




He3DB数据库和mysql数据库事务隔离级别对比
事务的隔离级别
SQL标准定义了四种隔离级别。最严格的是可序列化,一组可序列化事务的任意并发执行被保证效果和以某种顺序一个一个执行这些事务一样。其他三种隔离级别使用并发事务之间交互产生的现象来定义,每一个级别中都要求必须不出现一种现象。
在各个级别上被禁止出现的现象分别是:
1、脏读:一个事务读取了另一个并行未提交事务写入的数据。
2、不可重复读:一个事务重新读取之前读取过的数据,发现该数据已经被另一个事务(在初始读之后提交)修改。
3、幻读:一个事务重新执行一个返回符合一个搜索条件的行集合的查询, 发现满足条件的行集合因为另一个最近提交的事务而发生了改变。
4、序列化异常:成功提交一组事务的结果与这些事务所有可能的串行执行结果都不一致。
| 隔离级别 | 读未提交 | 读已提交 | 不可重复读 | 可序列化 |
|---|---|---|---|---|
| 脏读 | 可能 | 不可能 | 不可能 | 不可能 |
| 不可重复读 | 可能 | 可能 | 不可能 | 不可能 |
| 幻读 | 可能 | 可能 | 可能 | 不可能 |
| 序列化异常 | 可能 | 可能 | 可能 | 不可能 |
每种数据库引擎实现隔离级别的方式不一样,编码之前可以阅读其官方文档。
下面以对一个accounts表的并发操作的例子来分别演示mysql和He3DB中这四种隔离级别的表现。
读未提交(READ-UNCOMMITTED)
假设有三个账户,初始表如下:
accounts表
| id | owner | balace | currency | created_at |
