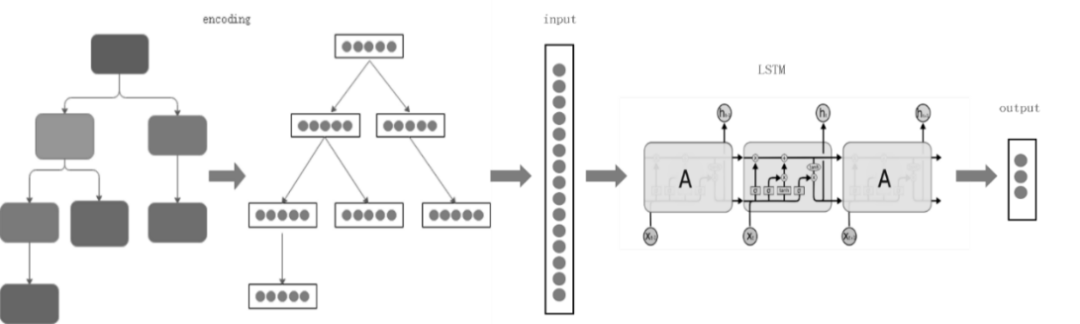
图7 模型架构图
6.4 关键源码解析
1. 项目结构
AI Engine侧涉及的主要文件路径为openGauss-server/src/gausskernel/dbmind/tools/predictor,其文件结构如表2所示。
表2 AI Engine文件结构
文件结构 | 说明 |
install | 部署所需文件路径 |
install/ca_ext.txt | 证书配置文件 |
install/requirements-gpu.txt | 使用GPU(graphics processing unit,图形处理器)训练依赖库列表 |
install/requirements.txt | 使用CPU训练依赖库列表 |
install/ssl.sh | 证书生成脚本 |
python | 项目代码路径 |
python/certs.py | 加密通信 |
python/e_log | 系统日志路径 |
python/log | 模型训练日志路径 |
python/log.conf | 配置文件 |
python/model.py | 机器学习模型 |
python/run.py | 服务端主函数 |
python/saved_models | 模型训练checkpoint |
python/settings.py | 工程配置文件 |
python/uploads | Curl传输的文件存放路径 |
内核侧主要涉及的文件路径为openGauss-server/src/gausskernel/optimizer/util/learn,其文件结构如表3所示。
表3 内核端主要文件结构
文件结构 | 说明 |
comm.cpp | 通信层代码实现 |
encoding.cpp | 数据编码 |
ml_model.cpp | 通用模型调用接口 |
plan_tree_model.cpp | 树状模型调用接口 |
2. 训练流程
内核侧的模型训练接口通过ModelTrainInternal函数实现,该函数的关键部分如下:
static void ModelTrainInternal(const char* templateName, const char* modelName, ModelAccuracy** mAcc){…/* 对于树形模型调用对应的训练接口 */char* trainResultJson = TreeModelTrain(modelinfo, labels);/* 解析返回结果 */…ModelTrainInfo* info = GetModelTrainInfo(jsonObj);cJSON_Delete(jsonObj);/* 更新模型信息 */Relation modelRel = heap_open(OptModelRelationId, RowExclusiveLock);…UpdateTrainRes(values, datumsMax, datumsAcc, nLabel, mAcc, info, labels);HeapTuple modelTuple = SearchSysCache1(OPTMODEL, CStringGetDatum(modelName));…HeapTuple newTuple = heap_modify_tuple(modelTuple, RelationGetDescr(modelRel), values, nulls, replaces);simple_heap_update(modelRel, &newTuple->t_self, newTuple);CatalogUpdateIndexes(modelRel, newTuple);…}
内核侧的树状模型训练接口通过TreeModelTrain函数实现,核心代码如下:
char* TreeModelTrain(Form_gs_opt_model modelinfo, char* labels){char* filename = (char*)palloc0(sizeof(char) * MAX_LEN_TEXT);char* buf = NULL;/* configure阶段 */ConfigureModel(modelinfo, labels, &filename);/* 将编码好的数据写入临时文件 */SaveDataToFile(filename);/* Train阶段 */buf = TrainModel(modelinfo, filename);return buf;}
AI Engine侧配置的Web服务的URI是/configure,训练阶段的URI是/train.下面的代码段展示了训练过程。
