




8月16-18日,第十四届中国数据库技术大会(DTCC 2023)在北京召开。酷克数据资深解决方案架构师陈义贤在“数据库内核•技术创新”专场发表题为“分布式数仓的TP能力探索—HashData UnionStore”的演讲,介绍HashData以Log is database的思路在分布式数据仓库提升TP性能改造中的技术方案及未来发展规划。
本文根据现场演讲内容整理而成,相关PPT材料欢迎扫描文章底部二维码添加企微小助手获取。
演讲精彩观点:
01
在数据业务化的背景下,企业对数仓实时性能力提出越来越高的要求,OLAP和OLTP会发生进一步的融合。
02
存算分离架构将成为未来数据架构的基本要求,云原生架构的核心理念是将存算分离,使用对象存储来保存一份全域数据,所有计算集群均为无状态,按需申请使用,也可以兼容各种不同计算引擎,满足各类不同业务的需求。
03
存算解耦后,使用不同引擎分开处理数据成为可能:Log is database的理念可以大幅优化数仓的OLTP能力,通过将数据随机写入的操作剥离,以日志数据为中介载体,减少了复杂的锁定和同步操作,大幅提升了并发能力,同时减少随机访问带来的成本。
以下为本次演讲文字实录(节选):
在1.0阶段,以数据统计查询为主,在此基础上构建相应的系统,服务于部门级的应用。
在2.0阶段,企业通过数仓整合远端应用数据,再进一步的进行加工,实现商业智能,为企业决策层提供支撑。
随着大数据技术的发展,企业数据应用已经进入3.0阶段。在这一阶段,数据应用越来越丰富,能够更好地服务于企业全体员工。
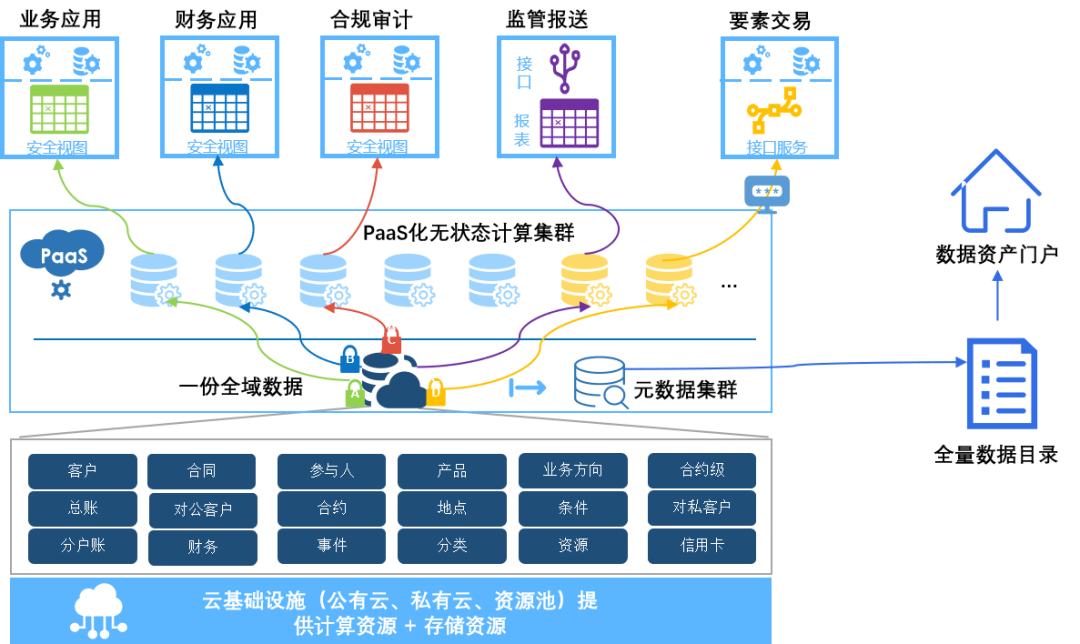
Log is database通过将数据随机写入的操作剥离,计算集群只将WAL日志提交至HashData UnionStore集群,由UnionStore集群处理日志数据,并重放生成新的页数据,这样减少了复杂的锁定和同步操作,可以大幅提升并发能力,同时也减少随机访问。
Log is database提升数仓TP性能体现在以下几个方面:
减少磁盘随机访问:传统的数据库系统需要将数据写入磁盘的数据文件中,这可能导致频繁的磁盘随机访问,对性能造成负面影响。而日志数据库将所有的数据更改操作都追加到日志中,这样可以将磁盘写入操作转变为连续的顺序写入操作,大大减少了磁盘的随机访问,提高了性能。
异步提交:传统的数据库系统在每个事务提交时都需要将数据写入磁盘,这会引入较高的延迟。而日志数据库采用异步提交的方式,即先将数据更改操作写入日志,然后异步地将日志中的操作批量写入磁盘。这种方式可以减少磁盘写入的次数和延迟,进一步提升性能。
并发控制优化:日志数据库可以利用日志记录事务操作的特性来进行并发控制的优化。多个事务可以并发地写入日志,而不需要进行复杂的锁定和同步操作。这种并发控制的优化可以提高系统的并发性能和吞吐量。
批处理优化:日志数据库通常将多个操作合并成批处理操作进行处理。通过批处理操作,可以减少磁盘写入的次数,进一步提高性能。例如,将多个更新操作合并成一个批处理操作,可以减少每个操作的开销和磁盘访问次数。
重放优化:日志数据库可以通过重放日志来恢复和重建数据库状态。在系统启动时,可以通过重放日志中的操作,按照顺序将数据更改应用到数据库中,从而快速恢复数据库的一致状态,而无需执行大量的随机访问和数据恢复操作。
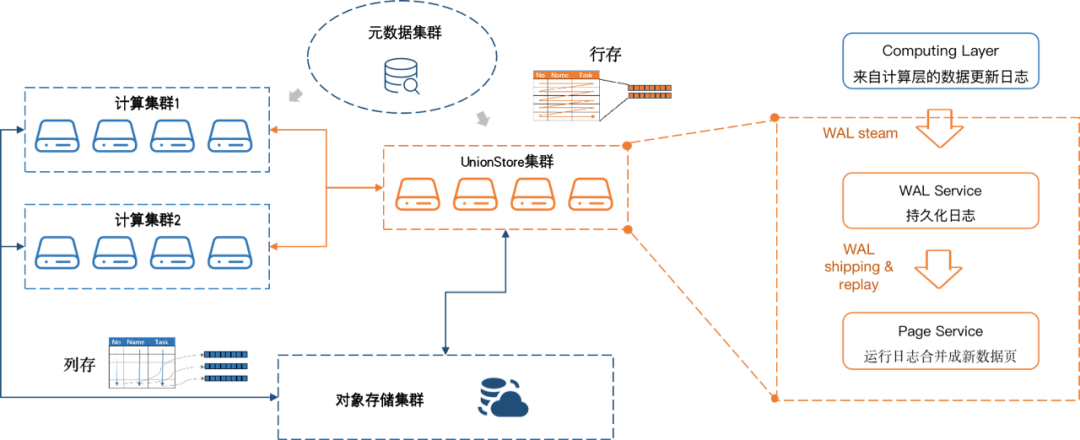
图2:HashData UnionStore架构图
Wal Service:在数据库中,WAL是一种持久性存储技术,它可以确保数据库在重启或崩溃时不会丢失数据。在WAL机制下,数据库在写入数据之前,会首先写入一份日志记录,用于记录写入的数据信息。为了保证日志持久化之后的可靠性,日志通常会保存三副本。由leader节点负责接收计算集群请求,本地持久化同时将日志发送到follower节点,当所有节点都完成日志持久化之后,leader节点才会返回给计算集群。

图3:Time Travel示例图
Time Travel可广泛应用于以下场景,为数据库的操作管理提供极大的便利:
恢复数据库对象:通过追溯Page版本和LSN,可以将数据恢复到任意时间点。误删除的表,Shcema和库,可以直接将数据恢复到误操作之前时间点。 查询历史数据:可以查询任意时间点的数据,简单快速。获取数据在某个时间段的变更历史、增量统计用于决策分析;例如通过CDC数据入库,可以在不制作拉链表的情况下,直接选择统计数据的时间点。
历史数据克隆:创建任意时间点数据的拷贝,辅助数据模型训练。基于某个时间点训练结果创建多份数据拷贝,使用不同参数进行训练,对比训练结果。
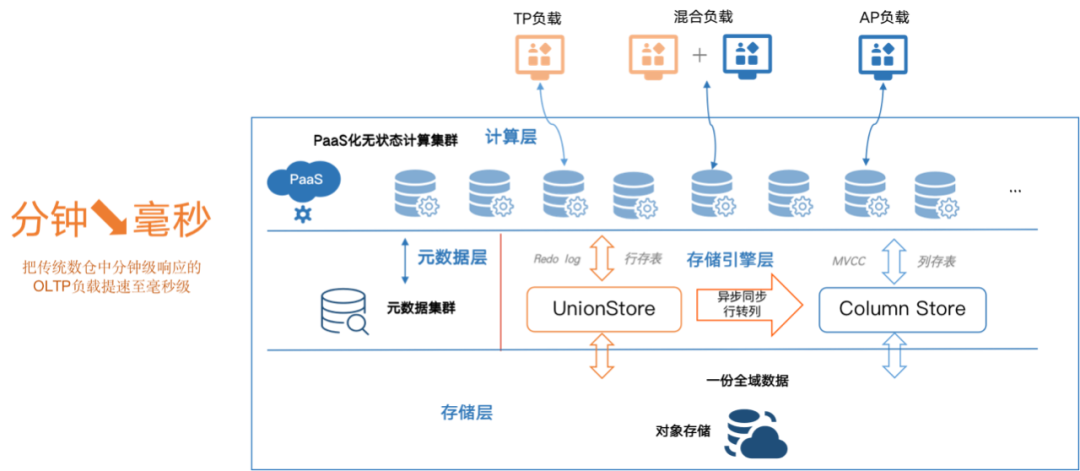
图4:HashData云原生统一架构HTAP数据平台
欢迎大家扫描下方二维码,添加企微小助手联系我们,获取HashData产品与活动的最新资讯!


