




生产环境场景如下:请自己代入,参考链接:Mycat 与 ShardingSphere 如何选择:https://blog.nxhz1688.com/2021/01/19/mycat-shardingsphere/
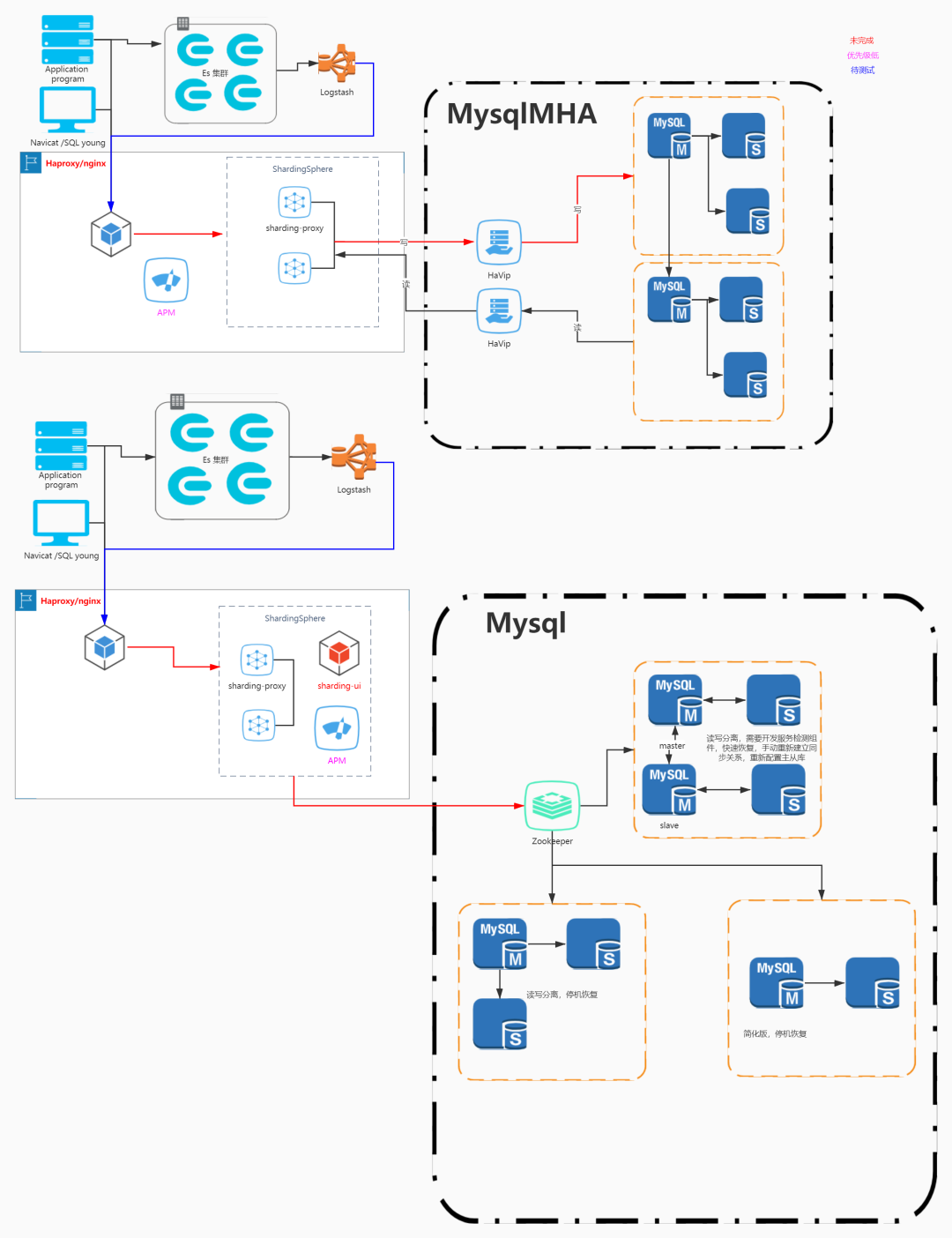
架构图:
这里提供两种解决方案,我们选择第一种,第二种需要DBA辛苦了。
1
01
路由至多数据节点
SELECT COUNT(*) FROM (SELECT * FROM t_order o)
SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
02
对分片键进行操作
SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
03
不支持的 SQL
2
01
支持的 SQL
SELECT DISTINCT * FROM tbl_name WHERE col1 = ?