def fit(self, filename):keras.backend.clear_session()set_session(self.session)with self.graph.as_default():# 根据模型入参和出参维度变化情况,判断是否需要初始化模型feature, label, need_init = self.parse(filename)os.environ['CUDA_VISIBLE_DEVICES'] = '0'epsilon = self.model_info.make_epsilon()if need_init: # 冷启动训练epoch_start = 0self.model = self._build_model(epsilon)else: # 增量训练epoch_start = int(self.model_info.last_epoch)ratio_error = ratio_error_loss_wrapper(epsilon)ratio_acc_2 = ratio_error_acc_wrapper(epsilon, 2)self.model = load_model(self.model_info.model_path,custom_objects={'ratio_error': ratio_error, 'ratio_acc': ratio_acc_2})self.model_info.last_epoch = int(self.model_info.max_epoch) + epoch_startself.model_info.dump_dict()log_path = os.path.join(settings.PATH_LOG, self.model_info.model_name + '_log.json')if not os.path.exists(log_path):os.mknod(log_path, mode=0o600)# 训练日志记录回调函数json_logging_callback = LossHistory(log_path, self.model_info.model_name, self.model_info.last_epoch)# 数据分割X_train, X_val, y_train, y_val = \train_test_split(feature, label, test_size=0.1)# 模型训练self.model.fit(X_train, y_train, epochs=self.model_info.last_epoch,batch_size=int(self.model_info.batch_size), validation_data=(X_val, y_val),verbose=0, initial_epoch=epoch_start, callbacks=[json_logging_callback])# 记录模型checkpointself.model.save(self.model_info.model_path)val_pred = self.model.predict(X_val)val_re = get_ratio_errors_general(val_pred, y_val, epsilon)self.model_logger.debug(val_re)del self.modelreturn val_re
3. 预测流程
内核侧的模型预测过程主要通过ModelPredictInternal函数实现。树状模型预测过程通过TreeModelPredict函数实现。内核侧的树状模型预测过程会占用一些与AI Engine进行通信的信令,该通信过程如下:
char* TreeModelPredict(const char* modelName, char* filepath, const char* ip, int port){…if (!TryConnectRemoteServer(conninfo, &buf)) {DestroyConnInfo(conninfo);ParseResBuf(buf, filepath, "AI engine connection failed.");return buf;}switch (buf[0]) {case '0': {ereport(NOTICE, (errmodule(MOD_OPT_AI), errmsg("Model setup successfully.")));break;}case 'M': {ParseResBuf(buf, filepath, "Internal error: missing compulsory key.");break;}…}/* Predict阶段 */…if (!TryConnectRemoteServer(conninfo, &buf)) {ParseResBuf(buf, filepath, "AI engine connection failed.");return buf;}switch (buf[0]) {case 'M': {ParseResBuf(buf, filepath, "Internal error: fail to load the file to predict.");break;}case 'S': {ParseResBuf(buf, filepath, "Internal error: session is not loaded, model setup required.");break;}default: {break;}}return buf;}
