




前言
上篇文章简单叙述了下浏览器两大引擎的渲染引擎,这回简单讲下浏览器的JS引擎,以常见的 Chrome V8引擎 进行讲述,Chrome V8引擎如何执行一段JS代码的。
JS的加载和执行
JS中可能会操作DOM树的代码等,所以不会像CSSna那样并行加载。
浏览器在加载JS时候会
加载完成后会立即执行
执行时会阻塞页面后续的页面渲染、其他资源的下载
当有多个JS文件被引入时,浏览器会把多个文件按顺序的串行载入并依次执行。
在IE6时代,IE浏览器在script标签加上defer属性,JS文件并行加载,但是执行会在DOM树加载完成时候执行;有 defer 属性的脚本会阻止 DOMContentLoaded 事件,直到脚本被加载并且解析完成。
// 例:<script defer src="./jquery.js"type="text/javascript" charset="utf-8"></script>
HTML5 script标签上新增了async 属性,增加了async属性其脚本会并行请求,脚本内的所有依赖都会在队列中延缓执行,所以不会按照书写顺序而执行,谁先加载完成谁先执行,
JavaScript 引擎
JavaScript引擎就是能够将JS代码处理编译并执行的虚拟机。
JS引擎包括以下部分:
解析器:将代码结构化成抽象语法树(AST)。
解释器:顺序解释执行字节码,并输出执行结果。
编译器:将抽象语法树(AST)编译为二进制的机器代码再执行。
即时编译(JIT)
垃圾回收机制: 负责将程序不再需要的内存空间回收。Chrome V8 为了更高效地回收垃圾,引入了两个垃圾回收器,主垃圾回收器和副垃圾,它们分别针对着不同的场景
在Chrome V8出现之前,市面上的JS虚拟机都是采用解释执行的方式
这也是JS执行过慢的原因。Chrome V8 率先采用即时编译(JIT)
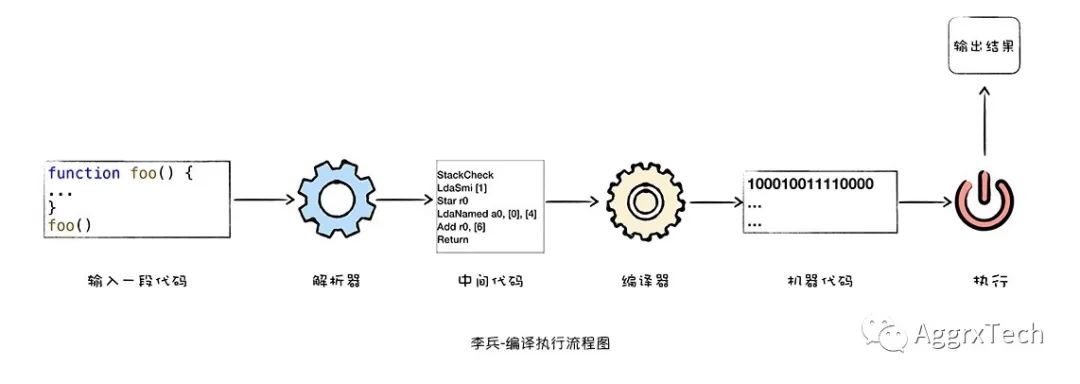 

解析器
解析器将代码结构化抽象成语法树,将以下面代码演示:
一个简单JS文件,中声明了一个变量并赋值。
