




并发控制
InnoDB中可能存在大量的线程同时竞争访问Buffer Pool,包括所有通过buf_page_get_gen获取Page的用户线程和后台线程;上面提到的Flush线程;以及IO线程。作为整个数据库的数据中枢,Buffer Pool对并发访问的支持能力直接影响数据库的性能,从代码中也可以看出其中有大量锁相关的逻辑,作为一个工业级的数据库实现,这些逻辑都经过了大量细节上的优化,一定程度上增加了代码的复杂性。而锁的优化思路,无外乎降低锁粒度,减少锁时间,消除锁请求等,本节就沿着这样的思路介绍Buffer Pool中锁的设计与实现。Buffer Pool中涉及到的锁,按照锁保护对象的层次,依次分为:保护Hash表的Hash Map Lock,保护List结构的List Mutex,保护buf_block_t中结构的Block Mutex,保护真正的Page内容的Page Frame Lock。
Hash Map Lock
所有的buf_page_get_gen请求的第一步就是通过Hash Map判断Block是否存在于Buffer Pool中,可想而知这里的竞争是极其强烈的,InnoDB中采用了分区锁的办法,分区的数量可以通过innodb_page_hash_locks(16)来配置,每个分区会维护一个独立的读写锁。每次请求会先通过page_id映射到一个分区上,然后请求这个分区的读写锁。如此一来只有映射到同一个分区的请求才会产生所冲突。
List Mutex
上面讲过Buffer Pool中的Block是按照List维护的,最基础的包括维护全量使用Block的LRU List,空闲页的Free List,以及脏页的Flush List。这些List都有自己独立的互斥锁Mutex,对List的读取或修改都需要持有List本身的Mutex。这些锁的目的是保护对应的List本身的数据结构,因此会最小化到对List本身数据结构访问和修改的范围内。
Block Mutex
每个Page的控制结构体buf_block_t上都有一个block->mutex用来保护这个block的一些诸如io_fix,buf_fix_count、访问时间等状态信息。相对于外层无论是Hash Map还是List Mutex,Block Mutex的锁粒度都小的很多,通过Block Mutex来避免更长时间的持有上层容器的锁显然是划算的。而io_fix,buf_fix_count这些信息也能显著的减少对Page Lock的争抢, 比如当Buffer Pool需要从LRU上踢出一个老Page时,需要确定这个Page没有正在被使用,以及没有在做IO操作,这个是个非常常见的行为,但他本身其实并不关心Page的内容。这时,短暂的持有Block Mutex并判断io_fix状态和buf_fix_count计数,显然会比争抢Page Frame Lock更轻量。
Page Frame Lock
除了Block Mutex,buf_block_t上还有一个读写锁结构block->lock,这个读写锁保护的是真正的page内容,也就是block->frame。这个锁就是《B+树数据库加锁历史》[4]一文中讲到的保护Page的Latch,在对B+Tree的遍历和修改中都可能需要获取这把锁,除此之外,涉及到Page的IO的过程中也需要持有这把锁,Page读IO由于需要直接修改内存frame内容,需要持有X lock,而写IO的过程持有的是SX Lock,来避免有其他写IO操作同时发生。
死锁避免
当上面这些锁中的多个需要同时获取时,为了避免不同线程间发生死锁,InnoDB规定了严格的加锁顺序,也就是Latch Order,如下所示,所有对锁的获取必须要按照这个顺序从下往上进行。这个顺序跟大多数场景的使用是一致的,但也是有例外的,比如从Flush List上选择Page进行刷脏的时候,由于Flush List Mutex的级别比较低,可以看到放掉Flush List Mutex再去获取Block Mutex的情况。
enum latch_level_t {
...
SYNC_BUF_FLUSH_LIST, /* Flush List Mutex */
SYNC_BUF_FREE_LIST, /* Free List Mutex */
SYNC_BUF_BLOCK, /* Block Mutex */
SYNC_BUF_PAGE_HASH, /* Hash Map Lock */
SYNC_BUF_LRU_LIST, /* LRU List Mutex */
...