AI Engine侧的Setup过程的Web接口是/model_setup,预测阶段的Web接口是/predict,他们的协议都是Post。
4. 数据编码
数据编码分为以下两个维度。
(1) 算子维度:包括每个执行计划算子的属性,如表4所示。
表4 算子维度
属性名 | 含义 | 编码策略 |
Optname | 算子类型 | One-hot |
Orientation | 返回元组存储格式 | One-hot |
Strategy | 逻辑属性 | One-hot |
Options | 物理属性 | One-hot |
Quals | 谓词 | hash |
Projection | 返回投影列 | hash |
(2) 计划维度。
对于每个算子,在其固有属性之外,openGauss还对query id,plan node id和parent node id进行了记录,在训练/预测阶段,使用这些信息将算子信息重建为树状计划结构,且可以递归构建子计划树来进行数据增强,从而提升模型泛化能力。树状数据结构如图8所示。
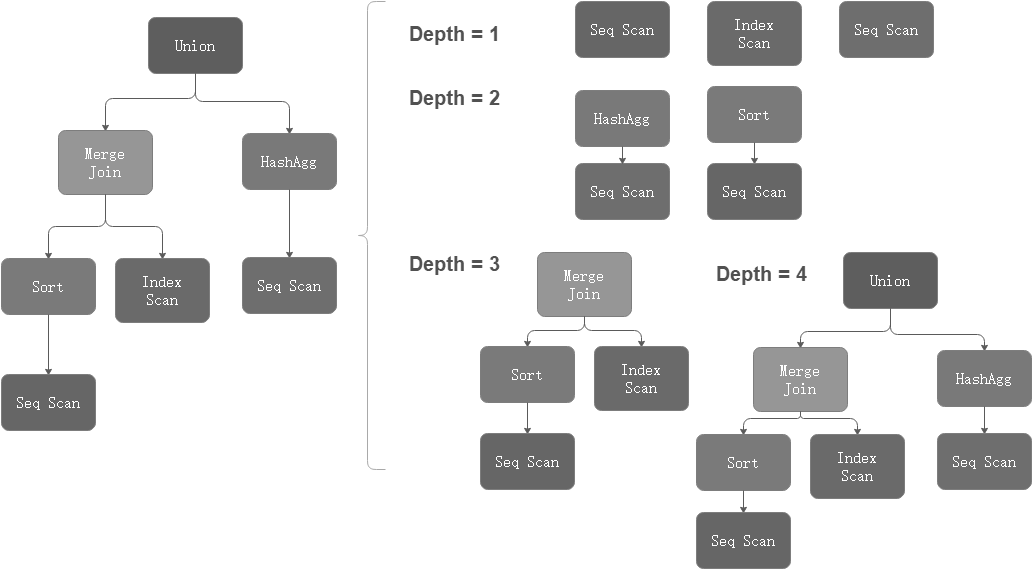
图8 树状数据结构示意图
内核侧的树状数据编码通过GetOPTEncoding函数实现。
5. 模型结构
AI Engine的模型解析、训练和预测见6.4章节,下面的代码展示了模型的结构。
class RnnModel():def _build_model(self, epsilon):model = Sequential()model.add(LSTM(units=int(self.model_info.hidden_units), return_sequences=True, input_shape=(None, int(self.model_info.feature_length))))model.add(LSTM(units=int(self.model_info.hidden_units), return_sequences=False))model.add(Dense(units=int(self.model_info.hidden_units), activation='relu'))model.add(Dense(units=int(self.model_info.hidden_units), activation='relu'))model.add(Dense(units=int(self.model_info.label_length), activation='sigmoid'))optimizer = keras.optimizers.Adadelta(lr=float(self.model_info.learning_rate), rho=0.95)ratio_error = ratio_error_loss_wrapper(epsilon)ratio_acc_2 = ratio_error_acc_wrapper(epsilon, 2)model.compile(loss=ratio_error, metrics=[ratio_acc_2], optimizer=optimizer)return model
AI Engine的损失函数使用ratio error(部分文献中使用qerror代称),该损失函数相较于MRE和MSE的优势在于其能够等价地惩罚高估和低估两种情况,公式为:
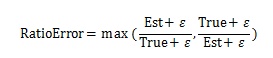
ε声明为性能预测值的无穷小值,防止分母为0的情况发生。
6.5 使用示例
AI查询时间预测功能使用示例如下。
① 定义性能预测模型,代码如下:
INSERT INTO gs_opt_model VALUES(‘rlstm’, ‘model_name’, ‘host_ip’, ‘port’);
② 通过GUC参数开启数据收集,配置的参数列表,代码如下:
enable_resource_track = on;enable_resource_record = on;
③ 编码训练数据,代码如下:
SELECT gather_encoding_info('db_name');
④ 校准模型,代码如下:
SELECT model_train_opt('template_name', 'model_name');
⑤ 监控训练状态,代码如下:
SELECT track_train_process('host_ip', 'port');
⑥ 通过explain + SQL语句来预测SQL查询的性能,代码如下:
EXPLAIN (..., predictor 'model_name') SELECT ...
