





原文链接:https://andyatkinson.com/blog/2023/07/28/partitioning-primary-keys-reckoning
在本系列的第2部分中,我们将重点介绍如何对一个大型分区表进行主键在线修改。由于这是一个具有破坏性的操作,因此我们必须使用一些技巧来完成。
继续阅读以了解更多信息。
如果您还没有阅读本系列的第1部分,请首先阅读PostgreSQL表分区最佳实践(1/2),该部分描述了为什么以及如何将该表转换为分区表。
其中的背景信息将有助于解释我们的操作背景。
大纲
写锁和分区表
原始主键策略
这种策略存在的问题
SQL解决方案
总结
原始背景:数据库和表
PostgreSQL 13
使用
RANGE
类型的声明性分区表的写入行为“主要是追加”
新写入速率约为每秒10-15行
75+个分区,表的大小为500 GB,包含约10亿行
子分区上有
id
列的主键约束父表上没有主键约束
分区键列为
created_at
时间戳
分区表主键
在早期的文章中,我们讨论了为什么以及如何进行在线表分区转换。
在该设计中,我们在每个子分区上设置了PRIMARY KEY
约束,但在父表上没有设置。这满足了应用程序的需求。
每个子分区的主键只有在id
列上。PostgreSQL允许子表具有没有定义在父表上的主键约束,但反过来不允许。
此外,PostgreSQL阻止在与子表冲突的父表上添加主键。1
当我们为表确定主键和唯一索引结构时,应用程序的需求和pgslice的约定驱动了决策。我们对父表上的主键没有需求。
后来我们发现这是短视的,实际上我们确实需要一个父表的主键。
这个需求不是出于应用程序,而是出于一个重要的数据消费者,我们的数据流程过程,它检测行修改并将其复制到我们的数据仓库。
数据流程出现了什么问题?
修正
一位工程师注意到,自从我们对表进行了分区后,数据仓库中的查询量过多。
数据仓库试图识别新的和已更改的行,但在没有父表上的主键的情况下,这样做变得效率低下。这种效率低下导致数据仓库的成本激增,我们按查询收费,这就成为需要尽快解决的问题!
团队开会后,我们决定采取的最佳措施是修改主键定义,使其存在于父表中。尽管解决方案很明确,但应用更改立即出现问题。
在PostgreSQL表分区中,父表和子表的主键必须匹配。对于分区父表,主键必须包含分区键列,这与我们需要解决的子表产生了不一致。
我们想要在父表上创建一个涵盖id
和created_at
列的复合主键。
没有问题,我们只需修改所有表的主键,对吗?不幸的是,这种修改类型会对表进行写锁定,这意味着如果我们遗漏了写入,将会有一个长时间的数据丢失期,这是不可接受的解决方案。我们需要另一种选择。
我们不希望进行计划的停机时间,但我们希望修改主键定义,并且知道修改需要很长时间才能运行。
我们如何解决这个问题?
解决方案和实施
同一个表需要在大约10个生产数据库中进行修改,这些数据库的大小从小到大不等。对于较小的数据库,我们修改了子表和父表的主键,并且可以容忍新写入的锁定持续时间。
对于大型数据库,我们实际上可以容忍锁定的持续时间,因此我们采用了直接的解决方案。我们删除了现有的子键,并将新的主键定义添加到父表中,然后传播到子表。然而,对于大型数据库,我们需要一个独特的解决方案。
我们尝试了各种方法,最终选择了一系列技巧来实现在线修改。
该策略通过在表与并发事务断开连接时执行修改,有效地“隐藏”了锁定期。为了实现这一点,我们使用了一个占位符表,该表在原始表在后台进行修改时继续接收写入和查询。
对于占位符表,我们复制了原始表。我们使用重命名的事务交换了占位符,这样就不会丢失任何写入。
应用程序
也会从此表读取SELECT
查询和少量的UPDATE
查询。
我们决定将一些数据复制到占位符中,以供读取使用。在不再需要占位符后,我们将丢弃它。
为了使复制过程更快,我们使用了COPY
命令,并在最后进行了增量复制。
以下命令将月份数据的内容导出到文件中。
\copy tbl_202305 TO '/tmp/tbl_202305_dump.csv' DELIMITER ',';复制
然后,我们可以将数据从该文件加载到占位符表中。
\copy tbl_placeholder FROM '/tmp/tbl_202305_dump.csv' DELIMITER ',';复制
这个加载操作应该在交换操作之前进行。为了填充缺失的数据,我们基于最后复制的行id
层叠了其他的增量插入。从占位符中的max(id)
开始,我们可以使用以下SQL复制任何丢失的新行。
INSERT INTO tbl_202305 SELECT FROM tbl WHERE id > 123; -- 在从文件加载后的max(id)复制
我们可以运行上面的语句,然后在一个事务中再次运行一次,以确保没有丢失任何行。
当占位符表存在时,ALTER TABLE
和ADD PRIMARY KEY (id, created_at)
修改可以运行。将主键约束应用于父表和所有子表,大约需要30分钟,不会阻塞任何写入。
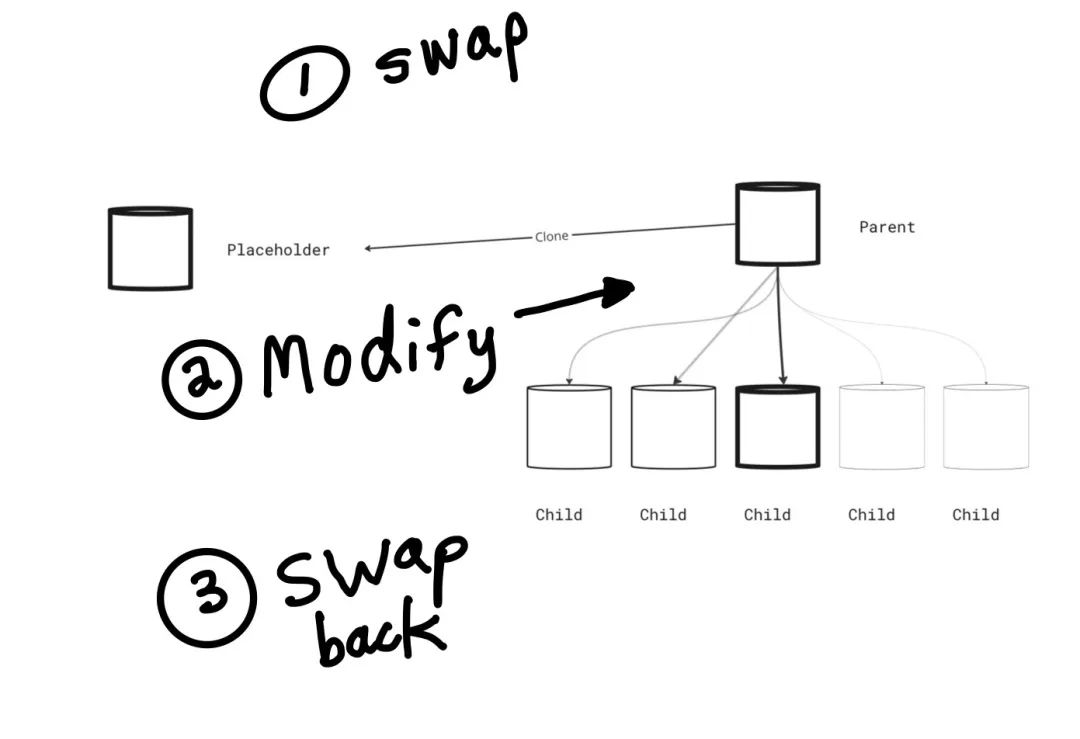
下面的图示显示了在克隆和填充表后的步骤。
步骤的顺序是第一次交换作为步骤1,对分区表的修改作为步骤2,然后第3步是第二次填充和交换。
在下一节中,我们将分享用于完成此操作的一些SQL语句。
SQL
在下面的示例中,tbl
是要修改的表的名称。它有id
和created_at
列。该表是使用INCLUDING ALL
复制的,该选项包括额外的对象,如索引,但不包括数据。
-- 创建一个空的占位符表
CREATE TABLE tbl_placeholder (LIKE tbl INCLUDING ALL);
-- 交换表
BEGIN;
ALTER TABLE tbl RENAME TO tbl_offline;
ALTER TABLE tbl_placeholder RENAME TO tbl;
COMMIT;
-- 删除所有现有的子表唯一主键约束
-- 对所有子表重复此步骤
ALTER TABLE tbl_202305 DROP CONSTRAINT tbl_202305_pkey;
-- 在表"离线"的情况下添加约束
-- 这将传播到所有子表,它们也都处于"离线"状态
ALTER TABLE tbl_offline ADD PRIMARY KEY (id, created_at);
-- 由于我们还在填充,对分区执行VACUUM
VACUUM ANALYZE tbl_202305;
-- 再次交换表
-- "离线"表已被修改,并且再次准备投入使用
BEGIN;
ALTER TABLE tbl RENAME TO tbl_placeholder;
ALTER TABLE tbl_offline RENAME TO tbl;
COMMIT;复制
总结
在本文中,我们讨论了一个我们遇到的操作问题,即我们确定需要修改大型分区表上的PRIMARY KEY
约束。
因为这会锁定和阻塞并发事务,所以我们展示了部分如何使用在线/零停机策略来解决这个问题。尽管该策略风险较大,需要仔细的规划和执行,但可以避免干扰其他任何事务。
虽然不建议经常使用这种技术,但它在紧急情况下非常有用,可以解决由DDL修改引起的常规操作表锁定,否则可能导致数据丢失和错误。
通过事先编写和排练这些步骤,团队合作并共同解决问题,工程团队能够在线完成此操作而无错误。
主键修改完成后,数据仓库中的过多查询停止了。数据仓库可以再次有效地确定新的和修改的行。
感谢阅读本文!
感谢Sriram Rathinavelu和Alesandro Norton为本项目的贡献以及对本文早期版本的审阅。


