




嘻嘻! 标题蛋而已,目前国产数据库都是基于MYSQL和PG开源数据库修改和包装而来的. DM是自研数据库. 对其不知一和二!
从MYSQL DDL 修改表结构,会有两种算法,快的和慢的. 不管那一种,都要加MDL锁! 表结构修改锁. 而且这锁很阻塞,只要前面的SELECT和DML稍微慢一点,MDL锁就要等待前面的SQL执行完才能加上.
关键是你等你的啊! 它还会把它后面的所有涉及该表的SQL都阻塞.
哦!这事就大了,搞得整个系统都变慢了!
是啊 国内开发天天上线,天天加表,天天添加字段.
虽然MYSQL 有INPLACE,非常快! 那怕是数据重组COPY算法,也有DDL LOG缓存. 基本上无害! 可是有人问你,这个DDL会采用什么算法? 你的跑区官网查表,表如下:
操作 | IN PLACE | Rebuilds Table | Permits Concurrent DML | Only Modifies Metadata | NOTES |
| Adding a column | Yes | Yes | Yes* | No | |
Dropping a column | Yes | Yes | Yes | No | |
| Modifying column Order (AFTER,FIRST) | Yes | Yes | Yes | No | |
| Renaming a column | Yes | No | Yes* | Yes | |
| Reordering columns | Yes | Yes | Yes | No | |
| Setting a column default value | Yes | No | Yes | Yes | |
| Changing the column data type | No | Yes | No | No | |
| Extending VARCHAR column size | Yes | No | Yes | Yes | |
| Dropping the column default value | Yes | No | Yes | Yes | |
| Changing the auto-increment value | Yes | No | Yes | No* | |
| Making a column NULL | Yes | Yes* | Yes | No | |
| Making a column NOT NULL | Yes* | Yes* | Yes | No | |
| Modifying the definition of an ENUM or SET column | Yes | No | Yes | Yes | |
Adding a primary key | Yes* | Yes* | Yes | No | |
| Dropping a primary key | No | Yes | No | No | |
| Dropping a primary key and adding another | Yes | Yes | Yes | No | |
Creating or adding a secondary index | Yes | No | Yes | No | |
| Dropping an index | Yes | No | Yes | Yes | |
| Renaming an index | Yes | No | Yes | Yes | |
| Adding a FULLTEXT index | Yes* | No* | No | No | |
| Adding a SPATIAL index | Yes | No | No | No | |
| Changing the index type | Yes | No | Yes | Yes | |
Adding a STORED column | No | Yes | No | No | |
| Modifying STORED column order | No | Yes | No | No | |
| Dropping a STORED column | Yes | Yes | Yes | No | |
| Adding a VIRTUAL column | Yes | No | Yes | Yes | |
| Modifying VIRTUAL column order | No | Yes | No | No | |
| Dropping a VIRTUAL column | Yes | No | Yes | Yes | |
Adding a foreign key constraint | Yes* | No | Yes | Yes | |
| Dropping a foreign key constraint | Yes | No | Yes | Yes | |
Changing the ROW_FORMAT | Yes | Yes | Yes | No | |
| Changing the KEY_BLOCK_SIZE | Yes | Yes | Yes | No | |
| Setting persistent table statistics | Yes | No | Yes | Yes | |
| Specifying a character set | Yes | Yes* | Yes | No | |
| Converting a character set | No | Yes* | No | No | |
| Optimizing a table | Yes* | Yes | Yes | No | |
| Rebuilding with the FORCE option | Yes* | Yes | Yes | No | |
| Performing a null rebuild | Yes* | Yes | Yes | No | |
| Renaming a table | Yes | No | Yes | Yes |
这么多操作 万一遇到了数据重组COPY算法,上个线就要上个把小时.自己苦等COPY完成.要么上线晚上,要么上线白天,晚上DBA要熬夜,白天上线太慢,马上业务量就来了.前后都不是人,被开发牵着鼻子走.
那怕ORACLE 建个索引也需要追加关键字 ONLINE ; DDL 如果有默认值会影响旧数据. 说明ORACLE 这方面也做得不完美,也是打补丁方式.
假设我们开发国产数据库,关于修改表结构 DDL操作,是不是可以优化点.方便些,不要阻塞这阻塞那的.
元数据表
设计表的元数据表, 我们把每个表的元数据做成一张表.有如下字段
1 ID
2 COLUMN_ID
3 COLUMN_NAME
4 TYPE
5 LENGTH
6 PERCISION
7 CHARSET
8 IS_KEY
9 IS_NULL
10 DEFAULT
11 BYTES
12 CREATE_TIME
13 VERSION
大约像下面这图
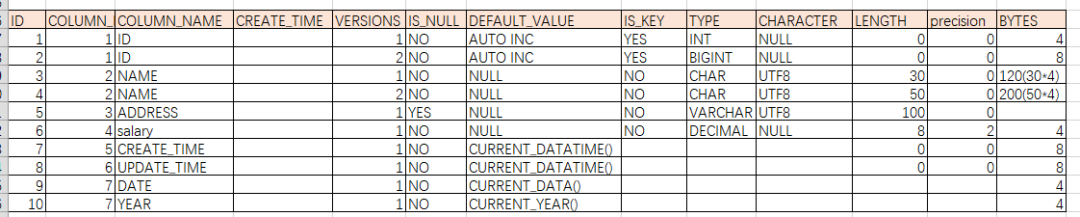
我们对元数据只添加,不修改,且不影响旧数据!