获得结果,其中,“p-time”列为标签预测值。
Row Adapter (cost=110481.35..110481.35 rows=100 p-time=99..182 width=100) (actual time=375.158..375.160 rows=2 loops=1)
6.6 演进路线
目前模型的泛化能力不足,依赖外置的AI Engine组件,且深度学习网络比较重,这会为部署造成困难;模型需要数据进行训练,冷启动阶段的衔接不够顺畅,后续从以下几个方面演进。
(1) 加入不同复杂度模型,并支持多模型融合分析,提供更健壮的模型预测结果和置信度。
(2) AI Engine考虑加入任务队列,目前仅支持单并发预测/训练,可以考虑建立多个服务端进行并发业务。
(3) 基于在线学习/迁移学习的增强,考虑对损失函数加入锚定惩罚代价来避免灾难遗忘问题,同时优化数据管理模式,考虑data score机制,根据数据时效性赋权。
(4) 将本功能与优化器深度结合,探索基于AI的路径选择方法。
七、DeepSQL
前面提到的功能均为AI4DB领域,AI与数据库结合还有另外一个大方向,即DB4AI。在本章中,我们将介绍openGauss的DB4AI能力,探索通过数据库来高效驱动AI任务的新途径。
7.1 使用场景
数据库DB4AI功能的实现,即在数据库内实现AI算法,以更好的支撑大数据的快速分析和计算。目前openGauss的DB4AI能力通过DeepSQL特性来呈现。这里提供了一整套基于SQL的机器学习、数据挖掘以及统计学的算法,用户可以直接使用SQL语句进行机器学习工作。DeepSQL能够抽象出端到端的、从数据到模型的数据研发过程,配合底层的计算引擎及数据库自动优化,让具备基础SQL知识的用户即可完成大部分的机器学习模型训练及预测任务。整个分析和处理都运行在数据库引擎中,用户可以直接分析和处理数据库内的数据,不需要在数据库和其他平台之间进行数据传递,避免在多个环境之间进行不必要的数据移动,并且整合了碎片化的数据开发技术栈。
7.2 现有技术
如今,学术界与工业界在DB4AI这个方向已经了取得了许多成果。很多传统的商业关系数据库都已经支持了DB4AI能力,通过内置AI组件适配数据库内的数据处理和环境,可以对数据库存储的数据进行处理,最大程度地减少数据移动的花费。同时,很多云数据库、云计算数据分析平台也都具备DB4AI能力。同时还可能具备Python、R语言等接口,便于数据分析人员快速入门。
在DB4AI领域,同样具备很出色的开源软件,例如Apache顶级开源项目MADlib。它兼容PostgreSQL数据库,很多基于PostgreSQL数据库源码基线进行开发的数据库也可以很容易进行适配。MADlib可以为结构化和非结构化数据提供统计和机器学习的方法,并利用聚集函数实现在分布式数据库上的并行化计算。MADlib支持多种机器学习、数据挖掘算法,例如回归、分类、聚类、统计、图算法等,累计支持的算法达到70多个,在目前发布的1.17版本中MADlib支持深度学习。MADlib使用类SQL语法作为对外接口,通过创建UDF(user-defined function,用户自定义函数)的方式将AI任务集成到数据库中。
当前openGauss的DB4AI模块,兼容开源的MADlib,在原始MADlib开源软件的基础上进行了互相适配和增强,性能相比在PostgreSQL数据库上运行的MADlib性能更优。同时,openGauss基于MADlib框架,实现了其他工业级的、常用的算法,例如XGBoost、Prophet、GBDT以及推荐系统等。与此同时,openGauss还具备原生的AI执行计划与执行算子,该部分特性会在后续版本中开源。因此,本章内容主要介绍openGauss是如何兼容MADlib的。
7.3 关键源码解析
1. MADLib的项目结构
MADlib的文件结构及说明如表5所示,MADlib的代码可通过其官方网站获取:https://madlib.apache.org/。
表5 MADlib的主要文件结构
文件结构 | 说明 | |
cmake | - | Cmake相关文件 |
/array_ops | 数组array操作模块 | |
/kmeans | Kmeans相关模块 | |
/sketch | 词频统计处理相关模块 | |
/stemmer | 词干处理相关模块 | |
/svec | 稀疏矩阵相关模块 | |
/svec_util | 稀疏矩阵依赖模块 | |
/utils | 其他公共模块 | |
src/bin | - | 工具模块,用于安装、卸载、部署等 |
src/bin/madpack | - | 数据库交互模块 |
src/dbal | - | 词干处理相关模块 |
src/libstemmer | - | 工具依赖文件 |
src/madpack | - | 里面包含公共的模块 |
src/modules | - | 关联规则算法 |
/assoc_rules | 包括凸算法的实现 | |
/convex | 包括条件随机场算法 | |
/crf | 弹性网络算法 | |
/elastic_net | 广义线性模型 | |
/glm | 隐狄利克雷分配 | |
/lda | 线性代数操作 | |
/linalg | 线性系统模块 | |
/linear_systems | 概率模块 | |
/prob | 决策树和随机森林 | |
/recursive_partitioning | 回归算法 | |
/regress | 采样模块 | |
/sample | 数理统计类模块 | |
/stats | 时间序列 | |
/utilities | 包含pg,gaussdb平台相关接口 | |
src/ports | - | 接口,链接db |
src/ports/postgres | - | 针对pg系,相关算法 |
/dbconnector | 关联规则算法 | |
/modules | 贝叶斯算法 | |
/modules/bayes | 共轭梯度法 | |
/modules/conjugate_gradient | 包括多层感知机 | |
