




自动分区
自动分区,指创建表时不指定任何分区定义(如分区键、分区策略等),PolarDB分布式版能够自动选择分区键并对表及其索引进行水平分区的功能。AUTO模式数据库支持自动分区,而DRDS模式数据库不支持。
示例如下:
使用标准的MySQL语法创建tb表,语法上不包含任何分区定义:
CREATE TABLE tb(a INT, b INT, PRIMARY KEY(a));复制
- 上述DDL在DRDS模式数据库中创建出来的表是一张单表(如下图所示,默认不分区):
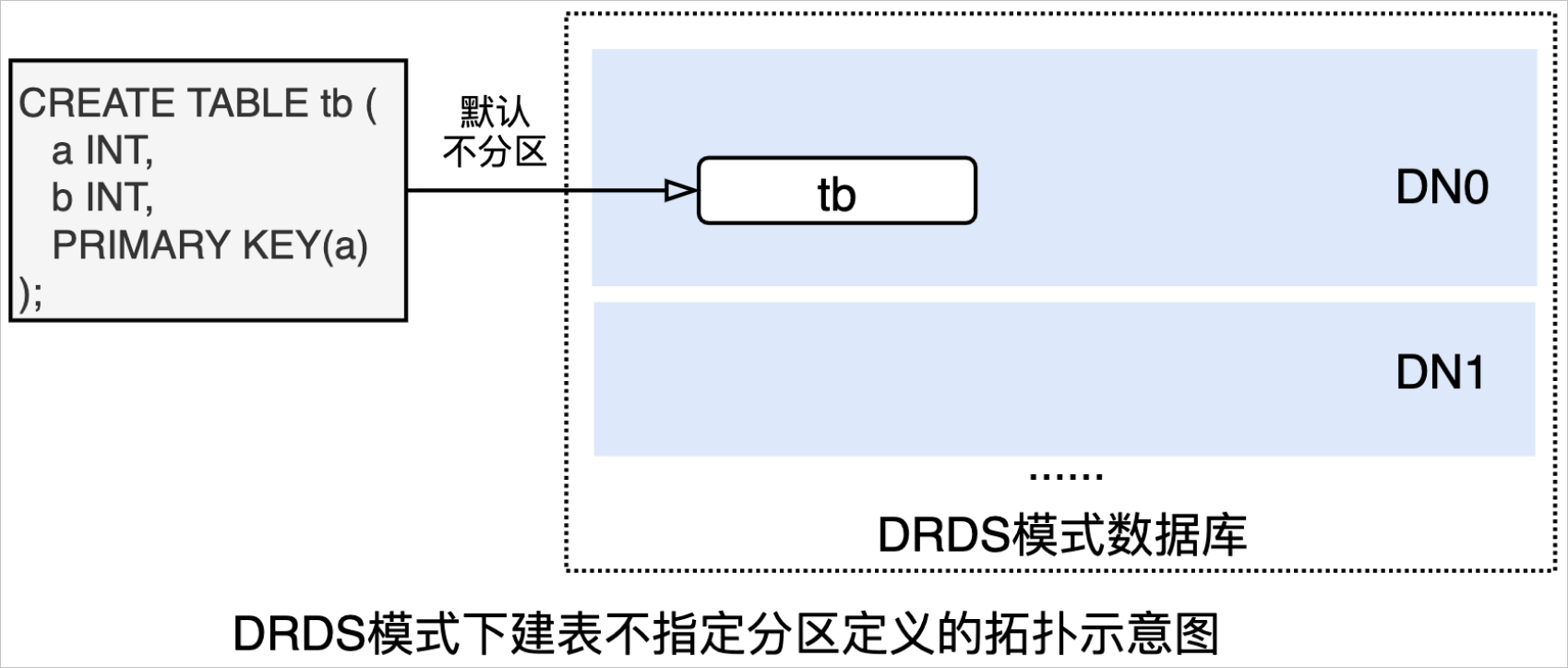
执行
SHOW语句,查看完整建表语句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 1 row in set (0.02 sec)复制 - 上述DDL在AUTO模式数据库建来的表将是一分区表(如下图所示,默认按主键自动分区):
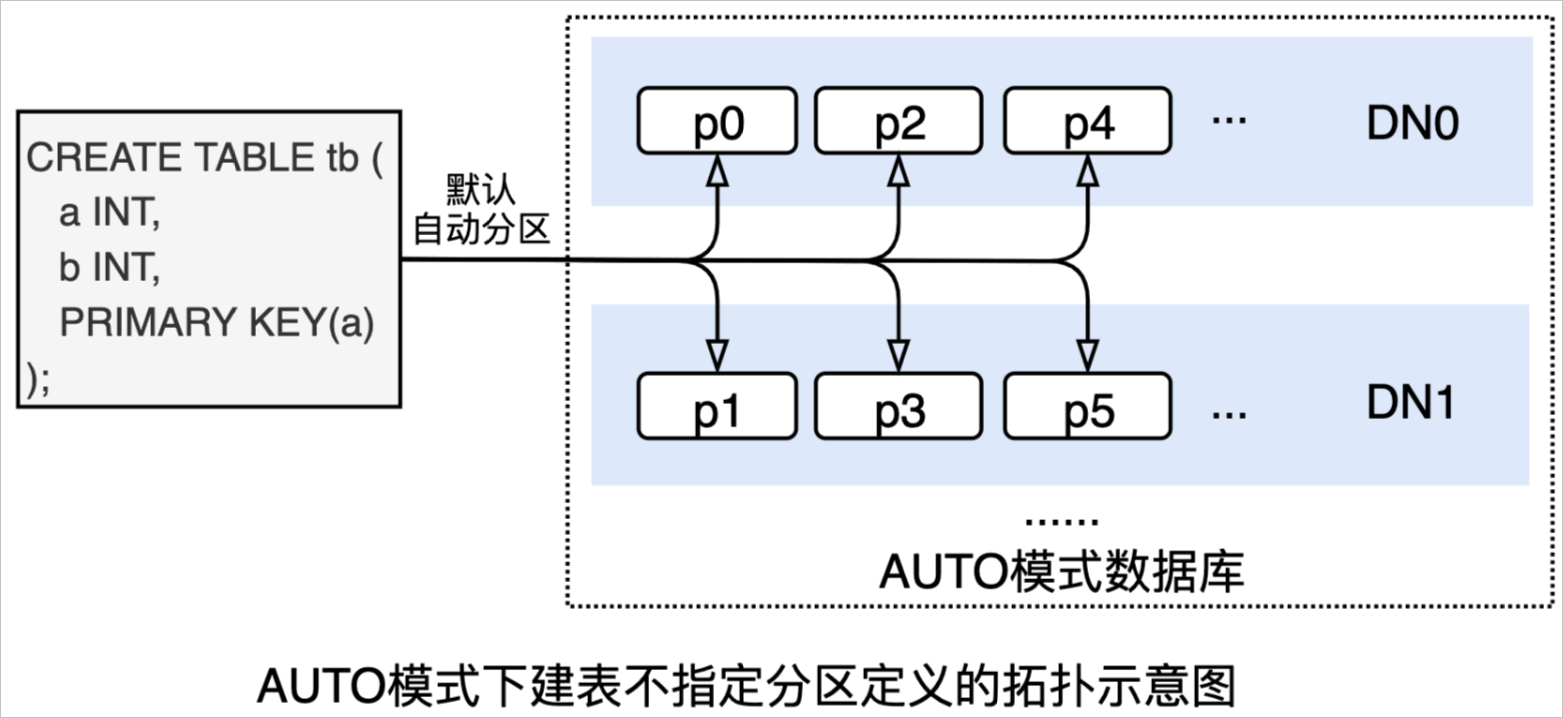 执行
执行SHOW语句,查看完整建表语句:SHOW FULL CREATE TABLE tb \G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE PARTITION TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 16 1 row in set (0.01 sec)复制
因此,在AUTO模式数据库下,只需要使用标准的MySQL建表语法(包括建索引语法等)创建表,PolarDB分布式版的自动分区功能可以让应用便捷地享受到分布式数据库所带来的弹性伸缩、分区管理等诸多红利。
手动分区手动分区,即创建表时显式指定分区定义(如分区键、分区策略等)。AUTO模式数据库与DRDS模式数据库采用手动分区时的建表语法不同。
- AUTO模式数据库:创建表使用标准的MySQL分区表语法,并支持HASH、RANGE、LIST等多种分区策略。
如下示例,创建tb表时使用
PARTITION BY HASH(a)语法,指定了分区键a列及HASH的分区策略:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> PARTITION by HASH(a) PARTITIONS 4; Query OK, 0 rows affected (0.83 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** TABLE: tb CREATE TABLE: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(`a`) PARTITIONS 4 1 row in set (0.02 sec)复制 - DRDS模式数据库:创建表使用DRDS专用的分库分表语法,仅支持使用HASH策略。
