





点击上方蓝字关注我们
作者简介
author
张亚飞,来自于中原银行数据银行部数据平台中心,从事大数据平台开发,擅长大数据组件的功能、工具开发与性能优化
1、为什么使用ES
ES(Elasticsearch)作为一个开源的高扩展的分布式全文检索引擎,自2016年起已经超过Solr,成为排名第一的搜索引擎应用,具有很多独特的优点。
它可以为几乎所有类型的数据提供近实时的索引、搜索和分析服务。无论是结构化或非结构化数据文本、数值数据、还是地理空间数据,ES都支持高效地存储和索引,并快速的提供搜索。
它本身扩展性很好。可以扩展到上百台服务器,处理PB级别的数据,由于索引具有副本机制,所以它也具有高可用优点。
它的使用简单。通过简单的RESTful API隐藏了Lucene的复杂性,从而让全文搜索变得简单易用。
2、什么是自定义分词
在说ES自定义分词之前,首先要弄清楚ES的倒排索引和分词原理。

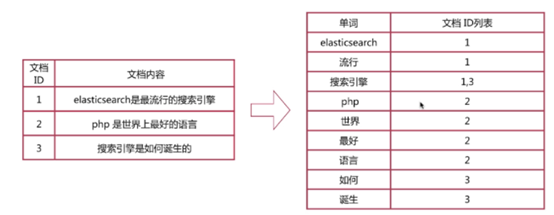
倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,都会有一个包含它的文档列表。
2.2 分词
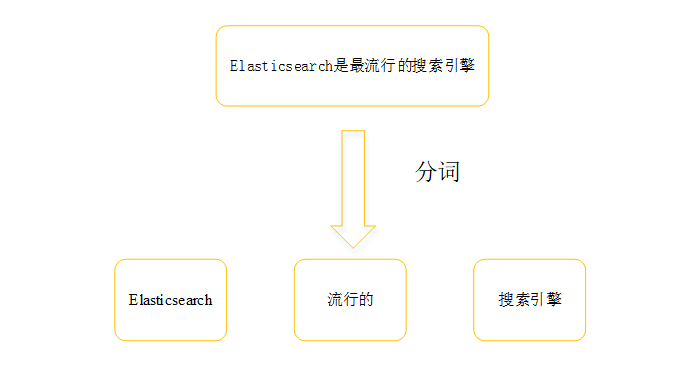
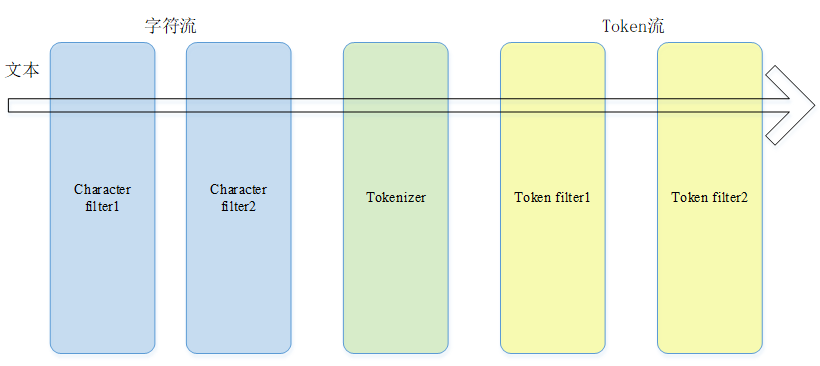
1.字符过滤器(Character Filters)
字符过滤器以字符流的形式接收原始⽂本,并可以通过添加、删除或更改字符来转换,比如去除html特殊标记符。⼀个Analyzer可能有0个或多个字符过滤器。
2.分词器(Tokenizer)
对原始文本按照一定规则进行切词。⽐如使⽤whitespace分词器,当遇到空格的时候会将⽂本拆分成token。“eating an apple” >> [eating, an, apple]。⼀个分析器有且仅有⼀个分词器。
3.Token过滤器(Token Filters)
针对分词之后的token进行再次过滤,可以增加、删除和更改Token,比如把所有的token进行转小写操作,一个分词器有可以有0个或多个token过滤器。
ES中有很多预定义的分词器,具体的名称和分词策略如下表:
分词器 | 分词策略 |
Standard Analyzer | 默认分词器,按词切分,支持多语言小写处理。 |
Simple Analyzer | 按照非字母切分,小写处理。 |
Whitespace Analyzer | 空白字符作为分隔符 |
Stop Analyzer | 相比Simple Analyzer,去除停用词处理,停用词指语气助词等修饰性词语,如the, an, 的,这等 |
Keyword Analyzer | 不分词,直接将输入作为一个单词输出 |
Pattern Analyzer | 通过正则表达式自定义分隔符,默认是\W+,即非字词的符号作为分隔符 |
除了预定义的分词器,ES还提供了很多分词器插件,其中IK分词器是处理中文最常见、最普遍的分词器插件,它根据本地自己维护的词典进行分词,支持两种算法:
ik_smart:将一个中文字符进行最少次数的切分。
ik_max_word:将一个中文字符进行最细粒度的切分。
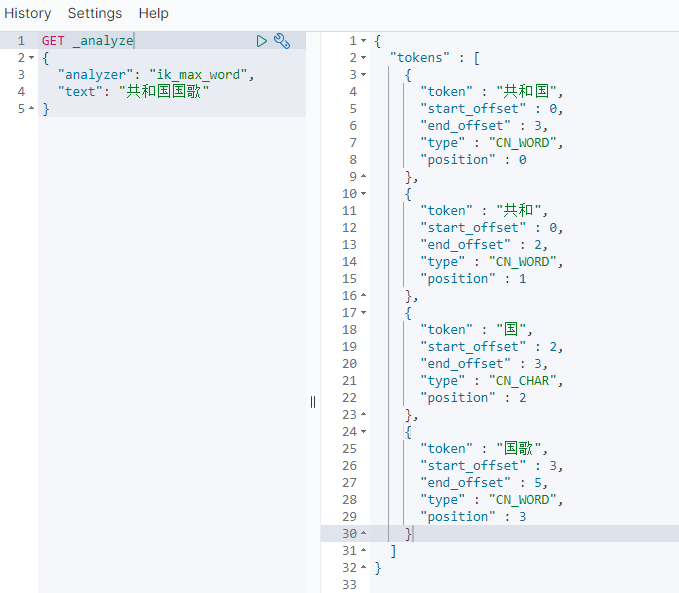
比如我们把“共和国国歌”索引到ES集群,使用IK分词器的ik_smart算法进行切分,结果如下:

使用IK细粒度分词策略(ik_max_word)切分结果如下:
2.3 自定义分词
ES支持很多类型的分词器,但分词的策略都是插件自定义好的,如果我们要让IK分词器按照我们自己自定义的词典规则进行切分,且随时生效,不用重启集群,这就成为自定义分词。ES根据我们自定义的词典进行切分单词并按照倒排索引方式存储,这样可以更加方便,更加快捷,更加准确的查询到我们想要的数据。
3、自定义分词解决了什么问题
ES的使用主要应用于查询,查询的快捷和准确是ES的优点之一。但有些项目组由于数据特殊,他们的数据在使用ES的IK进行分词之后,发现数据的查询变得不准确,且查询性能较低。经过分析可知:
1)模糊查询性能较低。ES可以使用match对数据进行模糊匹配,它的查询原理同样基于倒排索引,比如项目组的数据有大量的以“共和国”开头的数据,由于IK分词器默认会把数据分成“共和国”和其它,所以在匹配“共和国国歌”的过程中,它会匹配出大量的以“共和国”开头的词组,由于数据量较大,会使查询的速度低下,查询的准确度也变得更低。
2)精确查询匹配不到数据。ES可以像关系型数据库一样,可以使用精确查询,同样以“共和国国歌”为例,当使用IK进行分词之后,数据会被分成“共和国”、“国歌”,就会出现查询不到的情况。
我们通过自定义分词词典功能的开发,可以很好的解决以上问题,可以使得查询更加快捷和准确。另外,使用IK分词器进行分词时,可以修改它默认的分词规则,但由于每个节点都有独立的IK分词器,需要修改所有的分词策略,同时需要重启集群才能生效,通过自定义分词服务开发,可以做到不重启集群,随时生效。
4、自定义分词服务开发
4.1 ES远程仓库配置
IK分词器远程仓库首次使用需要进行配置,需要在IK插件中配置远程仓库的地址:
<!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">location</entry>复制
其中 location 是指一个 url,
比如http://yoursite.com/getCustomDict,首次配置完成之后需要重启所有实例才能生效。
Http Server的开发需要满足以下两点:
1.该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
2.该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足以上两个条件之后,可以把更新的词典放到一个UTF-8编码的.dic文件中,当该文件中的内容发生变化时,Http Server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag,ES集群每隔60s请求一次server获取该文件,第一次请求该文件时,ES会把返回的Last-Modified 和 ETag放在本地,等到再次请求时,一旦发现Last-Modified 和 ETag中任一个发生变化,ES就会把dic文件下载到集群中,重新加载词典,如果Last-Modified 和 ETag都没有发生变化,便不会重新加载数据。
Http Server的开发中,Last-Modified使用了文件更改的最后时间,ETag记录了文件内容的hash值。
outputStream.write(data.getBytes("utf-8"));response.setHeader("ETag", data.hashCode() + "");response.setHeader("Last-Modified", date + "");response.setHeader("Content-Length", file.length() + "");复制
最后,文件以流的形式写入到Response中,写入到ES集群中。
String line;StringBuffer sb = new StringBuffer();while ((line = bufferedReader.readLine()) != null) {sb.append(line);sb.append("\n");}String data = sb.toString();outputStream.flush();bufferedReader.close();inputStreamReader.close();fileInputStream.close();复制
远程词典Server也支持用户进行手动更新或追加自己的词典或上传自己的词典文件到远程仓库中,做到动态更新IK分词词典的功能。
5、结果展示
使用IK分词器的max_word算法对“肯德基宅急送”进行分词,如果使用IK默认的分词规则,则分词后的结果如下图所示。