/modules/convex | 条件随机场 | |
/modules/crf | 弹性网络 | |
/modules/elastic_net | Prophet时序预测 | |
/modules/gbdt | Gdbt算法 | |
/modules/glm | 广义线性模型 | |
/modules/graph | 图模型 | |
/modules/kmeans | Kmeans算法 | |
/modules/knn | Knn算法 | |
/modules/lda | 隐狄利克雷分配 | |
/modules/linalg | 线性代数操作 | |
/modules/linear_systems | 线性系统模块 | |
/modules/pca | PCA降维 | |
/modules/prob | 概率模块 | |
/modules/recursive_partitioning | 决策树和随机森林 | |
/modules/sample | 回归算法 | |
/modules/stats | 采样模块 | |
/modules/summary | 数理统计类模块 | |
/modules/svm | 描述性统计的汇总函数 | |
/modules/tsa | Svm算法 | |
/modules/validation | 时间序列 | |
/modules/xgboost_gs | 交叉验证 | |
src/utils | - | Xgboost算法 |
2. MADlib在openGauss上的执行流程
用户通过调用UDF即可进行模型的训练和预测,相关的结果会保存在表中,存储在数据库上。以训练过程为例,MADlib在openGauss上执行的整体流程如图9所示。
图9 MADlib在openGauss上训练模型的流程图
7.4 基于MADlib框架的扩展
前文展示了MADlib各个模块的功能和作用,从结构上看,用户可以针对自己的算法进行扩展。前文中提到的XGBoost、GBDT和Prophet三个算法是我们在原来基础上扩展的算法。本小节将以自研的GBDT模块为例,介绍基于MADlib框架的扩展。
GBDT目录结构
GBDT文件结构如表6所示
表6 GBDT算法的主要文件结构
文件结构 | 说明 |
gbdt/gbdt.py_in | python代码 |
gbdt/gbdt.sql_in | 存储过程代码 |
gbdt/test/gbdt.sql | 测试代码 |
在sql_in文件中,定义上层SQL-like接口,使用PL/pgSQL或者PL/python实现。
在SQL层中定义UDF函数,下述代码实现了类似重载的功能。
CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train(training_table_name TEXT,output_table_name TEXT,id_col_name TEXT,dependent_variable TEXT,list_of_features TEXT,list_of_features_to_exclude TEXT,weights TEXT)RETURNS VOID AS $$SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, $6, $7, 30::INTEGER);$$ LANGUAGE sql VOLATILE;CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train(training_table_name TEXT,output_table_name TEXT,id_col_name TEXT,dependent_variable TEXT,list_of_features TEXT,list_of_features_to_exclude TEXT)RETURNS VOID AS $$SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, $6, NULL::TEXT);$$ LANGUAGE sql VOLATILE;CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train(training_table_name TEXT,output_table_name TEXT,id_col_name TEXT,dependent_variable TEXT,list_of_features TEXT)RETURNS VOID AS $$SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, NULL::TEXT);$$ LANGUAGE sql VOLATILE;
其中,输入表、输出表、特征等必备信息需要用户指定。其他参数提供缺省的参数,比如权重weights,如果用户没有指定自定义参数,程序会用默认的参数进行运算。
在SQL层定义PL/python接口,代码如下:
CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train(training_table_name TEXT,output_table_name TEXT,id_col_name TEXT,dependent_variable TEXT,list_of_features TEXT,list_of_features_to_exclude TEXT,weights TEXT,num_trees INTEGER,num_random_features INTEGER,max_tree_depth INTEGER,min_split INTEGER,min_bucket INTEGER,num_bins INTEGER,null_handling_params TEXT,is_classification BOOLEAN,predict_dt_prob TEXT,learning_rate DOUBLE PRECISION,verbose BOOLEAN,sample_ratio DOUBLE PRECISION)RETURNS VOID AS $$PythonFunction(gbdt, gbdt, gbdt_fit)$$ LANGUAGE plpythonu VOLATILE;