// test.jsvar test = "HelloWorld"
使用Chrome V8的调试工具d8 命令查看test.js文件查看输出结果
d8 --print-ast test.js
使用d8命令后会打印出下面内容,他就是test.js代码结构化后的表述
--- AST ---FUNC at 0. KIND 0. LITERAL ID 0. SUSPEND COUNT 0. NAME "". INFERRED NAME "". DECLS. . VARIABLE (0x7ff0e3022298) (mode = VAR, assigned = true) "test". BLOCK NOCOMPLETIONS at -1. . EXPRESSION STATEMENT at 11. . . INIT at 11. . . . VAR PROXY unallocated (0x7ff0e3022298) (mode = VAR, assigned = true) "test". . . . LITERAL "HelloWorld"
转化为树形图: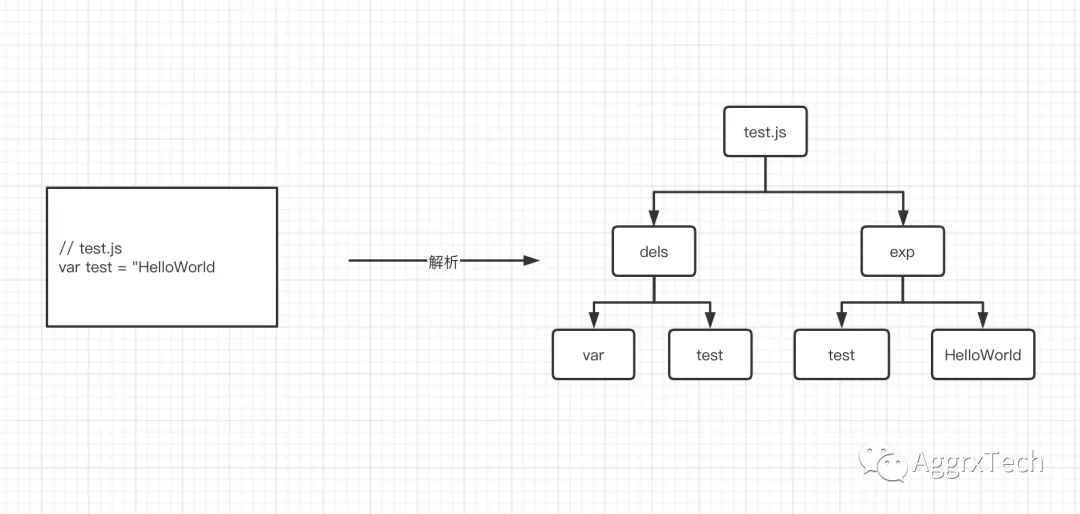 

树形图中AST和代码一一对应,后续的所有操作也基于此,Chrome V8 生成 AST同时也会生成作用域,同样使用d8命令进行查看
d8 --print-scopes test.js// 输出Global scope:global { // (0x7fd974022048) (0, 24)// will be compiled// 1 stack slots// temporary vars:TEMPORARY .result; // (0x7fd9740223c8) local[0]// local vars:VAR test; // (0x7fd974022298)}// 结束
此时会看到 声明的test变量在global全局作用域中,生成了AST和作用域下一步就是使用解释器生成生成字节码。
解释器
同样使用d8直接转成字节码