那么这点来说 修改表结构,不要等前面的SQL执行完,同时也不会阻塞后面的SQL. 多美化啊
我们根据多版本, MVCC思想处理元数据和行数据匹配问题.
比如说 我们插入一条数据, 我们应该从 元数据表获得最新的列信息,且把ID植入行里面
那查询的时候,根据行里的ID列表,定位到元数据的相应列.
UPDATE 的时候 也按照查询思路,获得元数据表列信息.根据列信息去更新.唯一的是可能被更新的列长度容不下要更新的内容.也就是说符合条件的行,有些能更新,有些不能更新. 因为它们的列信息不一样.
行信息
一般情况下 行都有这几列信息
1 ROW_ID 这个是定位信息通常是什么表空间,文件,段,EXTEND,页组成
2 CLO_NUM 本行列的个数
3 CLO_ID_LIST, 对应元数据表的ID 值列表 通过它获得匹配的列信息
4 COMMIT_TIME 最后提交时间,对应MVCC功能
5 NULL_FLAG 空值标签位 表示哪些列是存了空值
6 DEL_FLAG 删除标志
7 LOCK 锁标志:
8 UNDO_ROWID: 回滚行位置
9 VALUES: 存放各个列的具体值
19 EXTEN_ROWID: 扩展页里对应的ROWID, 当一行不够存时,放在别的页
20 EXTEN_DEPTH: 扩展深度
随着时间推移,表结构修改来修改去,元数据就非常多的列信息,很多列都已经无用了,当然我们也不能无限制让元数据增长下去.为此规定ID最大是1000.列最大是255.扩展深度100; 这样达到上限,就需要DBA找个合适时间进行表重组.
表重组 从元数据获得最新版本的列信息,COPY到新的元数据表.然后做数据重组. 数据重组阻塞 SELECT,UPDATE,DDL; 不阻塞DELETE,INSERT.
数据重组
上面提到是整个表级别重组.另外有很多级别的重组,有页级别,有行级别.
1 扩展页重组
当我们对旧数据进行更新的时候,原本是NULL现在添加新VALUE进去,
比如说地址VARCHAR(200) DEFAULT NULL;
现在UPDATE TABLE SET ADDRESS='XXXX' WHERE ADDRESS IS NULL;
这样的话,有些行所在的页(块)已经满,放不下了,那只要放在别的页里面,
扩展页的行 ROWID,DEL,列ID LIST, 列长度列表, VALUES, 扩展ROWID;
不断地扩展,形成扩展页链表. 这样读取该行,就要读取N多个页.
那么申请新的数据页,把这行数据全部放入新页里,对旧页的数据打个删除标志,把新页的UNDO 指向旧页.
ALTER TABLE EXTEND PAGE REBUILD;
2 行新版本重组
行依据元数据表新的列信息 进行数据重组; 扫描表不符合最新版本的列信息的行找出来,按照新的元数据信息进行重组.
行新版本重组 先激发行扩展页重组; 行新版本重组,也是复制到新的数据页里,旧行打上删除标志,UNDO 关联上.
ALTER TABLE COLUM REBUILD;
3 页重组
ALTER TABLE PAGE REBUILD;
当个数据页 被删除的行达到一个水平后,就可以放弃该页,把该页的行数据COPY到新的数据页里面.
4 表元数据重组
ALTER TABLE MDL REBUILD;
最后 需要监控和统计方式
需要知道该表有多少个数据页, 多少个扩展页,扩展深度,多少个有删除标志的页; 重组需要的空间,重组需要的时间.
记录该表的操作低峰时间段, 定义个JOB任务 在低峰时间段进行重组;
定义内存空间,磁盘空间,运行时间限制. 在规定时间和资源下,做能做的重组,从最少开始 比如1 行扩展页重组. 可以完成部分数据重组工作. 也就是说重组JOB任务达到了时间限制,是可以暂停的. 等待下个低峰期再继续重组,类似断点续传.
这样就自动化,智能化, AIOPS化! DBA就进行审核操作和事后检查成果.
扩展阅读:
用SHELL输出HTML的MYSQL巡检
MYSQL AWR 报表
MYSQL 安全更新测试
MYSQL 产生大量数据的过程
MYSQL LEFT JOIN 优化
MYSQL 加字段优化
MYSQL 字符集优化
MYSQL ID 的混乱星海
MYSQL8.0索引算法问题
MYSQL排序ORDER BY