PL/pgSQL或者SQL函数最终会调用到一个PL/python函数。
“PythonFunction(gbdt, gbdt, gbdt_fit)”是固定的用法,这也是一个封装的m4宏,会在编译安装的时候,会进行宏替换。
PythonFunction中,第一个参数是文件夹名,第二个参数是文件名,第三个参数是函数名。PythonFunction宏会被替换为“from gdbt.gdbt import gbdt_fit”语句。所以要保证文件路径和函数正确。
在python层中,实现训练函数,代码如下:
def gbdt_fit(schema_madlib,training_table_name, output_table_name,id_col_name, dependent_variable, list_of_features,list_of_features_to_exclude, weights,num_trees, num_random_features,max_tree_depth, min_split, min_bucket, num_bins,null_handling_params, is_classification,predict_dt_prob = None, learning_rate = None,verbose=False, **kwargs):…plpy.execute("""ALTER TABLE {training_table_name} DROP COLUMN IF EXISTS gradient CASCADE""".format(training_table_name=training_table_name))create_summary_table(output_table_name, null_proxy, bins['cat_features'],bins['con_features'], learning_rate, is_classification, predict_dt_prob,num_trees, training_table_name)
在python层实现预测函数,代码如下:
def gbdt_predict(schema_madlib, test_table_name, model_table_name, output_table_name, id_col_name, **kwargs):num_tree = plpy.execute("""SELECT COUNT(*) AS count FROM {model_table_name}""".format(**locals()))[0]['count']if num_tree == 0:plpy.error("The GBDT-method has no trees")elements = plpy.execute("""SELECT * FROM {model_table_name}_summary""".format(**locals()))[0]…
在py_in文件中,定义相应的业务代码,用python实现相应处理逻辑。
在安装阶段,sql_in和py_in会被GNU m4解析为正常的python和sql文件。这里需要指出的是,当前MADlib框架只支持python2版本,因此,上述代码实现也是基于python2完成的。
7.5 MADlib在openGauss上的使用示例
这里以通过支持向量机算法进行房价分类为例,演示具体的使用方法。
(1) 数据集准备,代码如下:
DROP TABLE IF EXISTS houses;CREATE TABLE houses (id INT, tax INT, bedroom INT, bath FLOAT, price INT, size INT, lot INT);INSERT INTO houses VALUES(1 , 590 , 2 , 1 , 50000 , 770 , 22100),(2 , 1050 , 3 , 2 , 85000 , 1410 , 12000),(3 , 20 , 3 , 1 , 22500 , 1060 , 3500),…(12 , 1620 , 3 , 2 , 118600 , 1250 , 20000),(13 , 3100 , 3 , 2 , 140000 , 1760 , 38000),(14 , 2070 , 2 , 3 , 148000 , 1550 , 14000),(15 , 650 , 3 , 1.5 , 65000 , 1450 , 12000);
(2) 模型训练
① 训练前配置相应schema和兼容性参数,代码如下:
SET search_path="$user",public,madlib;SET behavior_compat_options = 'bind_procedure_searchpath';
② 使用默认的参数进行训练,分类的条件为‘price < 100000’,SQL语句如下:
DROP TABLE IF EXISTS houses_svm, houses_svm_summary;SELECT madlib.svm_classification('public.houses','public.houses_svm','price < 100000','ARRAY[1, tax, bath, size]');
(3) 查看模型,代码如下:
\x onSELECT * FROM houses_svm;\x off
结果如下:
-[ RECORD 1 ]------+-----------------------------------------------------------------coef | {.113989576847,-.00226133300602,-.0676303607996,.00179440841072}loss | .614496714256667norm_of_gradient | 108.171180769224num_iterations | 100num_rows_processed | 15num_rows_skipped | 0dep_var_mapping | {f,t}
(4) 进行预测,代码如下:
DROP TABLE IF EXISTS houses_pred;SELECT madlib.svm_predict('public.houses_svm','public.houses','id','public.houses_pred');
(5) 查看预测结果,代码如下:
SELECT *, price < 100000 AS actual FROM houses JOIN houses_pred USING (id) ORDER BY id;
结果如下:
id | tax | bedroom | bath | price | size | lot | prediction | decision_function | actual----+------+---------+------+--------+------+-------+------------+-------------------+--------1 | 590 | 2 | 1 | 50000 | 770 | 22100 | t | .09386721875 | t2 | 1050 | 3 | 2 | 85000 | 1410 | 12000 | t | .134445058042 | t…14 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | f | -1.9885277913972 | f15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | t | 1.1445697772786 | t(15 rows)
查看误分率,代码如下:
SELECT COUNT(*) FROM houses_pred JOIN houses USING (id) WHERE houses_pred.prediction != (houses.price < 100000);
结果如下:
count-------3(1 row)
(6) 使用svm其他核进行训练,代码如下:
DROP TABLE IF EXISTS houses_svm_gaussian, houses_svm_gaussian_summary, houses_svm_gaussian_random;SELECT madlib.svm_classification( 'public.houses','public.houses_svm_gaussian','price < 100000','ARRAY[1, tax, bath, size]','gaussian','n_components=10', '', 'init_stepsize=1, max_iter=200' );
进行预测,并查看训练结果。
DROP TABLE IF EXISTS houses_pred_gaussian;SELECT madlib.svm_predict('public.houses_svm_gaussian','public.houses','id', 'public.houses_pred_gaussian');SELECT COUNT(*) FROM houses_pred_gaussian JOIN houses USING (id) WHERE houses_pred_gaussian.prediction != (houses.price < 100000);
结果如下:
count-------+0(1 row)
(7) 其他参数
除了指定不同的核方法外,还可以指定迭代次数、初始参数,比如init_stepsize,max_iter,class_weight等。
7.6 演进路线
openGauss当前通过兼容开源的Apache MADlib机器学习库来具备机器学习能力。通过对原有MADlib框架的适配,openGauss实现了多种自定义的工程化算法扩展。
除兼容业界标杆PostgreSQL系的Apache MADlib来获得它的业务生态外,openGauss也在自研原生的DB4AI引擎,并支持端到端的全流程AI能力,这包括模型管理、超参数优化、原生的SQL-like语法、数据库原生的AI算子与执行计划等,性能相比MADlib具有5倍以上的提升。该功能将在后续逐步开源。
八、小结
本章中,介绍了openGauss团队在AI与数据库结合中的探索,并重点介绍了AI4DB中的参数自调优、索引推荐、异常检测、查询时间预测、慢SQL发现等特性,以及openGauss的DB4AI功能。无论从哪个方面讲,AI与数据库的结合远不止于此,此处介绍的这些功能也仅是一个开端,在openGauss的AI功能上还有很多事情要做、还有很多路要走。包括AI与优化器的进一步结合;打造全流程的AI自治能力,实现全场景的故障发现与自动修复;利用AI改造数据库内的算法与逻辑等都是演进的方向。
虽然AI与数据库结合已经取得了长远的进步,但是还面临着如下的挑战。
(1) 算力问题:额外的AI计算产生的算力代价如何解决?会不会导致性能下降。
(2) 算法问题:使用AI算法与数据库结合是否会带来显著的收益?算法额外开销是否很大?算法能否泛化,适用到普适场景中?选择什么样的算法更能解决实际问题?
(3) 数据问题:如何安全的提取和存储AI模型训练所需要的数据,如何面对数据冷热分类和加载启动问题?
上述问题在很大程度上是一个权衡问题,既要充分利用AI创造的灵感,又要充分继承和发扬数据库现有的理论与实践,这也是openGauss团队不断探索的方向。
往期推荐

