




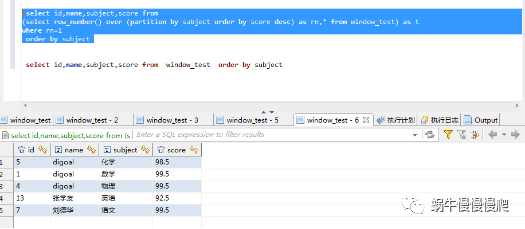
在进行数据查询时,要对数据进行分组,并找出分组中的最新数据,就会用到几个聚合函数。
比如,找到select first row in each group by group?
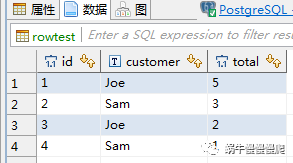
通用方法
with summary as(
select p.id,p.customer,p.total,row_number() over
( partition by p.customer order by p.total desc) as ranks
from rowtest p)
select s.id,s.customer,s.total from summary s where s.ranks=1
结果:
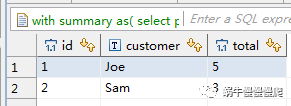
这种方法中,用到了聚合函数row_number()
在德哥的博客中,提到这几种聚合函数的用法
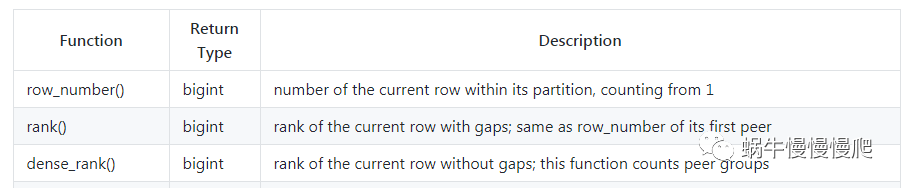
row_number是按分组排序,并取每个分组中的一条数据
rank和dense_rank也是按分组排序,可以取并列第一
比如:
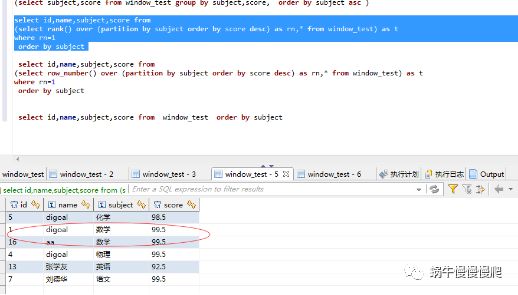
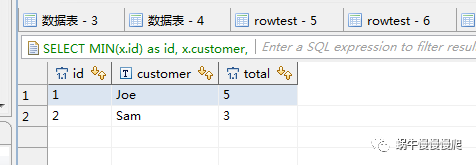
2.select 分组取第一条数据,不用聚合函数
SELECT MIN(x.id), -- change to MAX if you want the highest
x.customer,
x.total
FROM rowtest x
JOIN (SELECT p.customer,
MAX(total) AS max_total
FROM rowtest p
GROUP BY p.customer) y ON y.customer = x.customer
AND y.max_total = x.total
GROUP BY x.customer, x.total
3.用distinct on方法
DISTINCT ON ( expression [, …] ) keeps only the first row of each set of rows where the given expressions evaluate to equal. […]。 Note that the “first row” of each set is unpredictable unless ORDER BY is used to ensure that the desired row appears first. […]。 The DISTINCT ON expression(s) must match the leftmost ORDER BY expression(s)。
意思是DISTINCT ON ( expression [, …] )把记录根据[, …]的值进行分组,分组之后仅返回每一组的第一行。需要注意的是,如果你不指定ORDER BY子句,返回的第一条的不确定的。如果你使用了ORDER BY 子句,那么[, …]里面的值必须靠近ORDER BY子句的最左边。
SELECT DISTINCT ON (customer)
id, customer, total
FROM rowtest
ORDER BY customer, total DESC, id