SELECT DISTINCT col1 FROM tbl_name
SELECT DISTINCT col1, col2, col3 FROM tbl_name
SELECT DISTINCT col1 FROM tbl_name ORDER BY col1
SELECT DISTINCT col1 FROM tbl_name ORDER BY col2
SELECT DISTINCT(col1) FROM tbl_name
SELECT AVG(DISTINCT col1) FROM tbl_name
SELECT SUM(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1
SELECT COUNT(DISTINCT col1 + col2) FROM tbl_name
SELECT COUNT(DISTINCT col1), SUM(DISTINCT col1) FROM tbl_name
SELECT COUNT(DISTINCT col1), col1 FROM tbl_name GROUP BY col1
SELECT col1, COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1
02
不支持的 SQL
3
01
性能瓶颈
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000010
02
ShardingSphere 的优化
ShardingSphere 进行了 2 个方面的优化。
首先,采用流式处理 + 归并排序的方式来避免内存的过量占用。由于 SQL 改写不可避免的占用了额外的带宽,但并不会导致内存暴涨。与直觉不同,大多数人认为ShardingSphere 会将 1,000,010 * 2 记录全部加载至内存,进而占用大量内存而导致内存溢出。但由于每个结果集的记录是有序的,因此 ShardingSphere 每次比较仅获取各个分片的当前结果集记录,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向而已。对于本身即有序的待排序对象,归并排序的时间复杂度仅为 O(n) ,性能损耗很小。
4
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
需求如下
需要考虑的问题如下
MHA 代理服务如何处理?不能把所有的节点都配置成,分表插件的代理节点吧?
Logstash 访问的代理服务,如何处理?
底层服务访问的代理服务,如何处理?
分表插件对于 MHA 集群如何分片?如何分表?
分库分表后,数据同步 Logstash 如何进行数据同步?
分库分表插件,代理、分片、分库怎样进行合理操作?
怎样保证上下游高可用?
01
部署 Zookeeper 服务,做注册中心
docker run -p 2181:2181 --name zk --restart unless-stopped -d zookeeper
02
新建 mysql 实例
version: '3.7'services:mysql8_1:image: mysql:8.0.17container_name: mysql8_1ports:- "33080:3306"environment:MYSQL_ROOT_PASSWORD: 12345678mysql8_2:image: mysql:8.0.17container_name: mysql8_2ports:- "33081:3306"environment:MYSQL_ROOT_PASSWORD: 12345678mysql8_3:image: mysql:8.0.17container_name: mysql8_3ports:- "33082:3306"environment:MYSQL_ROOT_PASSWORD: 12345678mysql8_4:image: mysql:8.0.17container_name: mysql8_4ports:- "33083:3306"environment:MYSQL_ROOT_PASSWORD: 12345678
cd home/mysql
docker-compose up
03
部署 ShardingSphere-Proxy
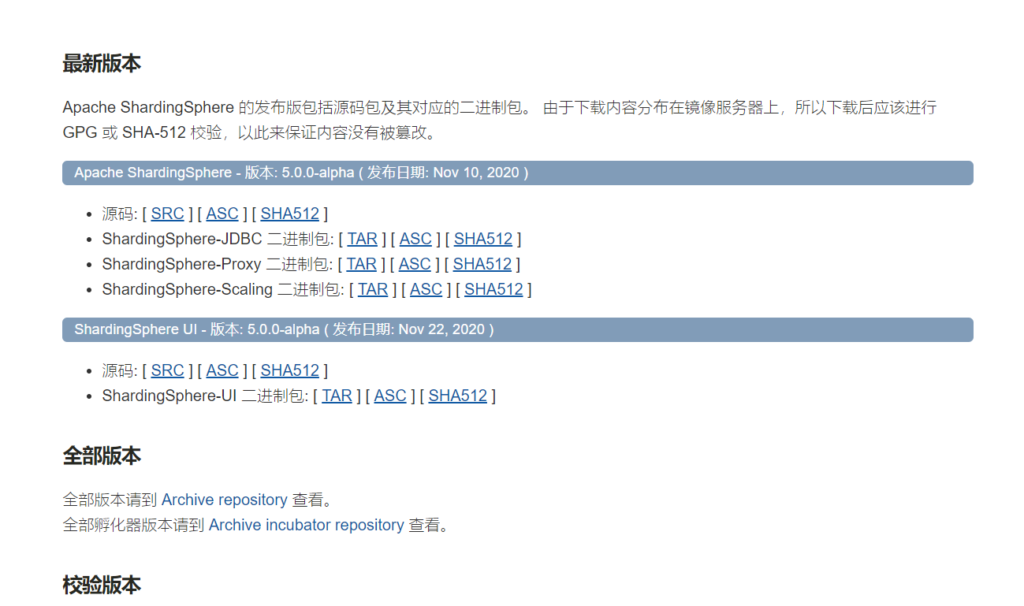
先获取镜像,可以通过 search 查询最新版👀有点懵,去官方看看推荐用什么版本 官方版本 docker search sharding-proxy 下载镜像,不写版本默认最新 docker pull apache/sharding-proxy 运行容器修改配置文件指向主机地址,替换自己的地址,我的配置放在 home 下了,别学我
docker run –name sharding-proxy -d -v home/sharding-proxy/conf:/opt/sharding-proxy/conf -v home/sharding-proxy/ext-lib:/opt/sharding-proxy/ext-lib -p13308:3308 -e PORT=3308 apache/sharding-proxy:latest
04
配置 ShardingSphere-Proxy
cd home/sharding-proxy/confvim config-test.yaml
schemaName: sharding_dbdataSources:ds_0:url: jdbc:mysql://mysql8_1:3306/demo_ds_0?serverTimezone=GMT&allowPublicKeyRetrieval=true&useSSL=false&characterEncoding=utf8ds_1:url: jdbc:mysql://mysql8_1:3306/demo_ds_1?serverTimezone=GMT&allowPublicKeyRetrieval=true&useSSL=false&characterEncoding=utf8dataSourceCommon:username: rootpassword: 12345678connectionTimeoutMilliseconds: 300000idleTimeoutMilliseconds: 600000maxLifetimeMilliseconds: 1800000maxPoolSize: 10000minPoolSize: 100maintenanceIntervalMilliseconds: 3000000rules:- !SHARDINGtables:t_order:actualDataNodes: ds_${0..1}.t_order_${0..1}tableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: t_order_inlinekeyGenerateStrategy:column: order_idkeyGeneratorName: snowflaket_order_item:actualDataNodes: ds_${0..1}.t_order_item_${0..1}tableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: t_order_item_inlinekeyGenerateStrategy:column: order_item_idkeyGeneratorName: snowflakebindingTables:- t_order,t_order_itemdefaultDatabaseStrategy:standard:shardingColumn: user_idshardingAlgorithmName: database_inlinedefaultTableStrategy:none:shardingAlgorithms:database_inline:type: INLINEprops:algorithm-expression: ds_${user_id % 2}t_order_inline:type: INLINEprops:algorithm-expression: t_order_${order_id % 2}t_order_item_inline:type: INLINEprops:algorithm-expression: t_order_item_${order_id % 2}keyGenerators:snowflake:type: SNOWFLAKEprops:worker-id: 123
# 用户通过 Navicat 访问 sharding-proxy 的用户名密码authentication:users:root: # 自定义用户名password: 12345678 # 自定义密码sharding: # 自定义用户名password: sharding # 自定义密码authorizedSchemas: sharding_db, replica_query_db # 该用户授权可访问的数据库,多个用逗号分隔。缺省将拥有 root 权限,可访问全部数据库。# sharding-proxy相关配置,建议sql.show设置为true,方便定位问题props:max.connections.size.per.query: 1acceptor.size: 16executor.size: 16proxy.transaction.enabled: falseproxy.opentracing.enabled: falsesql-show: true
05
测试 ShardingSphere-proxy 代理服务
DROP SCHEMA IF EXISTS demo_ds_0;DROP SCHEMA IF EXISTS demo_ds_1;CREATE SCHEMA IF NOT EXISTS demo_ds_0;CREATE SCHEMA IF NOT EXISTS demo_ds_1;

docker restart sharding-proxydocker logs -f sharding-proxy

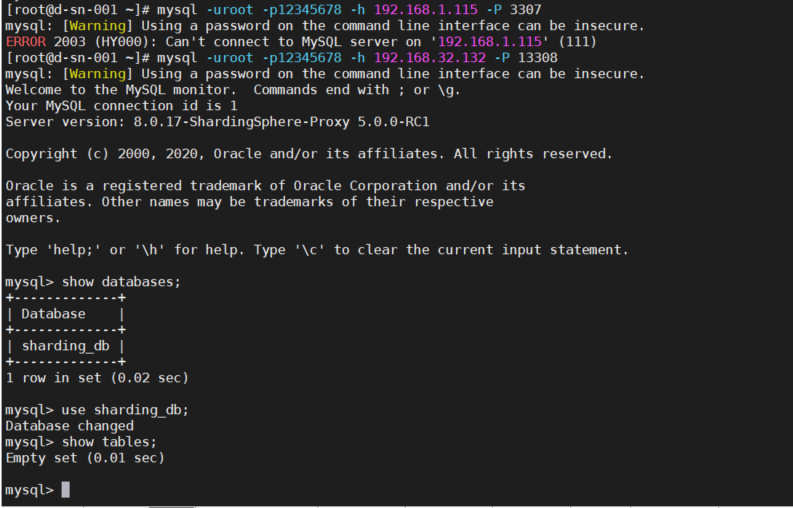
5.3 使用工具或者安装了 MySQL 客户端的命令访问ShardingSphere-proxy 代理服务
5.3.1 MySQL 客户端操作,如下操作认为服务已经代理成功
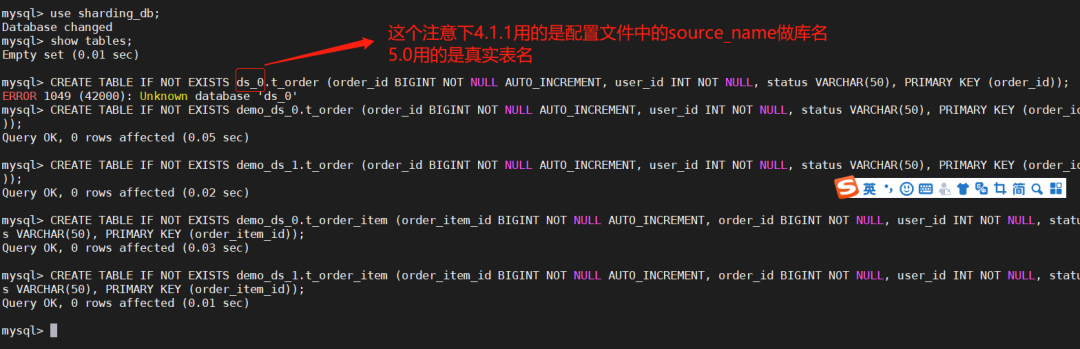
建表
CREATE TABLE IF NOT EXISTS demo_ds_1.t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id));
CREATE TABLE IF NOT EXISTS demo_ds_1.t_order_item (order_item_id BIGINT NOT NULL AUTO_INCREMENT, order_id BIGINT NOT NULL, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_item_id));
写数据
INSERT INTO t_order (user_id, status) VALUES (1, ‘init’);
INSERT INTO t_order (user_id, status) VALUES (1, ‘init’);
INSERT INTO t_order (user_id, status) VALUES (2, ‘init’);

5
Q1:openJDK 问题
A1:最终我修改容器配置处理了,使用的就是上面提到修改 /var/lib/docker/containers/ 下的配置文件,这一步大家应该也用不到,除非,你就是要用容器部署,想和使用主机的 JDK


关于 Apache ShardingSphere
Apache ShardingSphere 是一款分布式 SQL 事务和查询引擎,可通过数据分片、弹性伸缩、加密等能力对任意数据库进行增强。

