




一、Oracle基础入门
数据库管理系统软件
网络数据库管理系统:
(RDBMS:关系型数据库管理系统:以表为单位来存储数据)
MySQL,SQLServer,Oracle
DB2,Informix,Sybase.......
管理,操作数据库中的数据都是通过sql(结构化查询语言)来实现的
Oracle使用(如何进Oracle11g里面的数据库)
Oracle11g:是一个Oracle数据库系统(Oracle数据库服务器)
1.在Oracle11g的系统下可以创建多个数据库
2.在安装Oracle11g的时候会自动创建一个数据库(orcl)
(如果在Oracle11g中有数据库那么需要使用相对的帐户/密码才能
进入数据库)
sys,system--->manager
oracle11g安装完成后会存在一些内置的帐户;
内置的帐户: 1.普通用户:scott--->tiger
2.管理员:sys,system
当然我们也可以创建用户
3.安装好后就会存在orcl数据库,如何进入到orcl数据库
-->需提供orcl的帐户和密码
在什么地方输入帐户和密码??
--->在数据库终端(数据库客户端工具中输入)
哪些是数据库客户端工具?
--->系统自带的客户端工具(sqlplus.exe)
--->第三方的客户端工具
(PL/SQLDeveloper,自已写的程序)
注意:
在使用oracle数据库客户端工具进入数据库之前 需要启动数据库服务及监听器(监听程序)
1>启动服务
services.msc->进入操作系统的服务面板
-->启动对应的oracle数据库服务(
在oracle中每创建一个数据库就会生成一个对应的服务;
数据库的服务名称:oracleservice+数据库名称 )
net start|stop oracleserviceservice
2>启动监听器
lsnrctl start|stop
二.Oracle数据库的结构
1>逻辑结构
数据库-->表空间-->数据段-->数据区间-->数据块
2>物理结构
数据文件(dbf):存储数据的
日志文件(log):记录数据库操作的日志信息
控制文件(ctl):记录物理文件的信息(位置,大小,创建时间)
三.如何创建自定义的用户(要使用管理员来创建)
1>创建用户
create user 用户名 identified by 密码
[default tablespace 表空间的名称]
分析:1>创建用户时,用户使用的表空间应存在,如果不存在则要先创建
表空间;
2>表空间也有内置的,也可以创建表空间
3>如果创建用户时没有指定表空间,那么该用户默认使用user表空间
eg:
javasmart/manager--->newtablespace(c:/.../javasmart.dbf)
如果用javasmart进入orcl数据库后所存储的数据在javasmart.dbf中
当新建一个新用户后,当前这个新用户还不能连接数据库;还需要管理员授权后方可连接数据库
grant connect to 新用户;
当然授权后也可以撤消权限
revoke connect from 用户
sqlplus / as sysdba
2>更改用户的表空间及密码
alter user 用户名 identified by 密码
[default tablespace 表空间的名称]
3>删除用户
drop user 用户名 [cascade]
分析:如果加上cascade表示级联删除;
4>用户锁定与解锁
锁定:alter user 用户名 account lock;
解锁:alter user 用户名 account unlock;
5>创建表空间
create tablespace 表空间的名称 datafile 数据文件 size 大小(M)
6>删除表空间
drop tablespace 表空间名称 [including datfiles and contents]
7>修改表空间
alter tablespace 表空间名称 datafile 数据文件 size 大小(m)
8.>数据库的删除
universal installer
9.>新建数据库
dbca | DataBase Configuration Assiant
第二章(cksoft-->ckedu(c:\app\orcl\oradata\ckedu.dbf)
数据库对象:数据库中数据的集合
对象的类型:表,视图,过程,索引,序列,同义词 ..............
