




作者:jessegjyguo 郭爵钰
编辑:edwinzeng 曾鑫鹏
1
背景
微保用户运营中台经过前期的投入研发,需求在离线场景下已经得到了较为系统化的支持。通过对离线数据选取、干预,可实现对目标用户进行T+1触达,通过向目标用户发送Push等多种方式,在一定程度上提高转化率。
但T+1本身的延迟性会导致用户在产生特定行为时不能被实时触达,无法充分发挥数据的价值,取得更优的运营效果
在此背景下,运营业务需要着手挖掘用户行为实时数据,如实时浏览、关注公众号、续费、订阅、投放等,对满足运营需求用户进行实时触达,最大化运营活动效果。在运营实时触达需求中,基本的数据流如下:
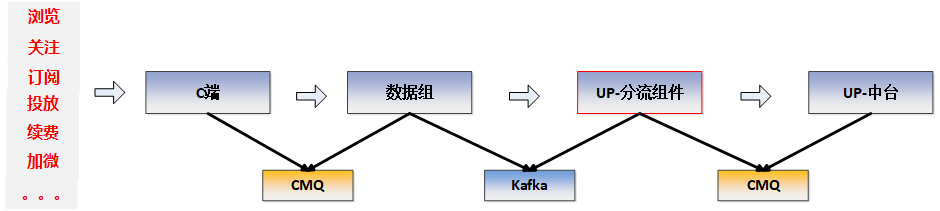
CMQ:全称Cloud Message Queue,即腾讯云计算平台提供的分布式消息队列服务。UP: 全称User operation Platform,是以工程提效、服务共享、数据赋能的方式对用户在产品中的全生命周期进行精细化运营,实现互联网保险业务的一站式用户运营解决方案。
主要存在以下特点:
数据类型多样化,不同类型事件产生不一样消息,格式也有一定差异。
上游数据可能因为历史原因存在不同的主题或队列中,可能来自cmq队列或kafka主题。
上游事件数据不是全部往下游传输,需要根据不同的条件进行转发判断,可能存在1对1,1对多或者1对0的分发情况。
条件判断不能事先确定,因为实时事件是变化的,存在根据不同情况配置不同的判断条件,并实时生效。
根据上述特点,技术目标是设计一个动态分流组件,可以将上游规格不一的消息转换为下游运营中台方便统一应用的格式。因此它应该可以动态监听cmq队列以及kafka主题,并能动态伸缩,同时能根据自助配置动态转发和限量。其简单拓扑如下:
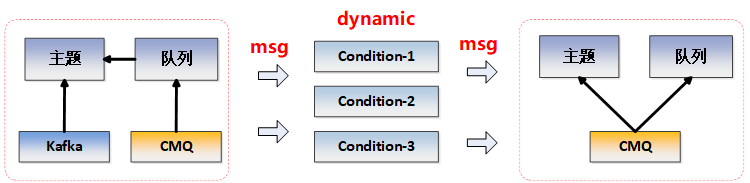
本文以上述数据流特点及要求,围绕如何设计出可动态伸缩、动态条件判断、高并发下支撑业务需求高效稳定运行的组件进行展开。
2
技术调研
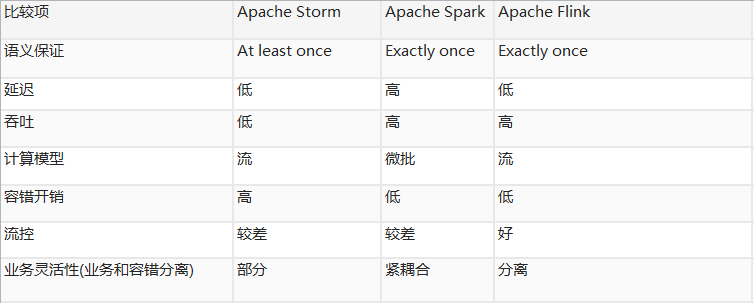
根据业务趋势,目前流式处理多采用的是flink技术引擎,相比于strom,spark前两代流处理技术,flink在流控,性能方面更加突出,并且可以利用chenkpoint机制保证消息完整性,可以通过flink on yarn 实现资源隔离,还有背压机制等,主要比较如下:
Flink 原生提供了side output 来实现分流,但需要预先定义分流标记,并且不支持连续分流,核心实现逻辑如下:
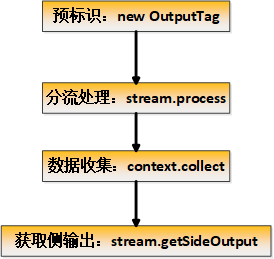
由于需要预定义分流标记,不能实现根据分流条件的新增或减少来动态实现分流,而分流的重点就是要根据配置动态实现分流,因此放弃此实现模式。
此外,Flink CEP 也有类似实现分流的能力,但要实现上述目标感觉相对比较繁琐,且并没有带来多少性能提升,特别是在动态条件处理上,而且有点杀鸡用牛刀的感觉,毕竟CEP更擅长于复杂事件处理上。
最后,我们想到flink 双流的实现方案:内部设计一条读取配置信息流,一条数据处理流,通过广播变量,更新节点信息,利用多线程以及缓存,结合动态脚本来实现上述动态分流的目的。
3
技术方案
双流+广播变量的设计思路

采用双流的目的主要有两个:
A、分流信息配置通过流读取后广播到各集群节点,保证配置信息同步生效,同时配置信息流内部采用轮询方式每隔5秒刷新配置变量:splitConfigs。另外,流内部根据最新配置,就能动态伸缩监听队列。
B、数据处理流通过常规source->map->sink 叠加广播变量来完成分流处理,无需关注配置信息处理,降低耦合,提升效率。在sink阶段,通过动态脚本的反馈结果,决定是否push或多push。
动态脚本
这里使用脚本的作用主要是实现自助化配置,产品通过简单的学习就可以自己来配置实现自己想要的转发逻辑。如下,message是一个json格式报文。
message.group.eventName=='XXX' && message.body.carInfo.licenceNo =='XXX'复制
脚本的选型,我们这里选用了groovy,因为其性能好,兼容性好,与java无缝连接,用在相对简单的条件判断处理逻辑中,比较适合,且支持对json格式的xpath取值。这样通过在数据处理流中内嵌groovy脚本,实时编译,即能实现对条件进行动态解析,达到动态转发的效果。基本操作流程如下:

缓存的设计
缓存这里直接采用ConcurrentMap,目的主要是在source阶段,缓存cmq Quene以及kafkaConsumer链接信息,从而实现链接的复用,提升性能;另外一个是缓存groovy编译脚本,从而避免每次运行重新编译脚本,降低堆内存占用,提升响应时间。编译缓存基本流程如下:
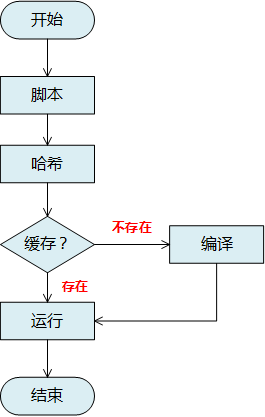
多线程使用
Flink 默认有并行度的配置,但并行度默认是跟yarn容器数一致的,如果单纯的提升并行度,可能会造成很大的资源浪费,因此,在对cmq或kafka监听时,设计为多线程处理,根据参数动态调整线程数[How?],可以充分利用机器资源、提升效率。
如在启动命令中指定的线程数量:
flink run -m yarn-cluster -ynm test-run-dev /data/up/up-xxx-SNAPSHOT.jar --env dev --mq-type cmq --thread-pool-size 5复制
连接池使用
这里连接池主要指的http连接:HttpClientConnectionManager,通过长连接与broken交互,从而提升效率。
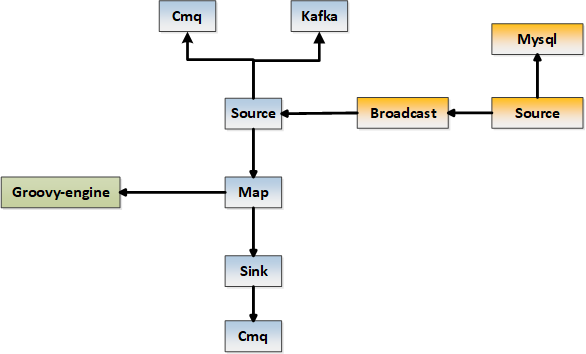
整体逻辑架构如下:
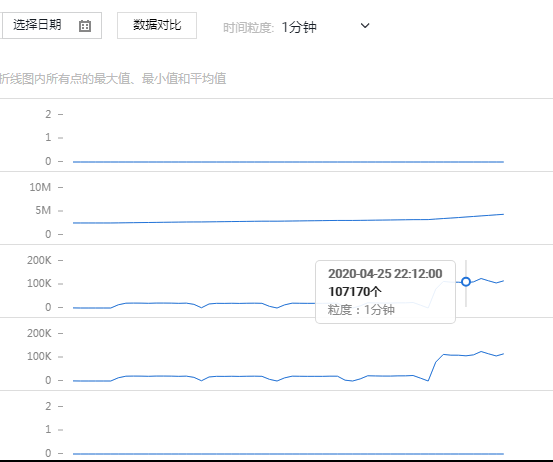
压测性能
实战案例
现有一个需求,需要将投保成功事件转发到用户运营平台,然后push消息给用户,投保事件基本格式如下:
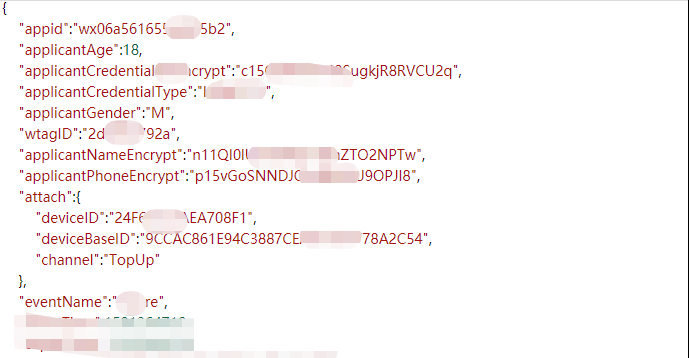
此时只需要在界面配置原消息队列,转发条件,目标队列等信息即可,如下:
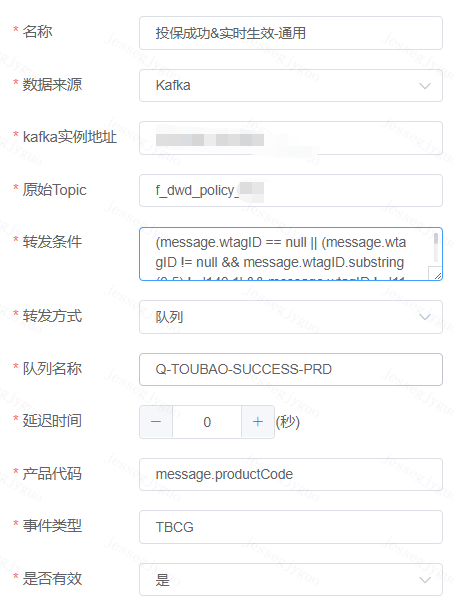
其中,转发条件为动态配置脚本。
监控
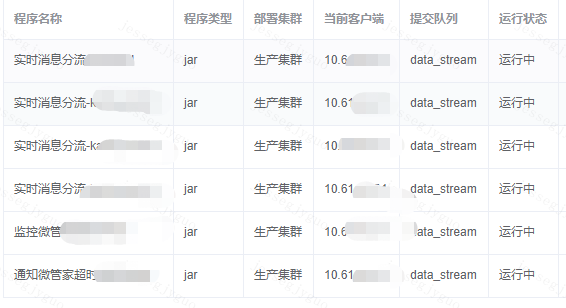
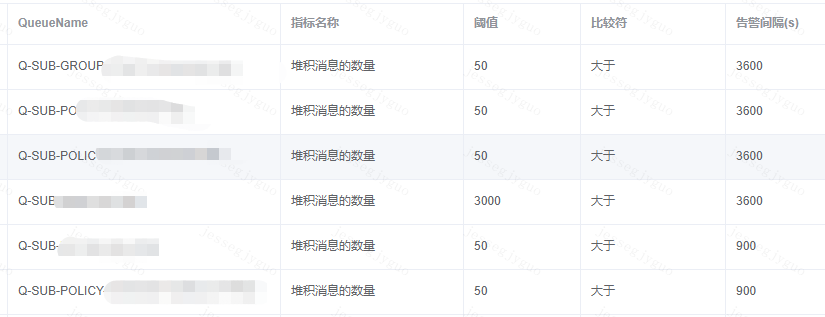
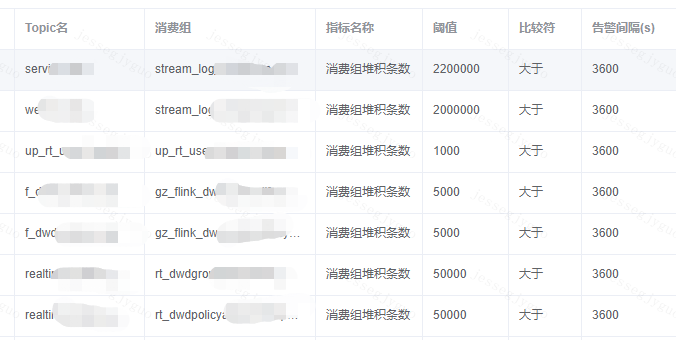
为了更好的了解组件的运行健康状况,我们除了对yarn实时任务监控,也对队列数据堆积以及数据是否存在背压方面进行了监控,如下:
Yarn任务监控:
Cmq队列数据积压监控:
Kafka消费组数据积压监控:
数据背压监控:
4
总结与展望
实时动态分流组件已上线稳定运行2个多月,是用户运营平台核心组件,起到承上启下的作用,在系统处理能力及对业务贡献方面取得了较好的效果。未来,该组件将结合到Flink在window计算、CEP处理方面的能力,进一步给业务赋能。