d8 --print-bytecode test.js// 输出[generated bytecode for function: (0x2b510824fd55 <SharedFunctionInfo>)]Parameter count 1Register count 4Frame size 320x2b510824fdd2 @ 0 : a7 StackCheck0x2b510824fdd3 @ 1 : 12 00 LdaConstant [0]0x2b510824fdd5 @ 3 : 26 fa Star r10x2b510824fdd7 @ 5 : 0b LdaZero0x2b510824fdd8 @ 6 : 26 f9 Star r20x2b510824fdda @ 8 : 27 fe f8 Mov <closure>, r30x2b510824fddd @ 11 : 61 32 01 fa 03 CallRuntime [DeclareGlobals], r1-r30x2b510824fde2 @ 16 : 12 01 LdaConstant [1]0x2b510824fde4 @ 18 : 15 02 02 StaGlobal [2], [2]0x2b510824fde7 @ 21 : 0d LdaUndefined0x2b510824fde8 @ 22 : ab ReturnConstant pool (size = 3)0x2b510824fd9d: [FixedArray] in OldSpace- map: 0x2b51080404b1 <Map>- length: 30: 0x2b510824fd7d <FixedArray[4]>1: 0x2b510824fd1d <String[#8]: GeekTime>2: 0x2b51081c8549 <String[#4]: test>Handler Table (size = 0)Source Position Table (size = 0)// 结束
上面就是test.js 生成的字节码,生成字节码之后,解释器会解释执行这段字节码
