每秒服务超过100万次操作,平均延迟为几毫秒,同时读取/写入实时用户级数据,这些数据可能会增长到数十亿行,这不是一项微不足道的任务。它需要严肃的基础设施,通常有一个昂贵的价格标签,需要一个专家团队来操作。如果我告诉你,你只需要一个Kubernetes集群和一个开源数据库,就可以实现零停机故障转移、个位数毫秒级响应时间、垂直和水平扩展、每个CPU核心的数据分片、完全分布式的读/写操作等等,你会怎么做?在这篇文章中,我将分享如何使用ScyllaDB代替MongoDB作为主要的生产实时数据库。ScyllaDB是一个开源的NoSQL数据库,它与Apache Cassandra(以及DynamoDB)的api兼容。它拥有环状体系结构无主数据库的所有优点,同时避免了Cassandra臭名昭著的所有问题,包括Java虚拟机问题,如停止世界垃圾收集、大量内存占用、启动缓慢、即时预热和复杂的配置。ScyllaDB带有生产就绪的Helm图表,Kubernetes操作符和即插即用配置。它是开源的,它可以完美地运行在现场(不稳定的)实例上,而成本只有常规云计算价格的1/4。ScyllaDB vs. MongoDB
为什么ScyllaDB能取代MongoDB?MongoDB有什么问题呢?首先ScyllaDB是开源的,支持数据分片。但是MongoDB的架构是完全不同的。它有一个单点故障:如果协调器出现故障,数据库将启动故障转移,并且在此期间数据库不可用。此外,实现高可用性需要每个MongoDB shard作为副本集(更多节点)运行。Cassandra和ScyllaDB共享的环形架构在这方面更胜一筹。此外,ScyllaDB的驱动程序是分片感知的,知道到达负责查询行的精确节点/CPU,这允许真正的分发。但是,为什么高可用性和零停机故障转移如此重要?如果您计划在现场实例(计算价格的1/4)上运行,您将经历频繁(每天)的故障转移,因为Kubernetes将不断地杀死和重新创建节点,这将导致在它们上运行的所有pod 进程死亡,包括您的数据库。在Kubernetes上启动和运行
首先,需要在本地运行ScyllaDB。使用它的驱动程序并按照文档中的描述运行一些CQL (Cassandra Query Language)。可以使用gocql驱动程序。重要的是,ScyllaDB驱动程序是感知分片的,你需要连接到感知分片的ScyllaDB端口19042(而不是9042上的默认Cassandra端口)。ScyllaDB Kubernetes Operator包含三个Helm图表:scylla:数据库本身。它包含ScyllaCluster CRD (Kubernetes自定义资源定义),这是一个配置ScyllaCluster集群、其大小、资源、文件系统等的YAML。scylla操作符:安装一个Kubernetes控制器,它将获取这个YAML并从中创建一个StatefulSet、服务和其他Kubernetes实体。scylla管理器:基本上是一个使任务自动化的单例服务。它连接到所有ScyllaDB节点,可以运行集群范围的任务,如修复或云存储备份。可以使用Argo CD来安装和配置上面提到的图表。它允许GitOps机制回滚,并为Kubernetes中发生的事情提供可见性。(Argo CD超出了本文的范围,但基本上,我将单击几个UI按钮并将几个yaml推入git repo,而不是运行Helm安装命令)。
配置集群
操作符图的配置非常简单。您唯一需要定义的是Kubernetes nodeSelector和taint tolerations(如果需要的话)。定义操作符可以在哪些k8s节点上运行,然后即插即用。现在,我们来看一下ScyllaDB管理器。让我们看一下Chart.yaml:apiVersion: v2
name: scylla-manager
description: Scylla Manager automates database operations.