数据库中表是基本的对象
一.sql语句的分类
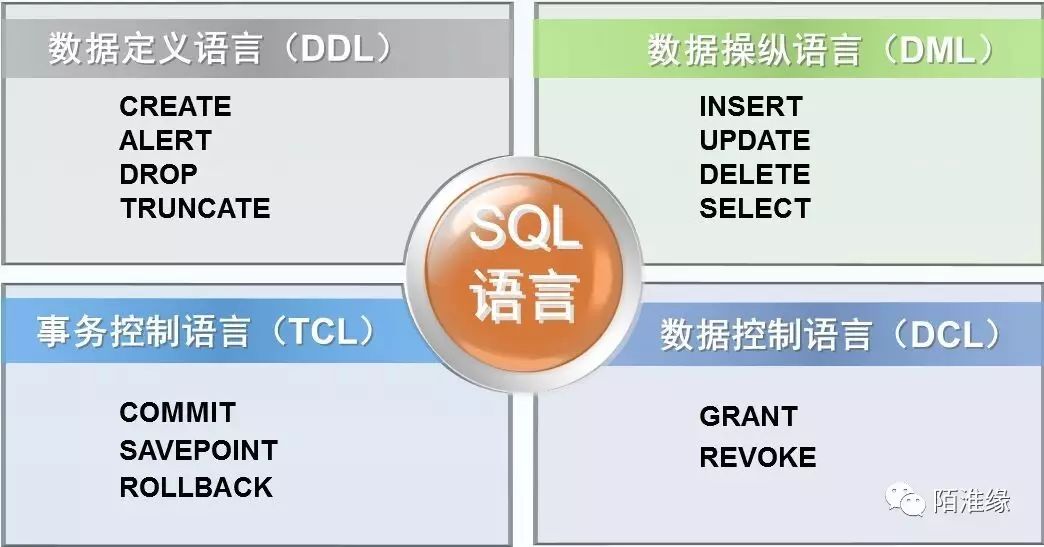
1.DDL(数据定义语言)
作用:创建,修改,删除数据库中的对象
create/alter/drop/truncate table
2.DML(数据操纵语言)->对表的数据进行操作
select/update/delete/insert
3.DCL(数据控制语言)-->对用户进行授权与权限回收操作的
grant..to/revoke..from
数据库的权限:1>系统权限 2.对象权限
4.TCL(事务控制语言)
commit/rollback
commit:提交事务
(将缓冲区的数据写入数据文件中)
rollback:撤消(回滚)事务(撤消之前的操作;
commit后的操作是不能撤消的;
DDL语句是无法撤消的;
要想数据文件中存放数据,需要在文件中创建表
create table 表名(每个字段命名及确定每个字段的类型)
在创建表时,表的设计如何做到合理?在表设计时应遵循三大范式;
第一范式(1NF)
要求表的每个字段是不可再分的
第二范式(2NF)
要求表中的每一行数据需要提供一个惟一的标识;
因此表设计时需要设计一个数据不能重复的字段;
这个字段称之为"主键字段"
第三范式(3NF)--->消除传递依赖
一个表在引用另外一个表的主键字段后,不能将另外一个表的
非主键字段设计到该表中
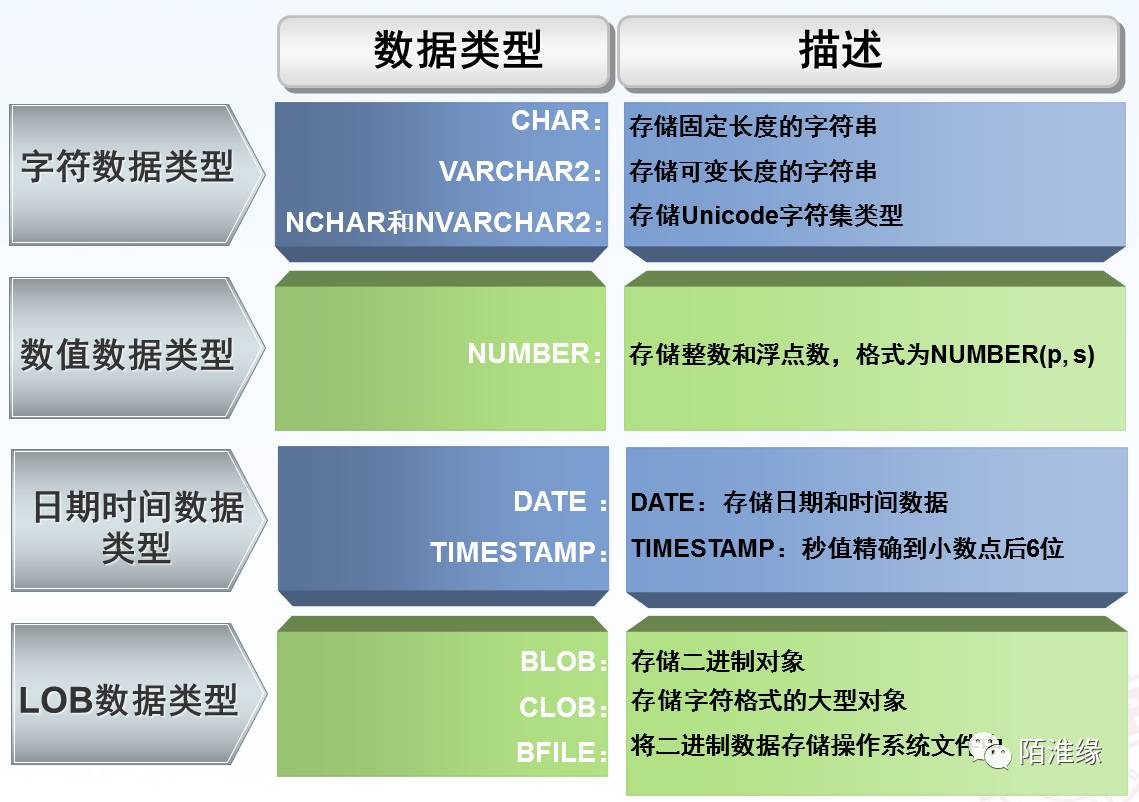
Oracle的数据类型:
字符型: char(),varchar2(),
数值型: number
日期型: date(),timestamp
大对象型: cblob(大型文本数据),blob(二进制数据:图片,视频,音频)
表结构的操作
