




NumPy的ndarray内部将同质数据块(可以是连续或跨越)解释为多维数组对象的方式,数据类型(dtype)决定了数据的解释方式,比如浮点数、整数、布尔值等。
ndarray所有数组对象都是数据块的一个跨度视图(strided view),数组视图arr[::2,::-1]不会复制任何数据的。
ndarray除了一块内存和一个dtype,还包括有跨度信息,使得数组能以各种步幅(step size)在内存中移动。
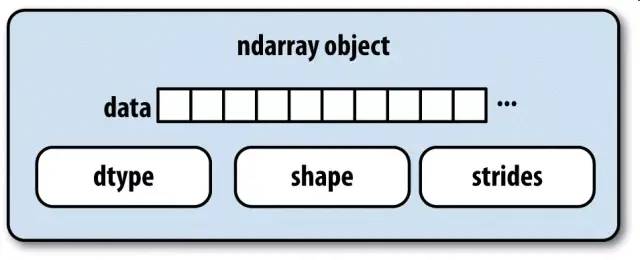
ndarray内部由以下内容组成:
一个指向数据(内存或内存映射文件中的一块数据)的指针。
数据类型或dtype,描述在数组中的固定大小值的格子。
一个表示数组形状(shape)的元组。
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要“跨过”的字节数。
ndarray的内部结构:
一个10×5的数组,其形状为(10,5):
In [10]: np.ones((10, 5)).shapeOut[10]: (10, 5)
通常,跨度在一个轴上越大,沿这个轴进行计算的开销就越大。
一个典型的3×4×5的float64(8个字节)数组,其跨度为(160,40,8):
In [11]: np.ones((3, 4, 5), dtype=np.float64).stridesOut[11]: (160, 40, 8)
跨度信息是构建非复制式数组视图的重要因素,跨度可以是负数使数组在内存中后向移动,比如在切片obj[::-1]或obj[:,::-1]中就是这样的。

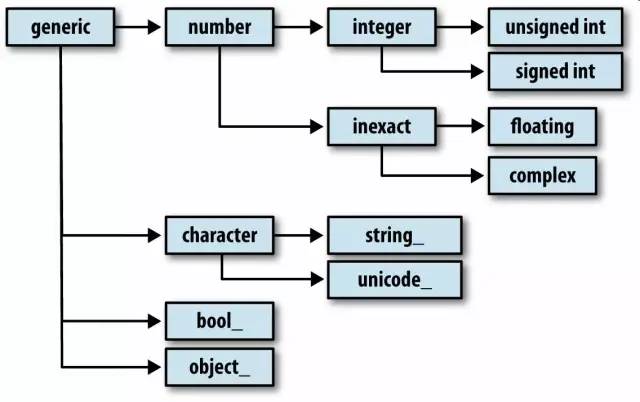
NumPy数据类型体系
浮点数的种类很多(从float16到float128),但dtype有一个超类(比如np.integer和np.floating):
In [12]: ints = np.ones(10, dtype=np.uint16)In [13]: floats = np.ones(10, dtype=np.float32)In [14]: np.issubdtype(ints.dtype, np.integer)Out[14]: TrueIn [15]: np.issubdtype(floats.dtype, np.floating)Out[15]: True
调用dtype的mro方法即可查看其所有的父类:
In [16]: np.float64.mro()Out[16]:[numpy.float64,numpy.floating,numpy.inexact,numpy.number,numpy.generic,float,object]
然后得到:
In [17]: np.issubdtype(ints.dtype, np.number)Out[17]: True
dtype体系以及父子类关系:
数组重塑
向数组的实例方法reshape传入一个表示新形状的元组即可无任何数据复制将数组从一个形状转换为另一个形状:
In [18]: arr = np.arange(8)In [19]: arrOut[19]: array([0, 1, 2, 3, 4, 5, 6, 7])In [20]: arr.reshape((4, 2))Out[20]:array([[0, 1],[2, 3],[4, 5],[6, 7]])
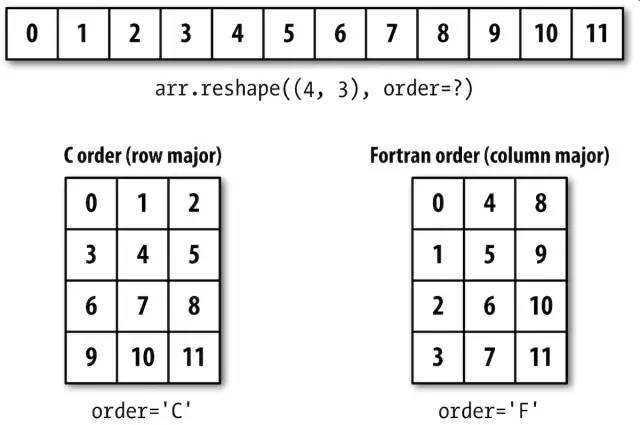
下图表示按C顺序(按行)和按Fortran顺序(按列)进行重塑:
多维数组也能被重塑:
In [21]: arr.reshape((4, 2)).reshape((2, 4))Out[21]:array([[0, 1, 2, 3],[4, 5, 6, 7]])
作为参数的形状的其中一维可以是-1,它表示该维度的大小由数据本身推断而来:
In [22]: arr = np.arange(15)In [23]: arr.reshape((5, -1))Out[23]:array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14]])
与reshape将一维数组转换为多维数组的运算过程相反的运算通常称为扁平化(flattening)或散开(raveling):
In [27]: arr = np.arange(15).reshape((5, 3))In [28]: arrOut[28]:array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14]])In [29]: arr.ravel()Out[29]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
如果结果中的值与原始数组相同,ravel不会产生源数据的副本。flatten方法的行为类似于ravel,只不过总是返回数据的副本:
In [30]: arr.flatten()Out[30]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
C和Fortran顺序
默认情况下,NumPy数组是按行优先顺序创建的,即每行中的数据项是被存放在相邻内存位置上的。列优先顺序意味着每列中的数据项是被存放在相邻内存位置上的。
行和列优先顺序又分别称为C和Fortran顺序。
reshape和reval的函数都可以接受一个表示数组数据存放顺序的order参数,一般可以是'C'或'F':
In [31]: arr = np.arange(12).reshape((3, 4))In [32]: arrOut[32]:array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])In [33]: arr.ravel()Out[33]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])In [34]: arr.ravel('F')Out[34]: array([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
按C(行优先)或Fortran(列优先)顺序进行重塑:
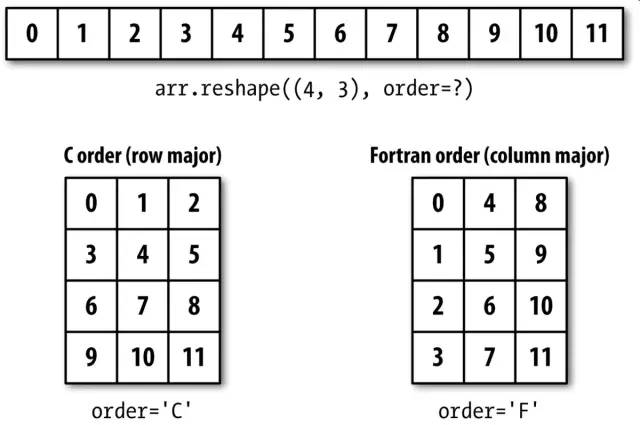
C和Fortran顺序的关键区别就是维度的行进顺序:
C/行优先顺序:先经过更高的维度(例如,轴1会先于轴0被处理)。
Fortran/列优先顺序:后经过更高的维度(例如,轴0会先于轴1被处理)。