version: 0.0.0 # overwritten during publishing
appVersion: "1.7" # overwritten during publishing
dependencies:
- name: scylla
version: 1.0.0
repository: file://../scylla
dependencies指令声明scylla-manager导入scylla图表,因此当您安装它时,您将同时安装它们。管理器配置(values.yaml)有一个ScyllaDB部分,所有操作都发生在这里。# scylla-manager values.yaml
# ...
scylla:
cpuset: false
automaticOrphanedNodeCleanup: true
repairs:
- name: "weekly manager-rack repair"
intensity: "2"
interval: "7d"
dc: [ "manager-dc" ]
serviceMonitor:
promRelease: staging-prometheus-operator
create: true
developerMode: true
scyllaImage:
tag: 5.2.0
agentImage:
tag: 3.0.0
datacenter: manager-dc
racks:
- name: staging
placement:
tolerations:
- key: "infra"
operator: "Exists"
effect: "NoSchedule"
members: 3
storage:
capacity: 6Gi
storageClassName: xfs-class
resources:
limits:
cpu: 1
memory: 1000Mi
requests:
cpu: 250m
memory: 200Mi
上述配置的关键点是,ScyllaDB建议使用该配置,可以提供更好的性能。该图表不包含存储类定义,但你可以自己添加:xfs storageClassName。apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: xfs-class
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-ssd
csi.storage.k8s.io/fstype: xfs
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
有个重点。它将允许您稍后在数据库运行时无缝地增加persistentvolumecclaim (PVC)磁盘大小。在Argo CD安装了这两个图表之后,结果如下:allowVolumeExpansion。
ScyllaDB操作器
ScyllaDB操作器已启动并运行。这里需要注意的是,操作符本身是高度可用的,并且有两个自己的副本。现在,它将基于它的CRD创建ScyllaDB集群。
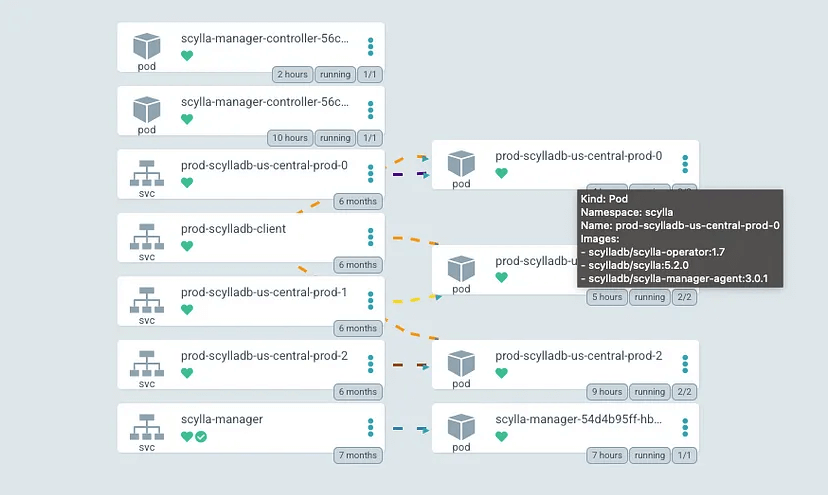
ScyllaDB集群
在我们的示例中,操作符创建了一个包含三个节点的集群。每个pod都运行数据库本身、ScyllaDB Manager和操作程序客户端。这有助于取代“专家团队”,并自动化管理和操作任务。监控
没有适当的监视和警报,任何生产数据库都不可能存在。ScyllaDB Operator通过Prometheus服务监视器配置实现了这一点。scylla:
...
serviceMonitor:
promRelease: staging-prometheus-operator
create: true
ServiceMonitor
这将导致Prometheus定期抓取数据库指标,将它们存储在时间序列数据库中,并允许运行promQL查询来定义Grafana仪表板和警报。Grafana仪表板
Grafana仪表板
Grafana JSON仪表板可以在这里找到。下面是如何将它们添加到ScyllaDB提供的Helm图表中。为此,我们需要创建Kubernetes ConfigMaps并将它们标记为Grafana仪表板。幸运的是,Helm可以帮我们。{{- range $path, $_ := .Files.Glob "dashboards/scylla/*.json" }}
{{- $filename := trimSuffix (ext $path) (base $path) }}
apiVersion: v1
kind: ConfigMap
metadata:
name: scylla-dashboard-{{ $filename }}
namespace: monitoring
labels:
grafana_dashboard: "1"
app.kubernetes.io/managed-by: {{ $.Release.Name }}
app.kubernetes.io/instance: {{ $.Release.Name }}
data:
{{ base $path }}: |-
{{ $.Files.Get $path | indent 4 }}
---
{{- end }}
上面的代码片段将导致五个配置映射被添加到Kubernetes中,并标记为(这将导致Grafana挂载它们)。grafana_dashboard:“1”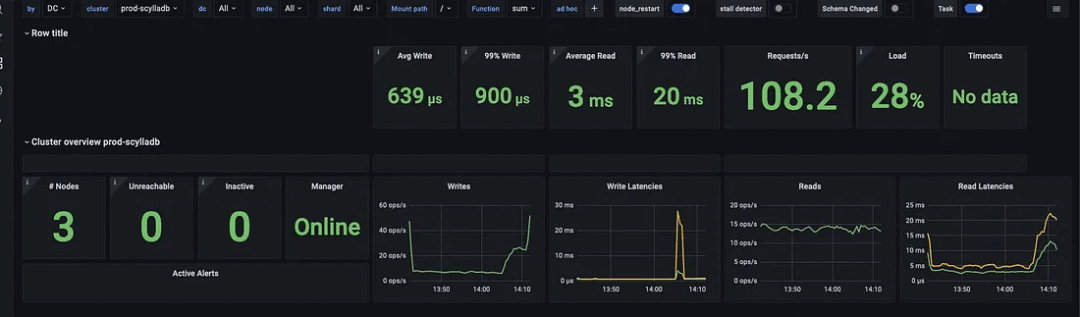
ScyllaDB概述仪表板视图1
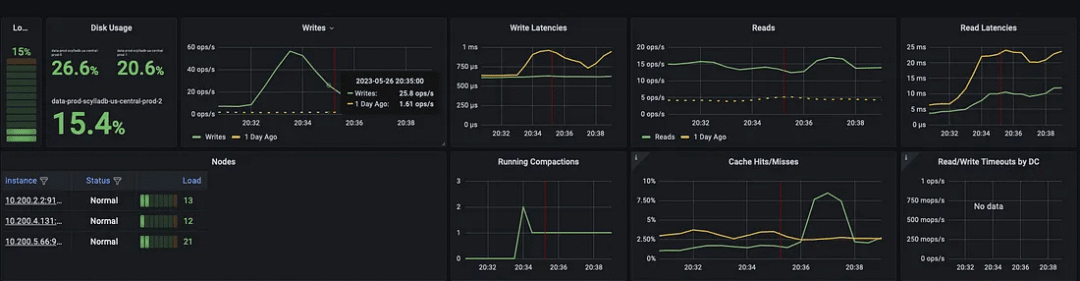
ScyllaDB概述仪表板视图2
导出了许多带有细微指标的图,这允许对数据库经历的所有事情进行细粒度监视。下面的图表非常重要;它描述了过去24小时内的所有故障转移。
24小时内13次故障转移
每次Kubernetes杀死一个随机的点实例时,它就会调度一个新的ScyllaDB pod,它会在几分钟内重新加入集群,不会有任何停机时间。我们已经运行ScyllaDB快一年了,它工作得很好。这里有一个有用的技巧,即始终将节点池超额供应一个节点。这很可能确保至少有一个可用节点可以使用新的数据库pod进行调度。它增加了一点价格,但它仍然比使用常规节点更具成本效益。上图显示,每次ScyllaDB实例被终止时,都会出现一个短暂的CPU峰值,延迟会增加几毫秒,并且由于ScyllaDB在RAM中构建的所有缓存消失,RAM会减少。这是使用现货实例的一个明显缺点。然而,在我们的用例中,值得用短暂的、非常小的延迟峰值来换取巨大的计算价格折扣。结论
总之,ScyllaDB证明是一个出色的开源数据库,它不负其承诺。ScyllaDB作为开放源代码免费提供的事实确实令人瞩目。