|---|---|---|---|---|
| 1 | one | 100 | USD | 2020-09-06 15:09:38 |
| 2 | two | 100 | USD | 2020-09-06 15:09:38 |
| 3 | three | 100 | USD | 2020-09-06 15:09:38 |
accounts表,操作顺序如下
| 事务1 | 事务2 |
|---|---|
| begin; | begin; |
| select * from accounts; | select * from acounts where id = 1; |
| update accounts set balance = balance -10 where id =1; | |
| select * from acounts where id = 1; | |
| commit; | commit; |
MySQL执行结果:
事务1:
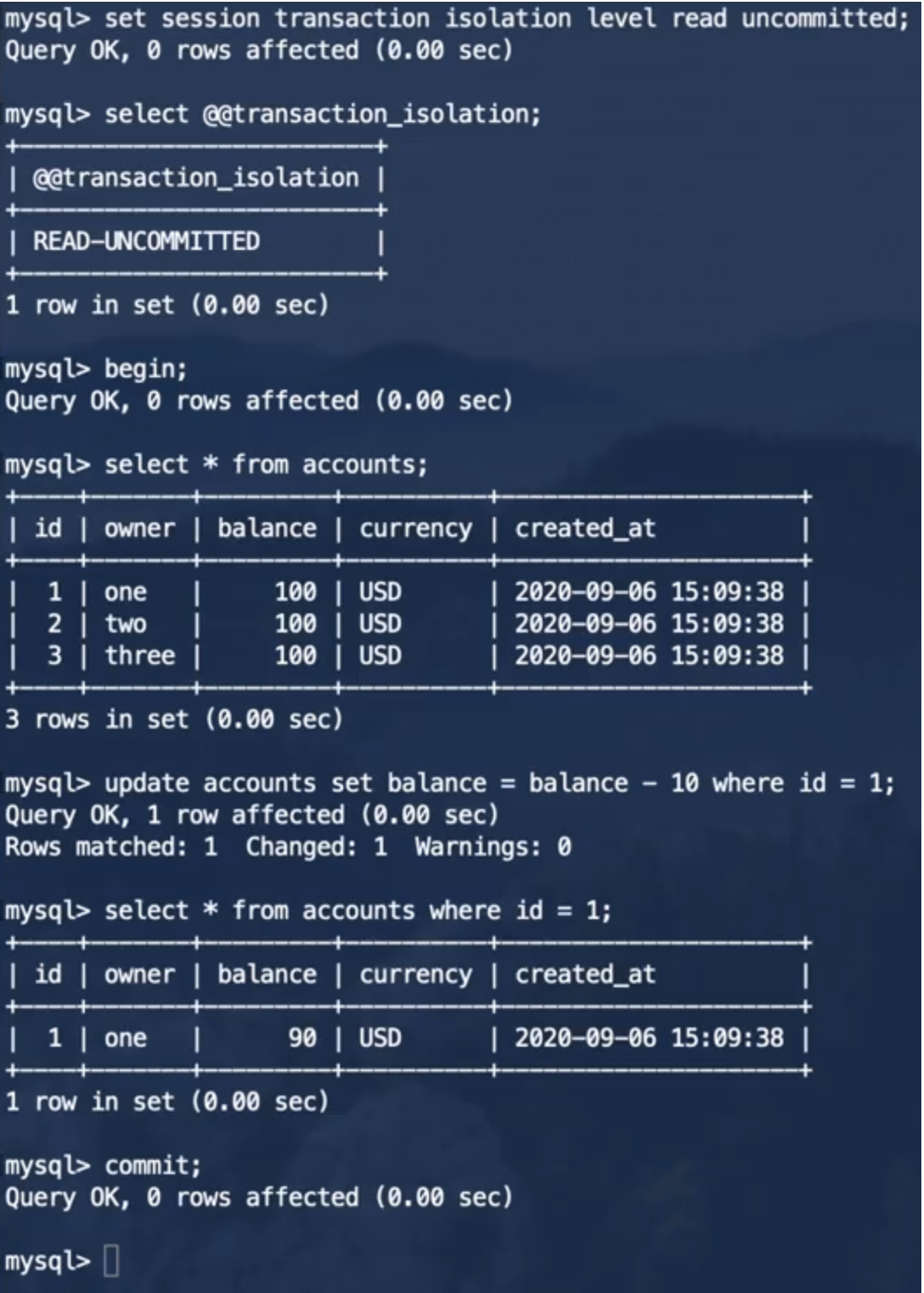
事务2:
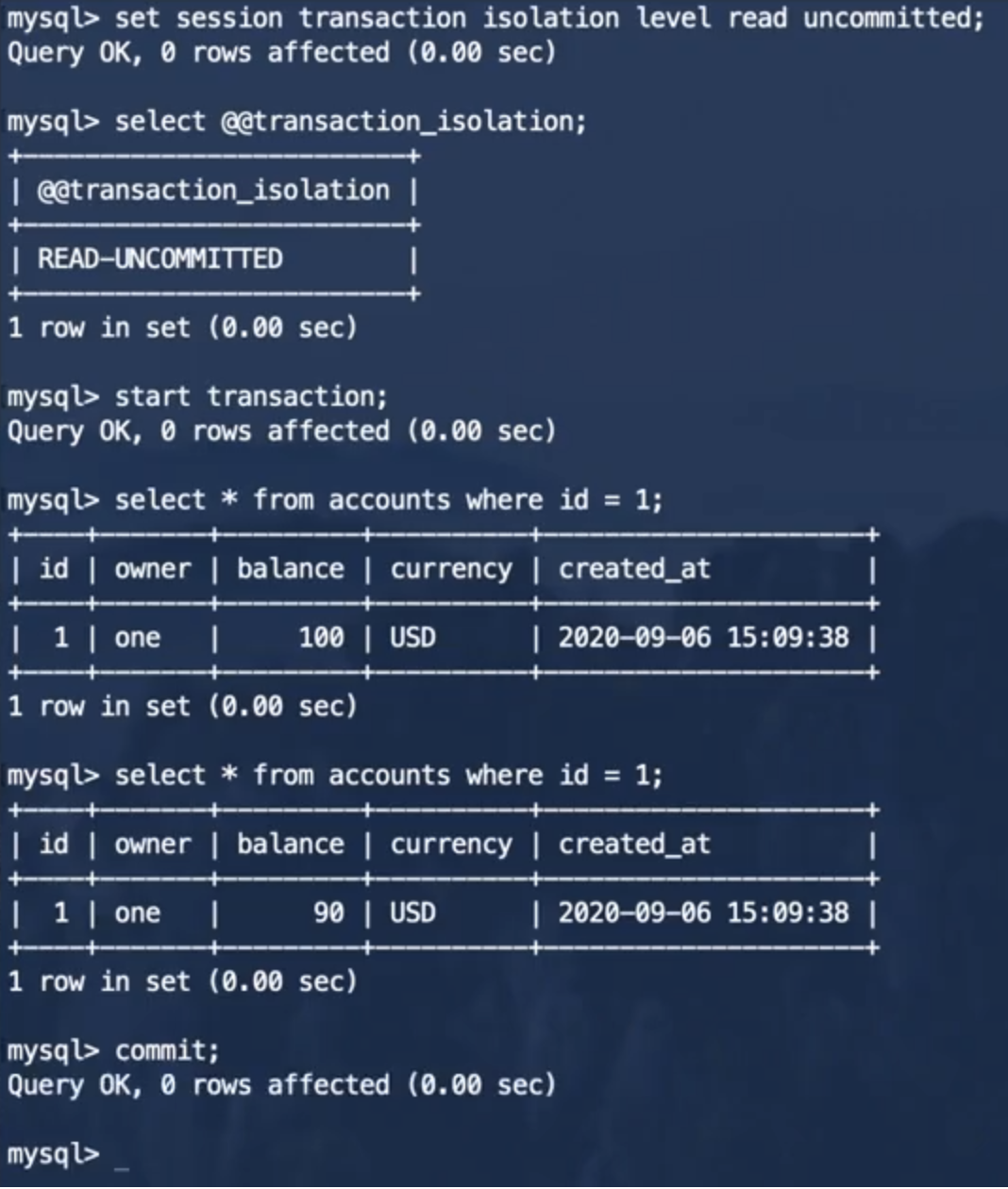
这种情况下,事务2读取了事务1还未提交的写入数据,即脏读。
He3DB的执行结果:
事务1:
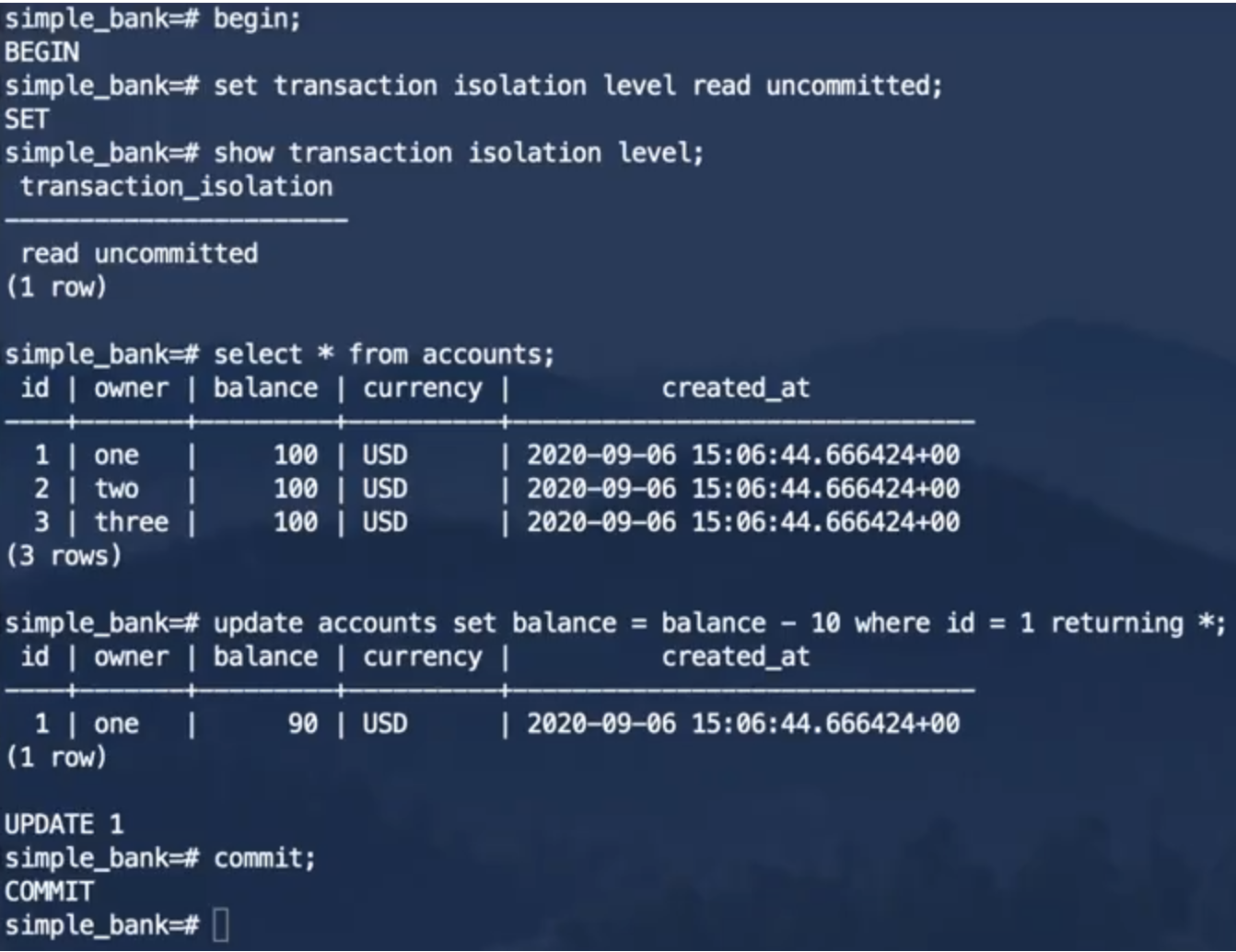
事务2:
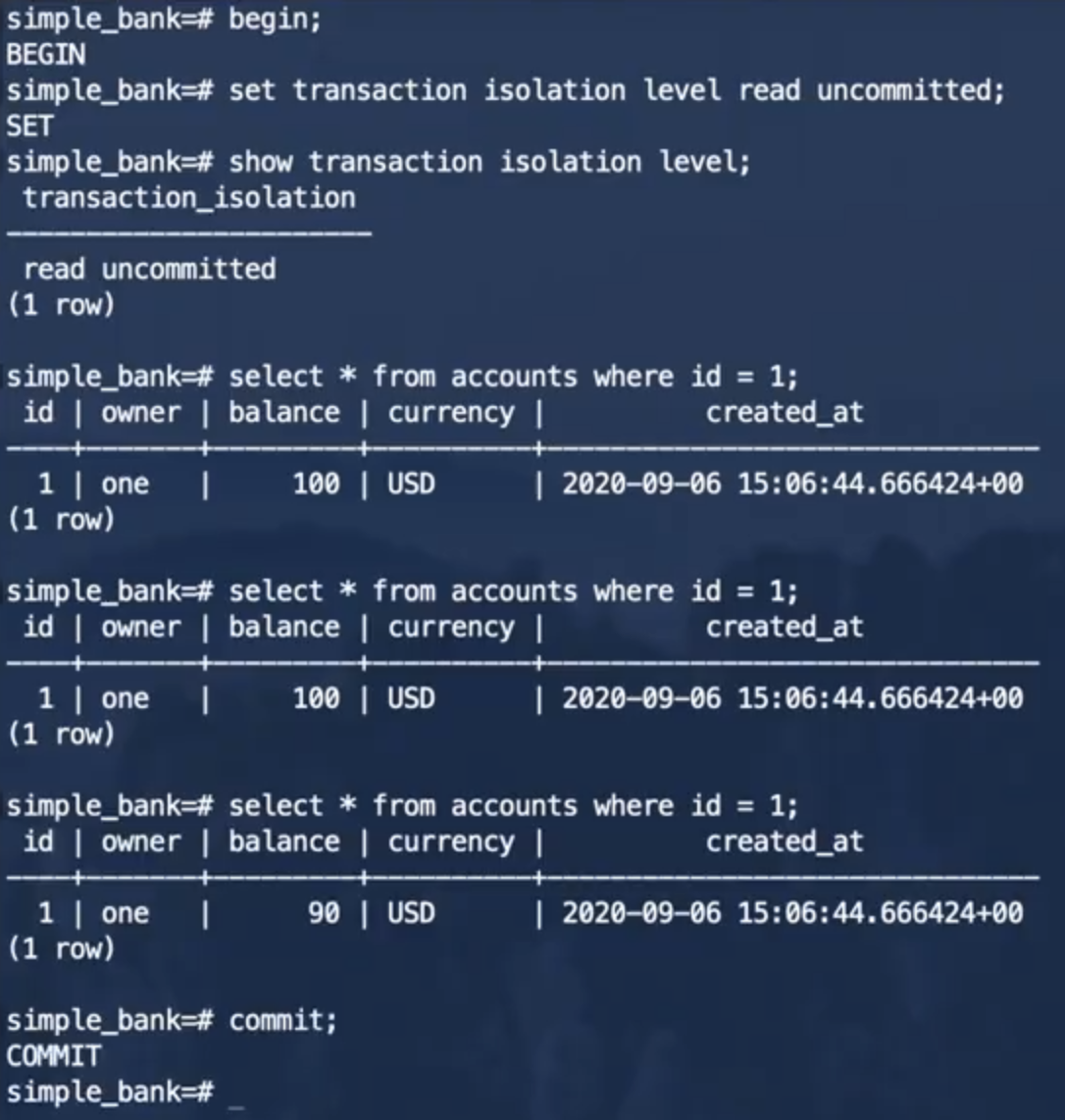
这里虽然设置的隔离级别是读未提交,但是在He3DB中也不会出现脏读的现象,如图所示,事务2的前两个查询是在事务1提交之前执行的,并没有读取到事务1未提交的数据。