查看表结构 : desc 表名
1>添加字段
alter table 表名 add 字段名 类型;
2>修改字段的名称
alter table 表名 rename column 字段 to 新的字段名称
3>修改字段的类型
alter table 表名 modify 字段 新的数据类型
4>删除字段
alter table 表名 drop column 字段
5>更改表名称
rename 表名 to 新表名
6>删除表
drop table 表名
向表中添加数据 insert
insert into 表名[(字段名,字段名)] values(提供各个字段的数据)
查看表中的数据 select
select * from 表名 [where|order by|group by]
模糊查找: select ..from 表名 where 字段 like ...
修改数据 update
update 表名 set 字段=值,字段=值,,.... [where ]
删除数据: delete
delete from 表名 [where];
(where可以用在select,update,delete语句中,其功能是
用于筛选,where后面需要指定筛选的条件,筛选的条件可以
有多个)
删除表中的所有数据:
1>delete from 表名
2>truncate table 表名;
3>drop table 表名
三种方式的区别:
1>delete是DML,truncate table是DDL
2>delete删除后可回滚;truncate table不可以回滚
3>delete删除数据后,并不释放数据的存储空间;
truncate table删除数据后,会释放数据的存储空间;
如果要删除表中的所有数据truncate table的性能及效率高
于delete.