可以看出,“肯德基宅急送”被分成了“肯德基”,“宅急送”等多个词。同样以“肯德基宅急送”为例,把“肯德基宅急送”放到自定义词典中,不用重启集群,60s后,ES会请求IKServer更新分词词典,ES重新加载自定义词典日志如下图所示:
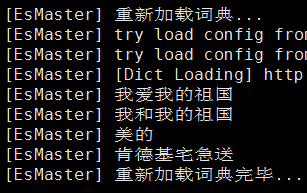
从图中可以看出,ES重新加载词典完毕,“肯德基宅急送”也加载成功。同样再次对“肯德基宅急送”进行分词,分词结果如下所示:
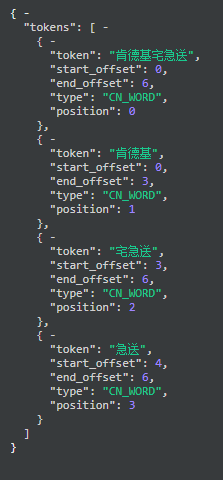
从分词结果可以看出,“肯德基宅急送”被单独分成一个词,而之前不使用自定义词典的分词结果同样也存在,这样就同时满足了精确查询和模糊匹配,提高了查询性能和准确度。
6、开发中遇到的问题
本次主要是IkServer和IkClient的开发,在开发过程中,出现一些问题,总结如下:
1.IKSever接口返回的response需要指定Last-Modified 和 ETag,否则会出现ES请求接口时无法判断自定义词典是否修改过,通过对比本地的Last-Modified 和 ETag会认为词典文件没有更改,无需重新加载,导致自定义词典不生效。
2.IkServer接口返回的response需要指定Content-Length,否则会出现ES请求接口时,加载词典失败。
7、总结与展望
本文重点讲解ES自定义分词原理、倒排索引以及服务端开发流程,通过结果展示,可以看到,自定义分词词典可以更好的对数据进行存储和查询,可以使查询性能更加的快捷、准确。
ES大数据平台作为一种快捷的查询平台已经被多个项目组所青睐,目前,ES大数据平台的技术架构如下图所示:
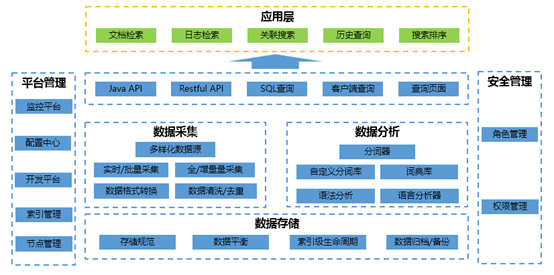
ES大数据平台已逐渐趋于规范、完善,能够满足各个项目组大量的需求,欢迎感兴趣的项目组积极与我们沟通、了解和使用。
参考文献:
https://www.elastic.co/guide/en/elasticsearch/plugins/7.10/
https://www.cnblogs.com/dreamroute/p/8484457.html
《Elasticsearch源码解析及优化实战》

更多精彩 敬请关注
践行金融科技
分享数据智能