如果重复执行了某段代码,监控器就会将其标记为热点代码,并提交给编译器优化执行。
到了这个一步时候解释器会将生成的字节码编译成二进制代码并交由CPU执行二进制代码, 热点代码会进行优化
下图举例: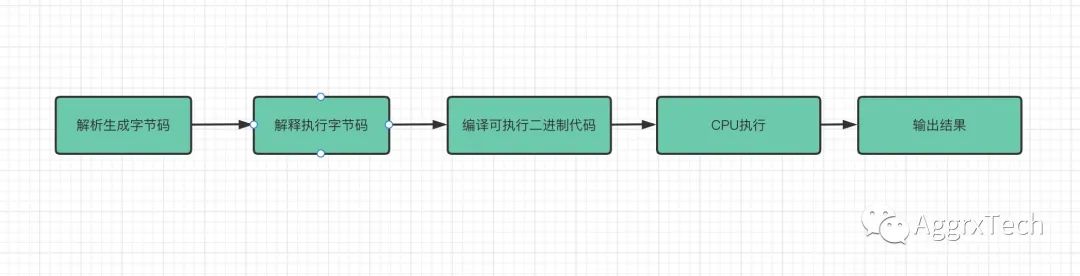 

当某段代码被标记为了热点代码后,Chrome V8 就会将这段字节码交给优化编译器,优化编译器会将这段字节码在后台编译为二进制代码,然后再对编译后的二进制代码执行优化操作,优化后的二进制机器代码的执行效率会得到大幅提升。
如果后期热点代码再被调用时时,那么 V8 会优先选择优化之后的二进制代码,这样代码的执行速度就会大幅提升。
但是 JS 是非常灵活的语言,对象的结构和属性可以在运行时候任意修改,而优化编译器优化过的代码只能针对某种固定的结构,一旦在执行过程中,发现对象的结构被动态修改了,那么优化之后的代码势必会变成无效的代码,这时候优化编译器就需要执行反优化操作,经过反优化的代码,下次执行时就会回退到解释器解释执行。
这也就是为什么声明对象最好一次性声明完毕,不要动态添加属性的原因,这样可以减少被优化的二进制代码次数。
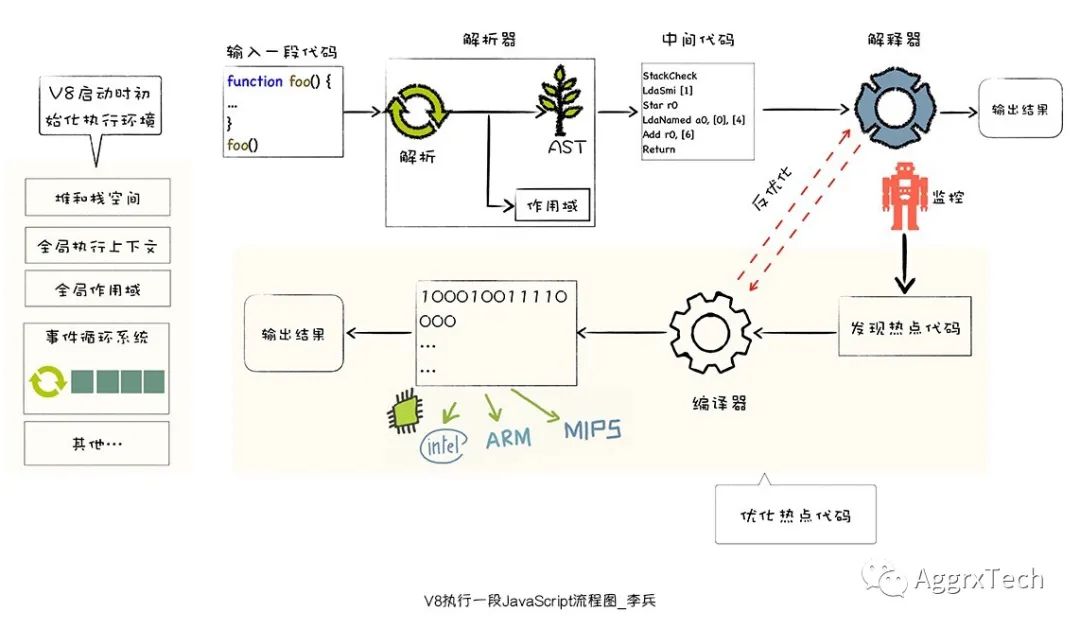 

事件循环系统和垃圾回收机制
上面简单讲述了,Chrome V8的编译流程,但在JS 引擎中有两个非常重要的特性就是 事件循环 和 垃圾回收机制。
事件循环
JS是单线程的,代码都会在一个线程上执行,如果同一时间请求过多就需要排队,也就是异步编程
Chrome V8 的事件循环系统会调度这些排队任务,保证 JavaScript 代码被 V8 有序地执行。
垃圾回收
JS也是一个自动垃圾回收的语言, Chrome V8在执行垃圾回收时,是会占用主线程的资源
如果我们写的代买频繁触发垃圾回收机制,那么无疑会阻塞主线程。下面简单说下 Chrome V8引擎的消息队列和垃圾回收机制。
HTML 5发布了Web worker,可以在后台运行的JS,独立于主线程的后台线程中,不会影响到页面的性能。