}
示例场景
为了更好的理解Buffer Pool的加锁过程,我们设想这样一种场景:一个用户读请求,需要通过buf_page_get_gen来获取Page a,首先查找Hash Map发现其不在内存,检查Free List发现也没有空页,只好从LRU的Tail先踢出一个老的Page,将其Block A加入Free List,之后再从磁盘将Page a读入Block A,最后获得这个Page a,并持有其Lock及FIX状态。得到一个如下表所示的加锁过程:
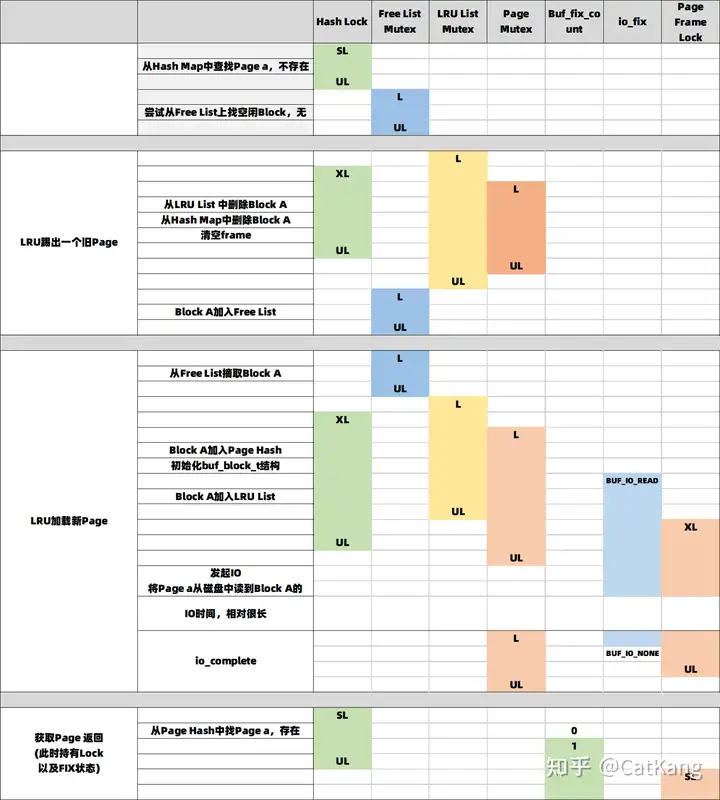
这张表中可以清楚的看到:1,每种锁都限制在真正操作其保护的数据结构的较小范围内;2,当需要同时持有多个锁时,严格遵守上面说的Latch Order,比如从LRU和Hash Map中加入或删除时,严格遵守LRU List Mutex -> Hash Map Mutex -> Block Mutex的顺序。3,在IO过程中,除了Page Frame Lock外不持有任何锁,同时也通过设置io_fix,避免了诸如LRU算法检查是否可以换出时,对Page Frame Lock加锁。篇幅关系,这里只介绍了这一种场景的加锁顺序,更多的内容可以见链接:Flush List刷脏加锁,LRU List刷脏加锁。
总结
本文聚焦于InnoDB中的Buffer Pool的核心功能,首先从宏观上介绍其背景,包括设计目标、接口、遇到的问题及替换算法的选择等;然后后从使用者的角度介绍了Buffer Pool作为一个整体对外暴露的统一接口和调用方式;之后介绍了Buffer Pool内部获取Page的详细过程以及LRU替换算法的实现;再之后介绍了Page刷脏的触发因素及过程;最后梳理了Buffer Pool如何安全的实现高并发高性能。
参考
[2] 数据库故障恢复的前世今生
[4] B+树数据库加锁历史
[5] B+树数据库故障恢复概述
[6] MySQL 8.0 Reference Manual 15.8.3.3 Making the Buffer Pool Scan Resistant
[7] MySQL 8.0 Reference Manual 15.5.1 Buffer Pool
[9] 数据库故障恢复机制的前世今生
[10] Buffer pool 并发控制
[11] Buffer Pool Performance Improvements in the InnoDB Storage Engine of MariaDB Server
[12] PolarDB 数据库内核月报