如下示例,创建tb表时使用
DBPARTITION BY HASH(a) TBPARTITION BY HASH(a)语法,指定分库分表键为a列:CREATE TABLE tb (a INT, b INT, PRIMARY KEY(a)) -> DBPARTITION by HASH(a) -> TBPARTITION by HASH(a) -> TBPARTITIONS 4; Query OK, 0 rows affected (1.16 sec) SHOW FULL CREATE TABLE tb\G *************************** 1. row *************************** Table: tb Create Table: CREATE TABLE `tb` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 dbpartition by hash(`a`) tbpartition by hash(`a`) tbpartitions 4 1 row in set (0.02 sec)复制
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1375次阅读
2025-04-09 15:33:27
从mysql社区版迁移到信创PolardbX-DN上
金同学
148次阅读
2025-04-01 09:50:14
阿里云Tair KVCache:打造以缓存为中心的大模型Token超级工厂
阿里云瑶池数据库
124次阅读
2025-03-25 10:37:41
PolarSearch使用指南
快点好起来
51次阅读
2025-03-19 15:32:53
VACUUM常见问题及优化
千寻
43次阅读
2025-03-19 16:33:17
智能搜索(PolarSearch)
快点好起来
42次阅读
2025-03-19 15:21:42
备份原理
胖橘
41次阅读
2025-03-19 14:05:32
客户说|MiniMax DevOps最佳实践:基于阿里云SelectDB构建PB级日志系统
阿里云瑶池数据库
39次阅读
2025-03-20 09:51:08
Ganos全空间数据多态分层存储能力解析与最佳实践
Ganos全空间数据库
38次阅读
2025-03-26 11:08:10
向量检索使用说明
胖橘
38次阅读
2025-03-19 14:18:05