4>drop是删除表 所以对应的会删除表中所有的数据
DML执行增删改后需执行commit操作
第二章
约束
函数
子查询,
连接查询
伪列(rownum,rowid)
1.约束
主键:(某一个字段的值不能重复)
1>建立表时在主键字段的类型后加:primary key
2>通过修改表结构来创建主键约束
惟一:(不能重复;主键其实就是惟一约束)
check约束:(eg:年龄0-120)
alter table stuinfo add constraint checkage check (age>0 and age<=120);
alter table stuinfo add constraint checksex check (sex='男' or sex='女');
外键:(如果一个表中的字段引用另外一个表的主键,该字段称为外键
1.外键的数据类型与主键类型一致
2.外键字段的值在主键中出现过 )
alter table 表名 add constraint 约束名 约束条件;
2.函数:
聚合:sum,max,min,avg,count
(聚合函数不能做为where条件及条件的值)
日期:sysdate()
字符:instr(), substr()
转换: to_char,to_number,to_date,nvl() , decode(字段,值1,结果1,[值2,结果2]..,default);
数学:
其他:
补充:(分组,分组后的筛选,in,exists)
3.子查询:(一个dml语句中又包含查询语句)
子查询可以出现在where后,或者是from后面
4.连接查询(多表查询)
同时从多个表中查询
select * from dept,emp
1>内连接(等值连接)
2>左外连接:左边的表是主表;会显示主表中的所有记录和
从表中符合连接条件的记录
3>右外连接:右边的表是主表;会显示主表中的所有记录和
从表中符合连接条件的记录
5.rownum,rowid(伪列)
13 4 1: 1-4 2:5-8
rownum:行号,rownum是从1开始的,依次递增
作用:实现数据的分页
select * from (select rownum rn,emp.* from emp where
rownum<=当前页*每页的记录数) e
where e.rn>(当前页-1)*每页的记录数
rowid:表中每行记录的存储地址,rowid不可能重复的
作用: 可以删除重复的数据
delete Test where rowid not in(select min(rowid) from Test group by id) delete Test ts where rowid not in (select min(rowid) from Test where ts.id=id and ts.name=name )
第三章 数据库对象 同义词,序列,索引,视图
1.同义词
在oracle中数据库中的表以用户为单元组织管管理,也就是说默认情况下,一个用户无法访问另外一个用户创建 的表;如果需访问,需指定表的所属者; 管理员所属的对象默认是不向普通用户开放的
概念:就是给用户所属的对象起一个别名
语义:create [public] synonym 同义词名称 for 用户名.对象名
drop [public] synonym 同义词名称
2.序列
产生一系列数据
语法:create sequence 序列名称
[start with n]:指定序列的起始值
[increment by n]:指定序列每次增长的值
[minvalue n]:设置序列循环时的起始值
[maxvalue n]:指定序列的最大值
[cycle]:设置序列可以循环
[cache n]:设置缓存的数据大小(默认是20)
创建序列时如果没有指定任何参数,序列是从1开始,
每次增长1,没有最大值的限制
minvalue:用于设置序列循环的初始值,
如没有指定循环从1开始;minvalue的值不能大于
start with的值
1>序列的两个属性
currval:获取序列的当前值
(序列在首次使用时,不能使用currval属性,因为序列还未初始化;因此首次需通过nextval属性让序列初始化)
nextval:获取序列产生的下一个数据
3.索引
建立索引的作用:可以提高查询数据的速度,提升性能
原理: 为什么建立索引可以提高查询速度?
如果没有建立索引的情况下,会进行全表扫描,假设一张表有1000w
一旦建立索引后,就会生成一个索引页的存储结构,在数据库索引页的结构是树的结构
使用场景:
1>表的数据量比较大(1w)
2>通常对经常用做查询条件的字段建立索引
3>索引字段不是越多越好
使用索引应注意的问题
1>索引字段不是越多越好
2>如果一个增删改操作多,查询操作少,这样的表最好不要建索引
3>索引会减缓表的增删改的速度
4>建立索引后,索引不一定会生效
1>使用!= ,like
2>使用or时,前后条件字段都建立索引,索引生效
3>避免在索引字段进行计算
4>对于组合索引,同时查询通常会生效,如果不同时查询使用索引左边
的字段查询此时索引会生效
5>如果一个字段有大量的重复数据,针该字段建立索引没有太大的意义
如何建立索引:
索引字段并非越多越好,对于经常用做查询条件的字段
对于有大量重复数据的字段,创建索引是不合理的
建立索引
语法:
create index empnameIndex on 表名(字段名)
索引的分类:
普通索引:create index 索引名称 on 表名(字段名)
位图索引:create bitmap index 索引名称 on 表名(字段名)
惟一索引:create unique index 索引名称 on 表名(字段名)
主键就是一个特殊的惟一索引
组合索引:create index 索引名称 on 表名(字段1,字段2)
场景:如果经常使用多个字段同时查询
基于函数的索引:create index 索引名称 on 表名 函数
索引的不足:
减缓了数据的增,删,改的效率
4.视图
作用:通过视图可以简化数据查询操作
语法: create view 视图名 as select ..........