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API
Chrome V8垃圾的定义
大家都知道 JS有垃圾回收机制,Chrome V8引擎是有两个垃圾回收器的,主垃圾回收器和副垃圾,它们分别针对着不同的场景。
垃圾数据是如何产生的呢?我们在频繁地使用数据,这些数据会被存放到栈和堆中,通常的方式是在内存中创建一块空间,使用这块空间,在不需要的时候回收这块空间。
window.test = new Object();window.test.arr = new Uint16Array(100);
在上列代码中先为 window 对象添加了test属性,并在堆中创建了一个空对象,让window.test指向了该空对象的堆中地址,然后创建了一个长度100的数组,并将 test.arr指向了该数组。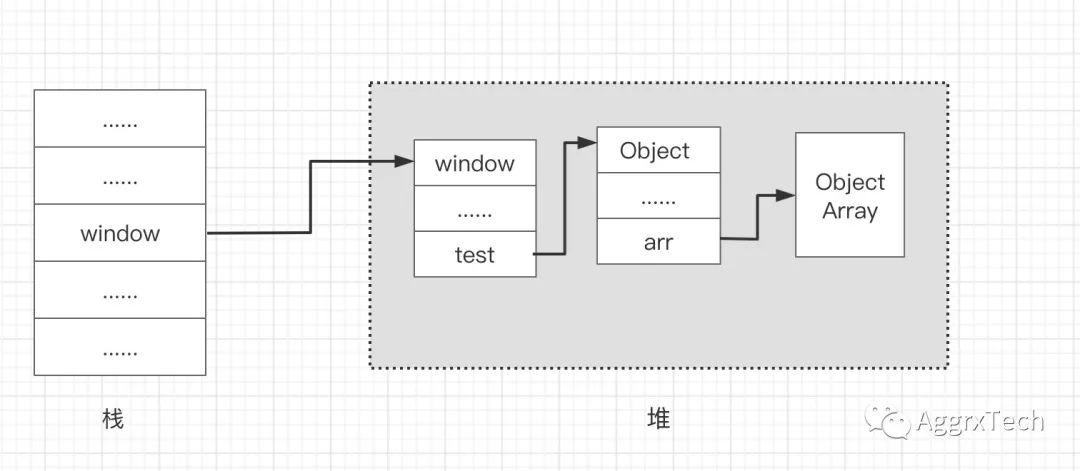 

从上图可以看到栈堆的指向, 如果此时重新给 window.test.arr 赋值,把数组改成一个对象:
window.test.arr = new Object();
此时的内存中就会如下图所示。
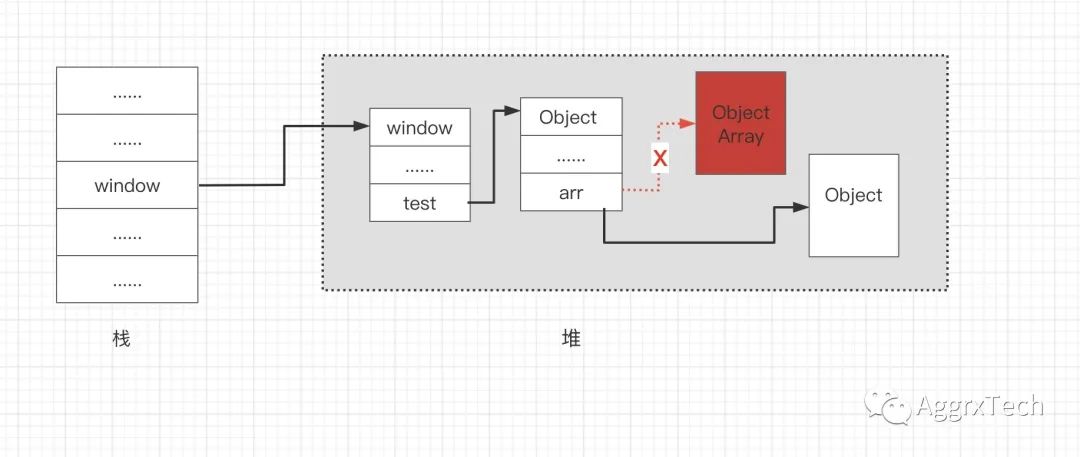 

之前的arr属性指向的是堆中的数组对象,现在已经指向了一个空的对象,那么此时堆中的数组对象就成为了垃圾数据,Chrome V8的 垃圾回收机制会自动清理回收该位置内存。
Chrome V8的垃圾回收
垃圾回收器回收过程1_标记及其算法
目前 V8 采用的可访问性(reachability)算法来判断堆中的对象是否是活动对象。具体地讲,这个算法是将一些 GC Root 作为初始存活的对象的集合,从 GC Roots 对象出发,遍历 GC Root 中的所有对象:
浏览器中GC Roots 有很多种通常包括以下几种:
全局的window对象,包括每个iframe
文档 DOM 树,由可以通过遍历文档到达的所有原生 DOM 节点组成。
存放栈上变量
通过 GC Root 遍历,根据一个对象是否被遍历到(是否被引用),对象被分为:
活动对象:可遍历到的对象,我们就认为该对象是可访问的(reachable),那么必须保证这些对象应该在内存中保留
非活动对象:没有遍历到的对象,则是不可访问的(unreachable),那么这些不可访问的对象就可能被回收
垃圾回收器回收过程2_新生代和老生代
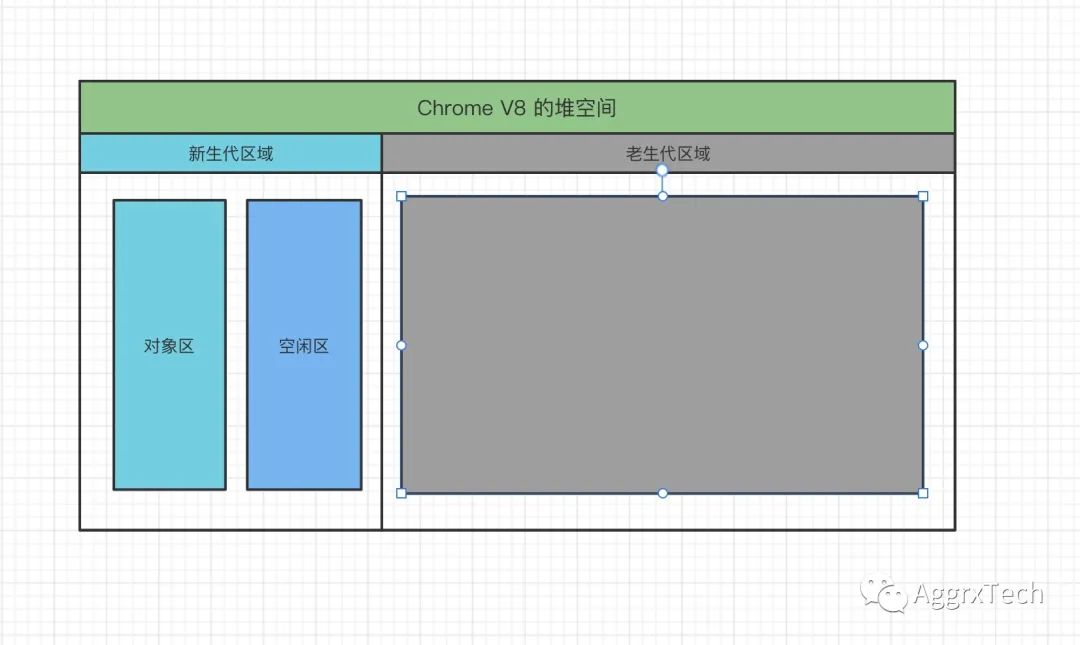
标记完成之后,需要执行接下来内存回收的过程,我们先介绍V8两个不同的堆区域
新生代区域
新生代中主要是存放的是生存时间短的对象
老生代区域
老生代区域存放生存时间久的对象
新生代区域空间较小,一些较大的对象会直接分配到老生代区域
新生代到老生代的迁移
新生代区域中的对象,存在两个清理轮回之后依然可用,则会被晋升到老新生代区域
为什么要分两个区域
基于代际假说(The Generational Hypothesis)
注:代际假说(The Generational Hypothesis)
代际假说是垃圾回收领域的一个重要术语,他有两个特点
1. 大部分的对象都是临时存在的,在内存中存在时间比较短
像函数中声明的变量,for循环中声明的变量,块级作用域中声明的变量等,当函数和for循环执行结束后,其中声明的变量就会被销毁,其在内存中很快就会变得不可访问。
2. 会有很多对象都是永久存在的
例如浏览器中的 window对象、DOM、webAPI等。
垃圾回收器回收过程3_副垃圾回收器
副垃圾回收器,处理新生代的垃圾回收。
副垃圾回收器采用了 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。
新的数据都分配在新生代的对象区域,新生代区域容量较小,不如老生代区域庞大,当新生代区域的对象区快被存满时候,就会执行一次垃圾处理。
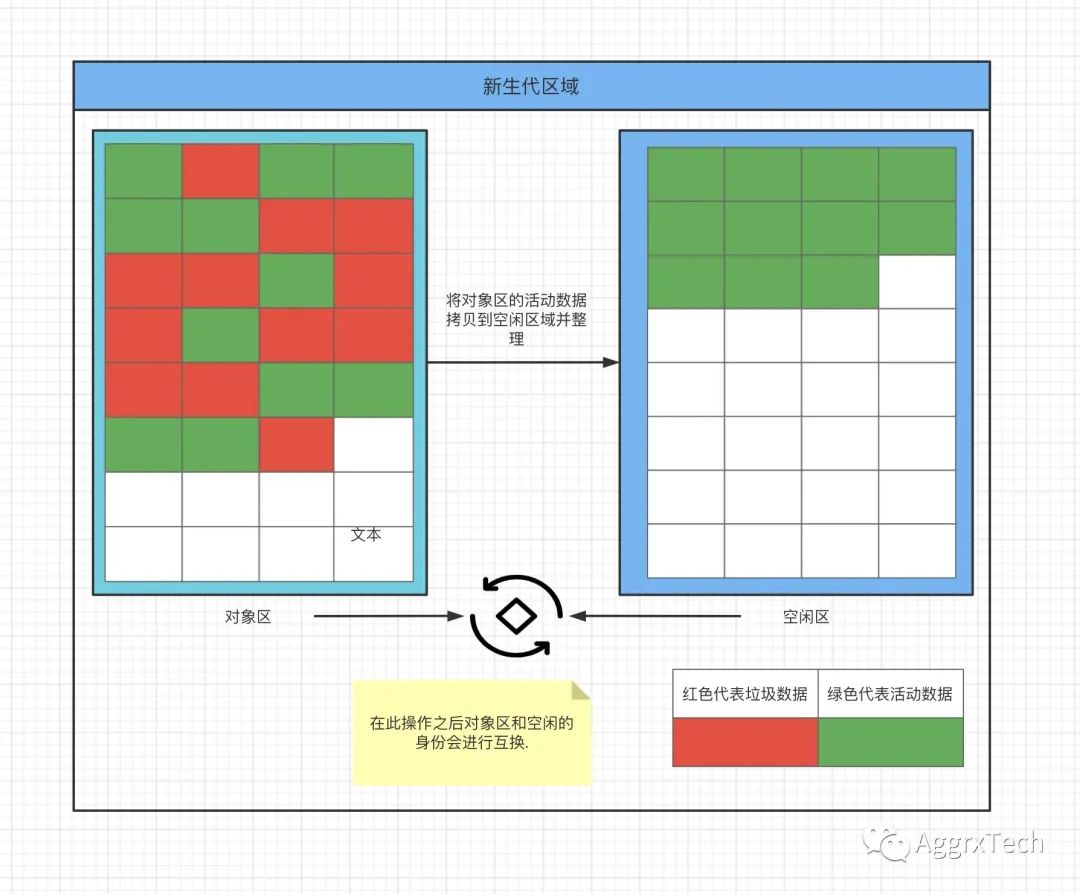
如上图所示,副垃圾回收器经历三个过程:
1. 标记
在回收过程中将对象不再使用的进行标记
2. 复制
整理将存活的对象整理并复制到空闲区域。
3. 对象qu区和空闲区互换
一切完成后会将对象区和空闲区的身份互换
