




CLIP介绍
https://huggingface.co/docs/transformers/model_doc/clip
CLIP(Contrastive Language-Image Pretraining)
是由OpenAI开发的一种基于对比学习的跨模态预训练模型。CLIP的目标是通过将图像和文本进行联合训练,从而使模型能够理解和推理图像和文本之间的关系。
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
# 加载模型和预处理函数
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 提取图片和文本特征
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
CLIP组成
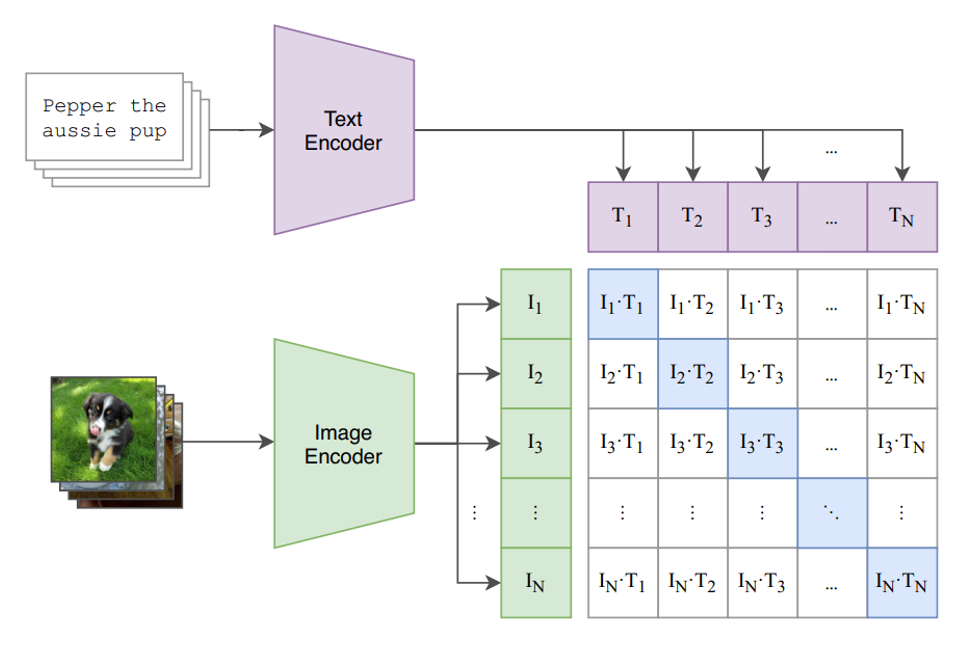
CLIP的训练过程包括两个关键组件:视觉编码器和文本编码器。视觉编码器是一个卷积神经网络,用于将图像转换为特征向量。文本编码器则是一个Transformer模型,用于将文本转换为特征向量。这两个编码器都经过大规模的无监督训练来学习图像和文本的表示。
CLIP训练过程
在训练过程中,CLIP使用大规模的图像和文本数据集来生成正负样本对。正样本对是由相同内容的图像和文本组成,而负样本对则是由不相关的图像和文本组成。CLIP的目标是通过对比学习来使正样本对在特征空间中更加接近,而负样本对则更加分散。
CLIP使用了一种对比学习的方式,在4亿图文对上进行了文本和图片的匹配任务训练,使得该模型在无任何微调的情况下(zero-shot),在imageNet上取得了和ResNet-50微调后一样的效果。
对于一个包含N
个文本-图像对的训练batch,将N
个文本特征和N
个图像特征两两组合,CLIP模型会预测出N*N
个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity)。

真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N*N-N
个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N*N-N
个负样本的相似度。
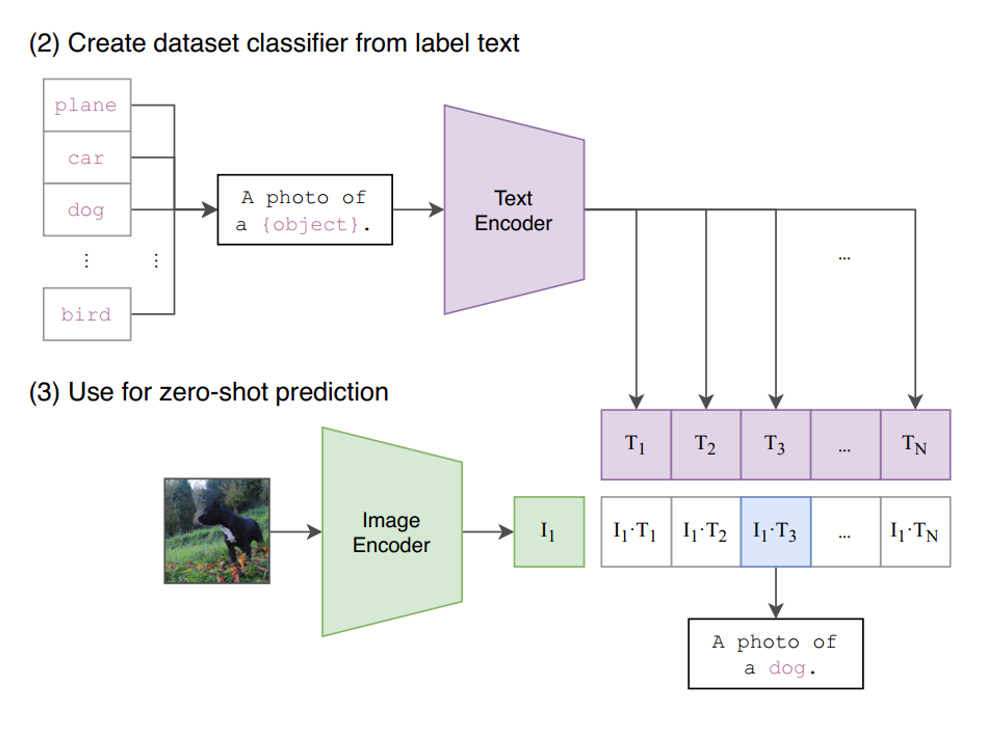
CLIP使用方法
训练完成后,CLIP可以通过计算图像和文本之间的余弦相似度来判断它们之间的关系。例如,给定一张图像和一个文本描述,CLIP可以计算它们在特征空间中的相似度,从而判断它们是否相互匹配。
Chinese-CLIP介绍
https://huggingface.co/docs/transformers/model_doc/chinese_clip
Chinese-CLIP
为CLIP模型的中文版本,使用大规模中文数据进行训练(~2亿图文对),帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务。
from PIL import Image
import requests
from transformers import ChineseCLIPProcessor, ChineseCLIPModel
model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# Squirtle, Bulbasaur, Charmander, Pikachu in English
texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
# compute image feature
inputs = processor(images=image, return_tensors="pt")
image_features = model.get_image_features(**inputs)
image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute text features
inputs = processor(text=texts, padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute image-text similarity scores
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
CLIP使用场景
使用场景1:图像检索图像
CLIP可以用于图片检索任务,即通过输入一张图像,计算其特征向量,并与图像数据库中的其他图像进行相似度匹配。
使用场景2:文本检索文本
CLIP可以将文本描述转换为特征向量,并将其与图像数据库中的图像进行比较,找到与文本描述最相关的图像。
使用场景3:文本检索图像 or 图像检索文本
将文本查询和每个图像都转换为特征向量,然后计算它们之间的相似度。通过比较文本查询和图像的特征向量,CLIP可以找到与查询最相关的图像。
# 竞赛交流群 邀请函 #

添加Coggle小助手微信(ID : coggle666)
每天算法竞赛、干货资讯和大模型知识汇总
与 35000+来自AI爱好者一起交流~