注意:视图对象并不存储数据; 通过查询视图得到的数据,仍然是从表中查询出来的
数据字典表:通过数据字典表可以查询数据库中各种对象的信息
user_
表示当前用户自已创建的该数据库对象
all_
表示当前用户自已创建的该数据库对象和有权限使用的数据库对象
dba_ (只有管理员才有权限)
所有的该数据库对象
user_tables,user_synonyms,user_views,
user_sequences,user_indexes
user_tablespaces
user_objects:存储数据中所能的数据库对象信息
第四章 PL/SQL程序设计
引言:使用PL/SQL其目的是为了解决复杂的数据操作;因为PL/SQL可以
将多条sql语句做为一个整体来执行,同时在执行这些语句的过程中
可以加入控制结构
如何使用PL/SQL??
PLSQL三部分组成:
[1.定义部分]
2.执行部分
(执行部分可以的内容有 :
1>.控制结构,变量的赋值
2>.sql语句:
默认只能执行insert,update,delete,select into
以及TCL;如果想在pl/sql执行部分执行DDL,DCL,select查询
应该将DDL,DCL,select查询当做动态sql来执行.
执行动态sql语句:
execute immediate '要执行的语句';
[3.异常处理部分]
如何使用变量
声明: 变量名 数据类型;
赋值: 1>变量名:=值;
2>通过select into 变量
(select into赋值时,select查询的结果应是单行的)
(数据类型:%type,%rowtype,cursor(游标)
%type: 声明变量时,让该变量和表的字段类型保持一致
%rowtype:该变量用于存储表中的一行数据
cursor:是一个查询结果集;如果需要使用一个变量存储结果集的数据
可以声明一个游标类型的变量
游标使用:
1>声明游标 declare cursor 变量 is select......
2>打开游标 open 游标变量
3>循环从游标中取数据 fetch 游标变量 into 中间变量
4>关闭游标 close 游标变量
循环游标:如果按照上述的步骤使用游标有点麻烦;使用循环游标可以简化步骤
控制结构:
条件:if ..case when .....end case
循环:
1>基本循环 loop ....end loop
2>while循环 while loop ....... end loop;
3>for循环 for loop ......... end loop;
第五章: 子程序与程序包
命名块: 有名称的PL/SQL代码块;将会以对象的形式存在数据库中;
在oracle中命名块有子程序和程序包这两种
子程序分为两种:1>过程(存储过程) 2.函数
1.过程
语法:
过程的参数可以有多个,其参数的模式可以是三种之一:
in :表示该参数是输入参数;默认是in
out :表示该参数是输出参数
in out:表示该参数即可以是输入参数也可以是输出参数
执行:
1>excute|exec 过程名;
2>匿名块
2.函数
语法:创建自定义的函数,必须指定该函数的返回类型
调用
1>select 语句中
2>匿名块
3.程序包:
管理子程序的对象,也就是说一个包中可以有若干个子程序
一个程序包由两部分组成:1>包规范 2>包体
因此在创建程序包时应分别创建包规范和包体
包规范:指程序包有那些子程序
包体:是包规范中的子程序的实现
调用:和上面一样,只是要在调用加上包名
程序包分为:内置包和自定义的包。
4.数据迁移
3-1>数据导出
exp 用户名/密码 file=**.dmp owner=用户名
3-2>数据导入
imp 用户名/密码 file=***.dmp full=y
5.调优
分析sql语句的执行计划
1.sqlplus 中
set autotrace on
set timing on
2.pl/sql developer
F5
6.Oracle和MySQL的区别
6.1.Oracle是大型数据库而Mysql是中小型数据库
6.2. Oracle支持大并发,大访问量,是OLTP最好的工具。
6.3. 安装所用的空间差别也是很大的,Mysql占用空间较小,Oracle占用空间较大,且使用 的时候Oracle占用特别大的内存空间和其他机器性能。
6.4Oracle和MySQL一些操作上的区别
1.自动增长的数据类型处理
2.单引号的处理
3.分页的sql语句处理
4.长字符串的处理
5.日期字段的处理
6.空字符的处理
7.字符串的模糊比较
7.MySQL vs Oracle操作上的区别
1.支持字段上使用auto_increment
2.支持批量添加
3>没有提供rowid,rownum
4>使用limit关键字完成分页
select * from dept limit 0,2
0:起始行的索引
2:每页显示的数量