垃圾回收器在执行回收过程时,同样会经历: 标记、清除和整理过程

垃圾回收器回收过程4_主垃圾回收器
老生代区域的数据大部分是较大的,无法像新生代区域一样分为两块,所以主垃圾回收器采用的是标记到清除再到整理的过程。
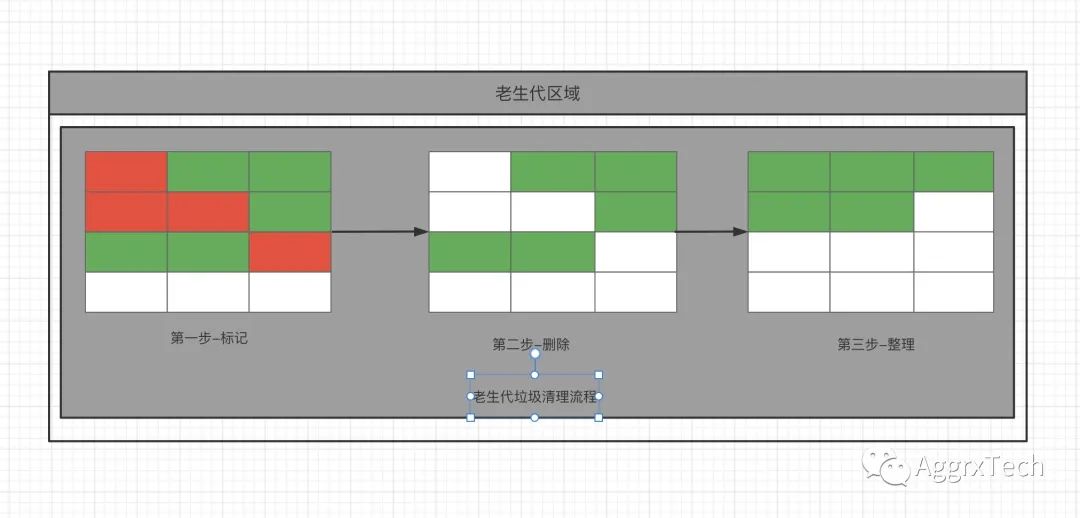
首先是标记过程,标记过程就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
再就是垃圾的清除过程,它和副垃圾回收器的垃圾清除过程完全不同,主垃圾回收器会直接将标记为垃圾的数据清理掉。
然后就是整理,因为清除过后会产生大量不连续的内存碎片,而碎片过多会导致大对象无法分配到足够的连续内存。整理过程就是将对象进行标记并像另一端移动,然后清理这一端之外的数据。
V8垃圾回收器新增特性
V8 最开始的垃圾回收器有两个特点,会在主线程上执行一个完整的垃圾回收流程、这样会造成主线程卡顿
后期V8对主垃圾回收器采用三个方案jin进行了优化,副垃圾回收器也采用了其中部分的方案:
增量式回收,垃圾回收器将标记工作分解为更小的块,并且穿插在主线程不同的任务之间执行
并行回收,在执行完整的垃圾回收流程中会使用多个辅助线程并行执行回收任务
并发回收,回收线程在执行 JavaScript 的过程,辅助线程能够在后台完成的执行垃圾回收的操作
结语
本章中简单讲述浏览器的加载和代码处理,Chrome V8 的垃圾回收机制如何工作的,下一篇文章将会围绕第一篇 浏览器渲染引擎,第二篇 JS引擎中的内容讲述下如何在前端代码书写时和后期的提高性能优化,避免内存泄漏等。
这其中的大家会发现少了 事件循环系统 的详细说明,这个我会单独一篇文章进行详细的讲解和演示。
参考文献
https://v8.dev/blog/concurrent-marking
https://gist.github.com/kevincennis/0cd2138c78a07412ef21
https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions
