




GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
inception模块的基本机构如图所示,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
1、引入Inception结构
引入的Inception融合了不同尺度的特征信息,能得到更好的特征表征。
更意味着提高准确率,不一定需要堆叠更深的层或者增加神经元个数等,可以转向研究更稀疏但是更精密的结构同样可以达到很好的效果。
2、使用1x1的卷积核进行降维映射处理
降低了维度也减少了参数量(NiN是用于代替全连接层)。
3、添加两个辅助分类器帮助训练
避免梯度消失,用于向前传导梯度,也有一定的正则化效果,防止过拟合。
4、使用全局平均池化
用全局平均池化代替全连接层大大减少了参数量(与NiN一致)
5、1*n和n*1卷积核并联代替n*n卷积核
在InceptionV3中,在不改变感受野同时减少参数的情况下,采用1*n和n*1的卷积核并联来代替InceptionV1-V2中n*n的卷积核(发掘特征图的高的特征,以及特征图的宽的特征)
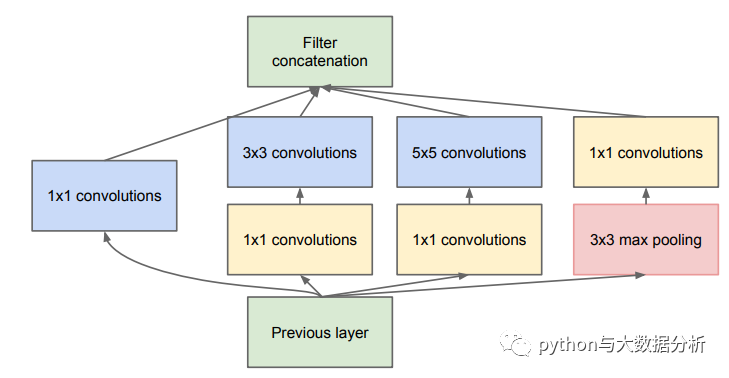
具体代码如下,因为里面的层数太多,所以在此就不做推算了:
classGoogLeNet(nn.Module):
def __init__(self, num_classes=10, aux_logits=False):
super().__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=3, padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = AuxClassifier(512, num_classes)
self.aux2 = AuxClassifier(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
nn.init.kaiming_uniform_(m.weight, mode='fan_out', nonlinearity='relu')
def forward(self, X):
X = self.conv1(X)
X = self.conv2(X)
X = self.inception3a(X)
X = self.inception3b(X)
X = self.maxpool3(X)
X = self.inception4a(X)
if self.training and self.aux_logits:
aux1 = self.aux1(X)
X = self.inception4b(X)
X = self.inception4c(X)
X = self.inception4d(X)
if self.training and self.aux_logits:
aux2 = self.aux2(X)
X = self.inception4e(X)
X = self.maxpool4(X)
X = self.inception5a(X)
X = self.inception5b(X)
X = self.avgpool(X)
X = torch.flatten(X, start_dim=1)
X = self.dropout(X)
X = self.fc(X)
if self.training and self.aux_logits:
return X, aux2, aux1
return X
classInception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super().__init__()
print('Inception params:',in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj)
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
print('branch1 params:', in_channels, ch1x1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
print('branch2 params:', in_channels, ch3x3red,ch3x3)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
print('branch3 params:', in_channels, ch5x5red,ch5x5)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
print('branch4 params:', in_channels, pool_proj)
def forward(self, X):
branch1 = self.branch1(X)
branch2 = self.branch2(X)
branch3 = self.branch3(X)
branch4 = self.branch4(X)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
classAuxClassifier(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, X):
X = self.averagePool(X)
X = self.conv(X)
X = torch.flatten(X, start_dim=1)
X = F.relu(self.fc1(X), inplace=True)
X = F.dropout(X, 0.7, training=self.training)
X = self.fc2(X)
return X
classBasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
print('BasicConv2d params:',in_channels, out_channels)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
return self.relu(self.bn(self.conv(X)))
下图是打印出来的执行顺序,便于消化理解GoogLeNet网络。
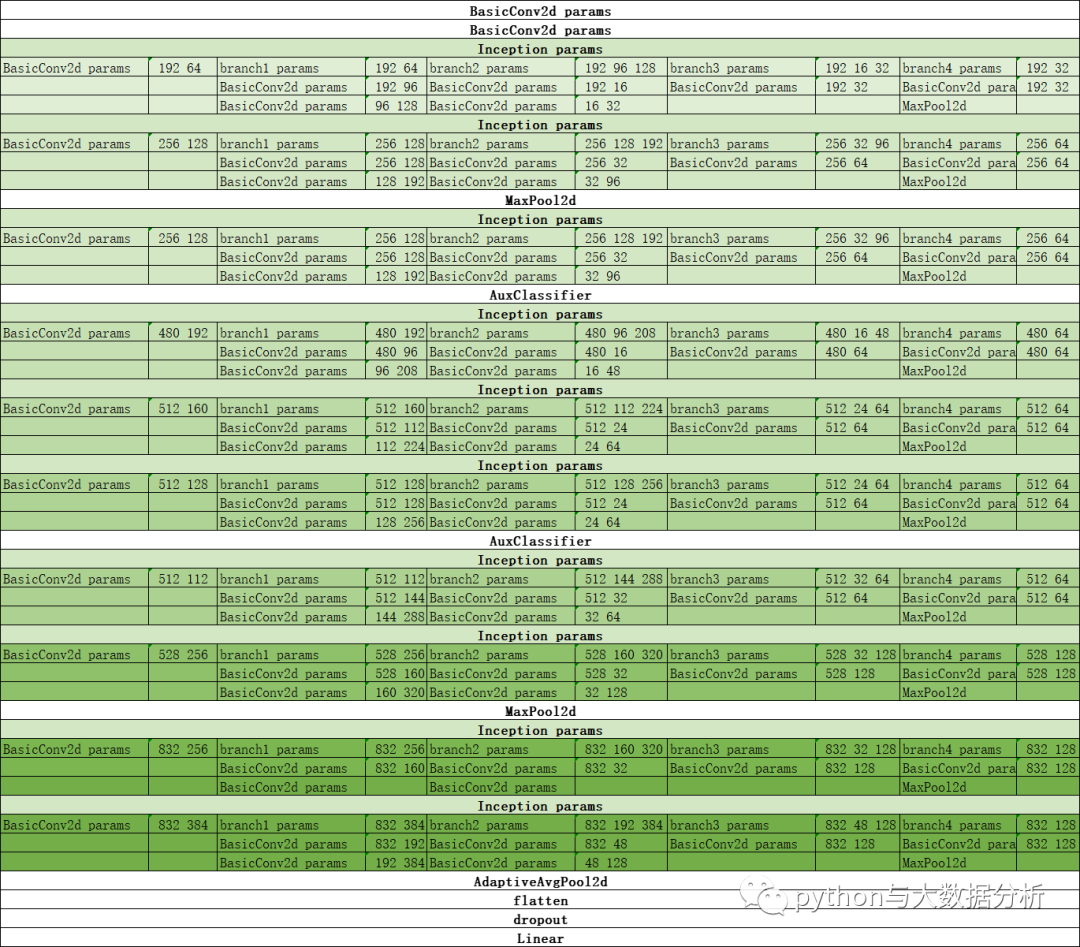
下面是运行的情况以及训练集和验证集的准确率,GoogLeNet较之前VGG-16网络运行时间大大增加,而且在CPU笔记本上基本无法运行了,此外准确率较VGG-16并没有看出提升,训练了100轮准确率也只有79%,还比不上之前VGG-16网络。
start_time 2023-08-1817:12:02
TrainEpoch1Loss: 12.900574, accuracy: 9.375000%
test_avarage_loss: 0.043172, accuracy: 46.720000%
end_time: 2023-08-1817:15:01
...
start_time 2023-08-1818:08:22
TrainEpoch20Loss: 0.188147, accuracy: 95.312500%
test_avarage_loss: 0.016367, accuracy: 75.200000%
end_time: 2023-08-1818:11:19
...
start_time 2023-08-1822:04:30
TrainEpoch100Loss: 0.007709, accuracy: 100.000000%
test_avarage_loss: 0.023382, accuracy: 79.360000%
end_time: 2023-08-1822:07:27
下面是代码里输出的损失率和准确率
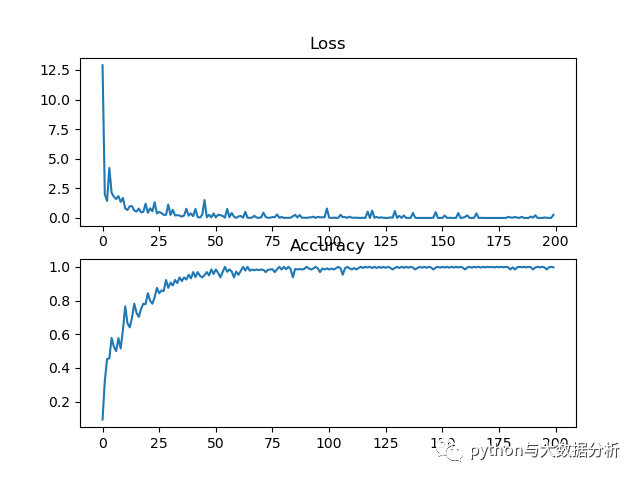
这是基于深度学习开展图像识别的第四个模型,估计是一些参数未做调优导致的,接下来会尝试一下ResNet网络。
最后欢迎关注公众号:python与大数据分析

