





能力是什么,拥有985,211的学历证明,还是钻研各种技术,艺术后,获得的技术专家,或艺术家的title, 或许都不是,能力是变化的,能力是指你能满足他人需求,能提供的一种实力,而我们在这个社会,往往把这样的能力和金钱挂钩,用数字来和别人证明你的能力。
1 n_distinct
2 most_common_vals
3 most_common_freqs
dvdrental=# \d pg_stats
View "pg_catalog.pg_stats"
Column | Type | Collation | Nullable | Default
------------------------+----------+-----------+----------+---------
schemaname | name | | |
tablename | name | | |
attname | name | | |
inherited | boolean | | |
null_frac | real | | |
avg_width | integer | | |
n_distinct | real | | |
most_common_vals | anyarray | | |
most_common_freqs | real[] | | |
histogram_bounds | anyarray | | |
correlation | real | | |
most_common_elems | anyarray | | |
most_common_elem_freqs | real[] | | |
elem_count_histogram | real[] | | |
1 n_distinct
3 most_common_freqs
这里根据相关的表信息的描述,n_disinct的值,在不等于1的情况下,都可以考虑来讲这个字段作为建立索引的可选项。
同时我们针对 most_common_vals 对应 most_comon_freqs 两个字段的值来判定所选的索引,在查询的时候被作为条件时,可能会产生的影响。
我们以下表的列子为例
dvdrental=# select *,t_vals.freqs::float * t_rels.reltuples as rows
from (SELECT tablename,attname,unnest(most_common_vals::text::text[]) as vals,unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM g_class CLS LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor')
dvdrental-# ;
tablename | attname | vals | freqs | relname | reltuples | rows
-----------+-------------+------------------------+-------+---------+-----------+------
actor | first_name | Austin | 0.02 | actor | 200 | 4
actor | first_name | Kenneth | 0.02 | actor | 200 | 4
actor | first_name | Penelope | 0.02 | actor | 200 | 4
actor | first_name | Burt | 0.015 | actor | 200 | 3
actor | first_name | Cameron | 0.015 | actor | 200 | 3
actor | first_name | Christian | 0.015 | actor | 200 | 3
actor | first_name | Cuba | 0.015 | actor | 200 | 3
actor | first_name | Dan | 0.015 | actor | 200 | 3
actor | first_name | Ed | 0.015 | actor | 200 | 3
actor | first_name | Fay | 0.015 | actor | 200 | 3
actor | first_name | Gene | 0.015 | actor | 200 | 3
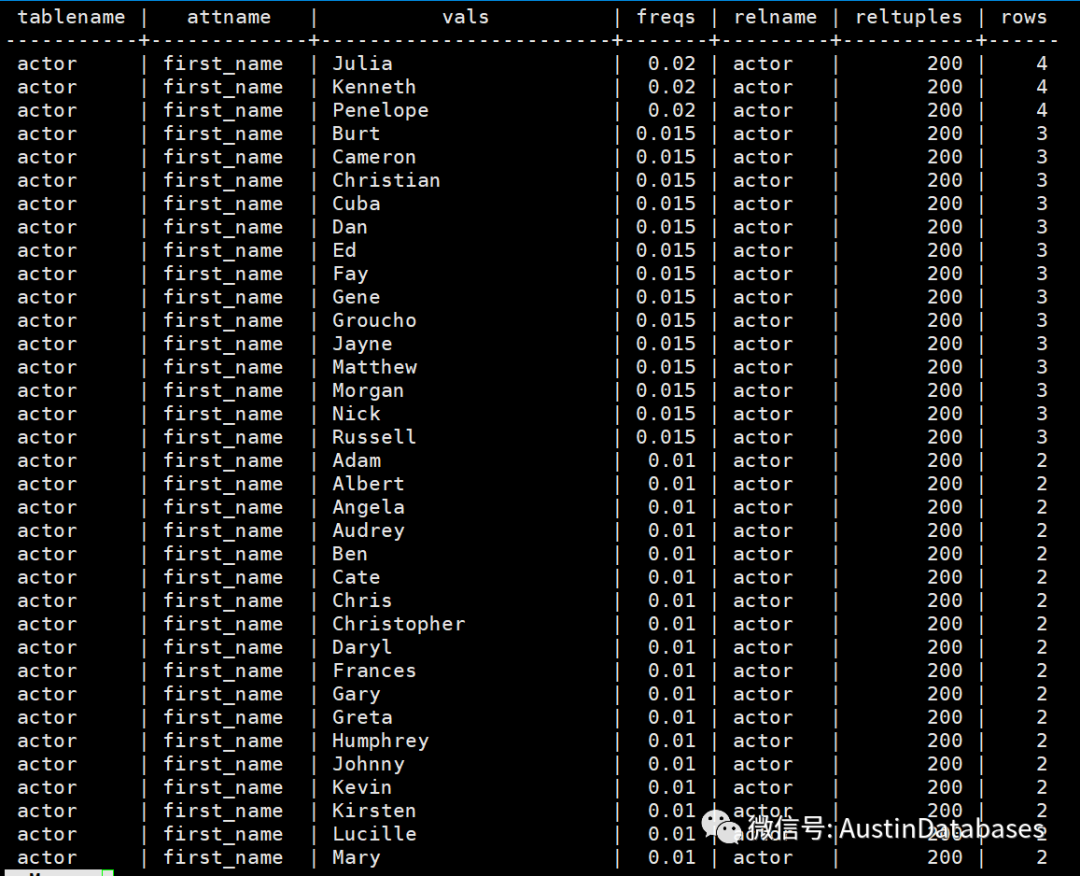
从上面的信息中,我们可以看到一个比啊中的列大致有那些列的值,并且这些值在整个表中占比是多少,通过这个预估的占比,我们马上可以获知,这个值在整个表行中的大约会有多少行,但基于这个值是预估的,所以不是精确的值,同时根据analyze 中对于数据的分析,他们是有采样率的表越大行数越多,这个采样率会变得越小,所以会导致上面的结果和实际的结果是有出入的。
但如果表小,则计算出的评估值和实际值之间的准确性还是蛮高的,参见上图Julia,值的评估。
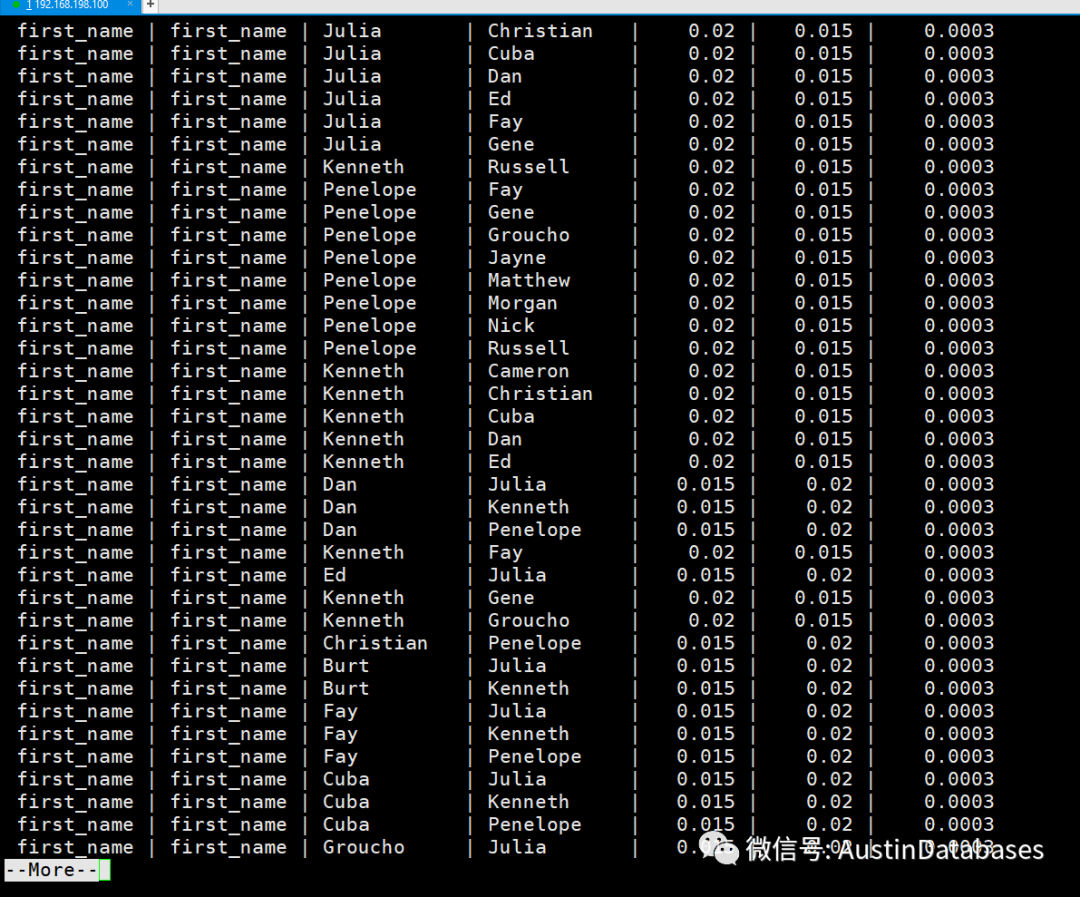
但如果将这个思路打开,则我们还可以做更多有意思的事情,甚至写出一个评估索引好坏的程序。
with first_name as (
select *,t_vals.freqs::float as freqs_1
from (SELECT tablename,attname,
unnest(most_common_vals::text::text[]) as vals,
unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM pg_class CLS
LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor') and attname = 'first_name'),
last_name as (
select *,t_vals.freqs::float as freqs_2
from (SELECT tablename,attname,
unnest(most_common_vals::text::text[]) as vals,
unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM pg_class CLS
LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor') and attname = 'first_name')
select first_name.attname as first_name,last_name.attname as last_name,
first_name.vals,last_name.vals,first_name.freqs_1,last_name.freqs_2,first_name.freqs_1 * last_name.freqs_2 as index_qua
from first_name
left join last_name on first_name.tablename = last_name.tablename
order by index_qua desc;

文章转载自AustinDatabases,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