读已提交(READ-COMMITTED)
读已提交隔离级别可以防止出现脏读现象,但是并不能防止不可重复读的发生,同样执行事务1和2,这次将隔离级别设置为读已提交(READ-COMMITTED),事务1和事务2执行顺序如下
| 事务1 | 事务2 |
|---|---|
| begin; | begin; |
| select * from accounts; | select * from acounts where id = 1; |
| select * from accounts where balance >= 90; | |
| update accounts set balance= balance -10 where id =1; | |
| select * from accounts where id = 1; | select * from accounts where id = 1; |
| select * from accounts where balance >= 90; | |
| commit; | |
| select * from accounts where id = 1; | |
| select * from accounts where balance >= 90; |
在MySQL中的结果如下:
事务1:
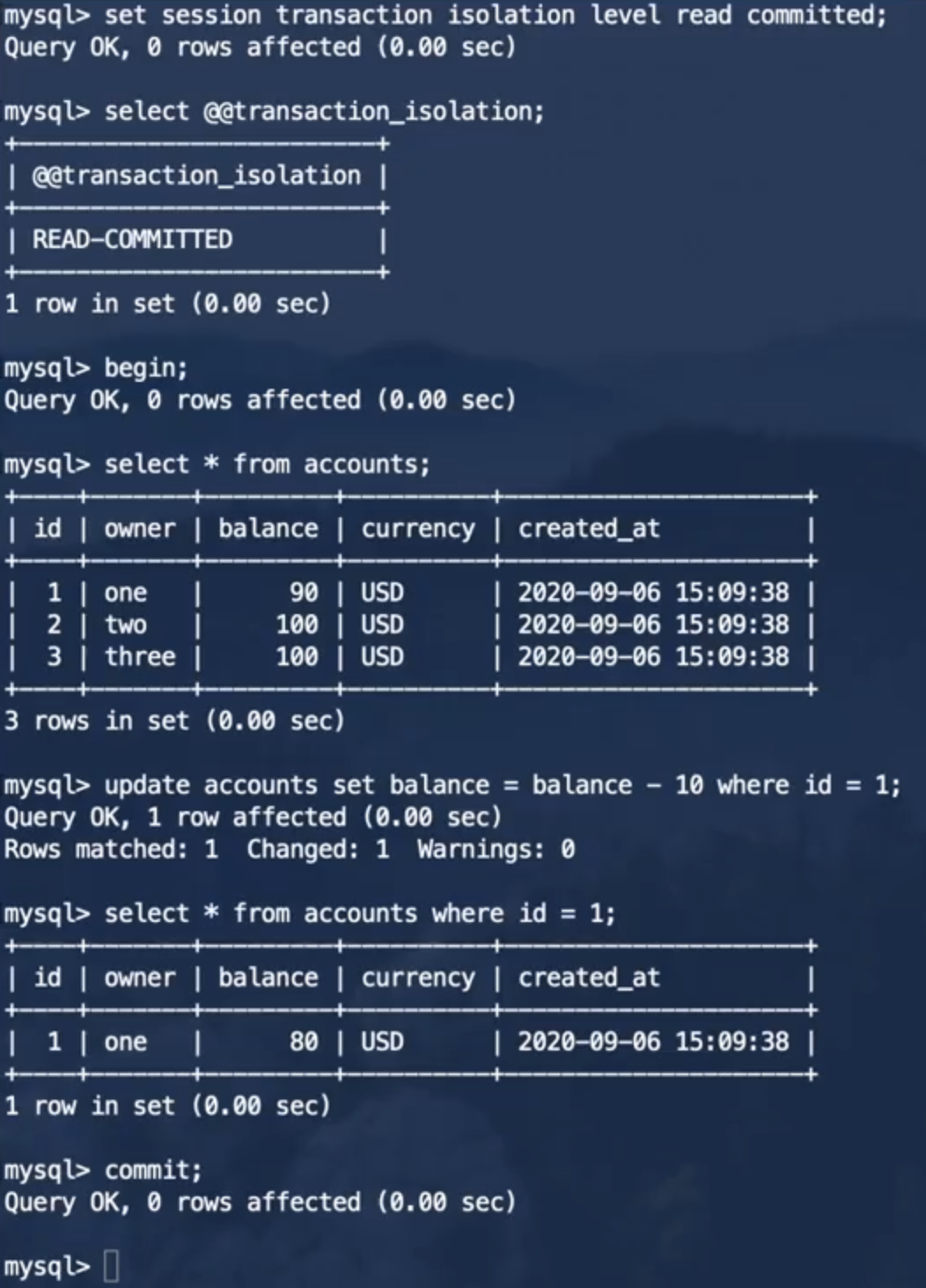
事务2:
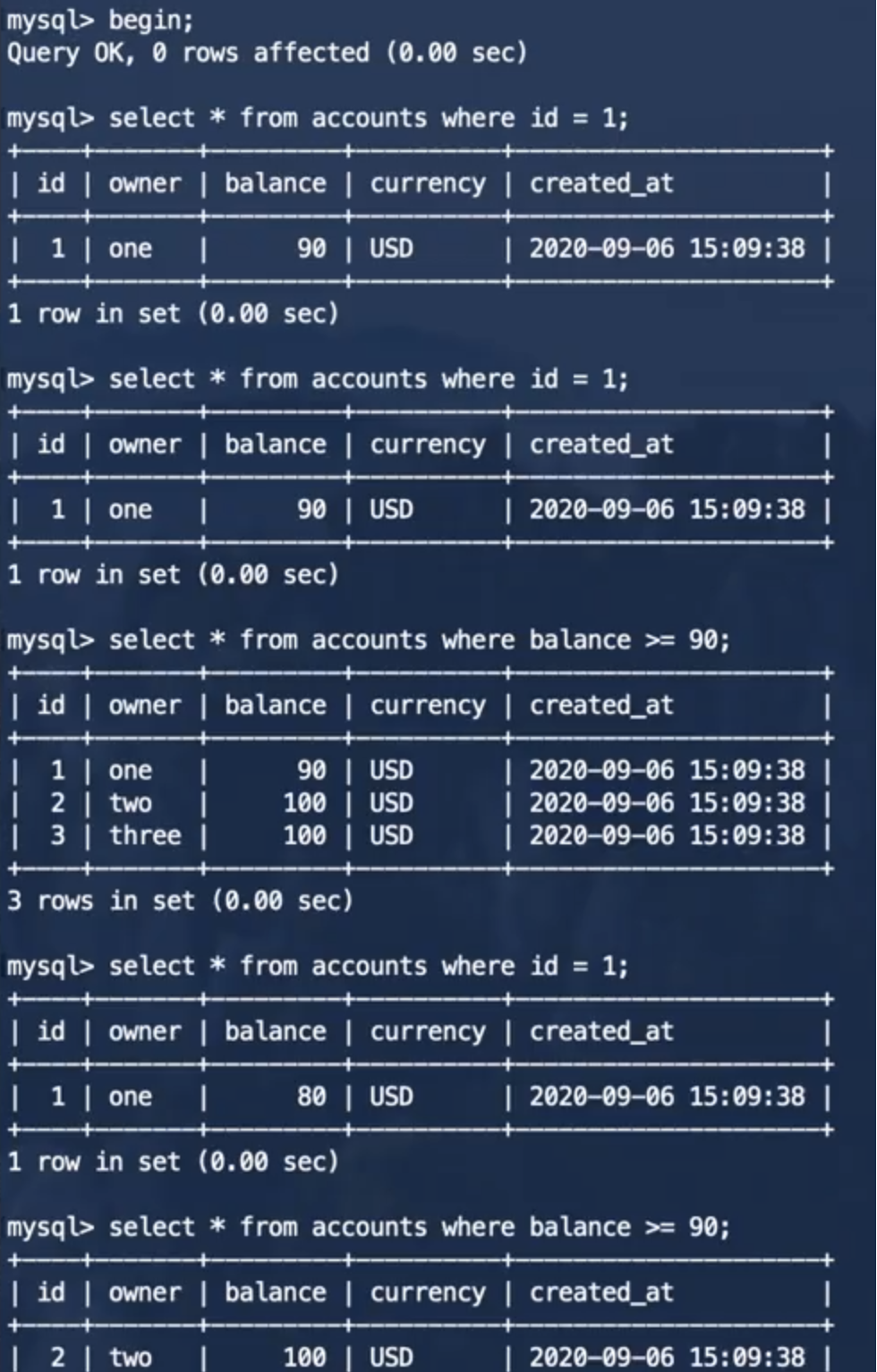
在He3DB中结果如下:
事务1:
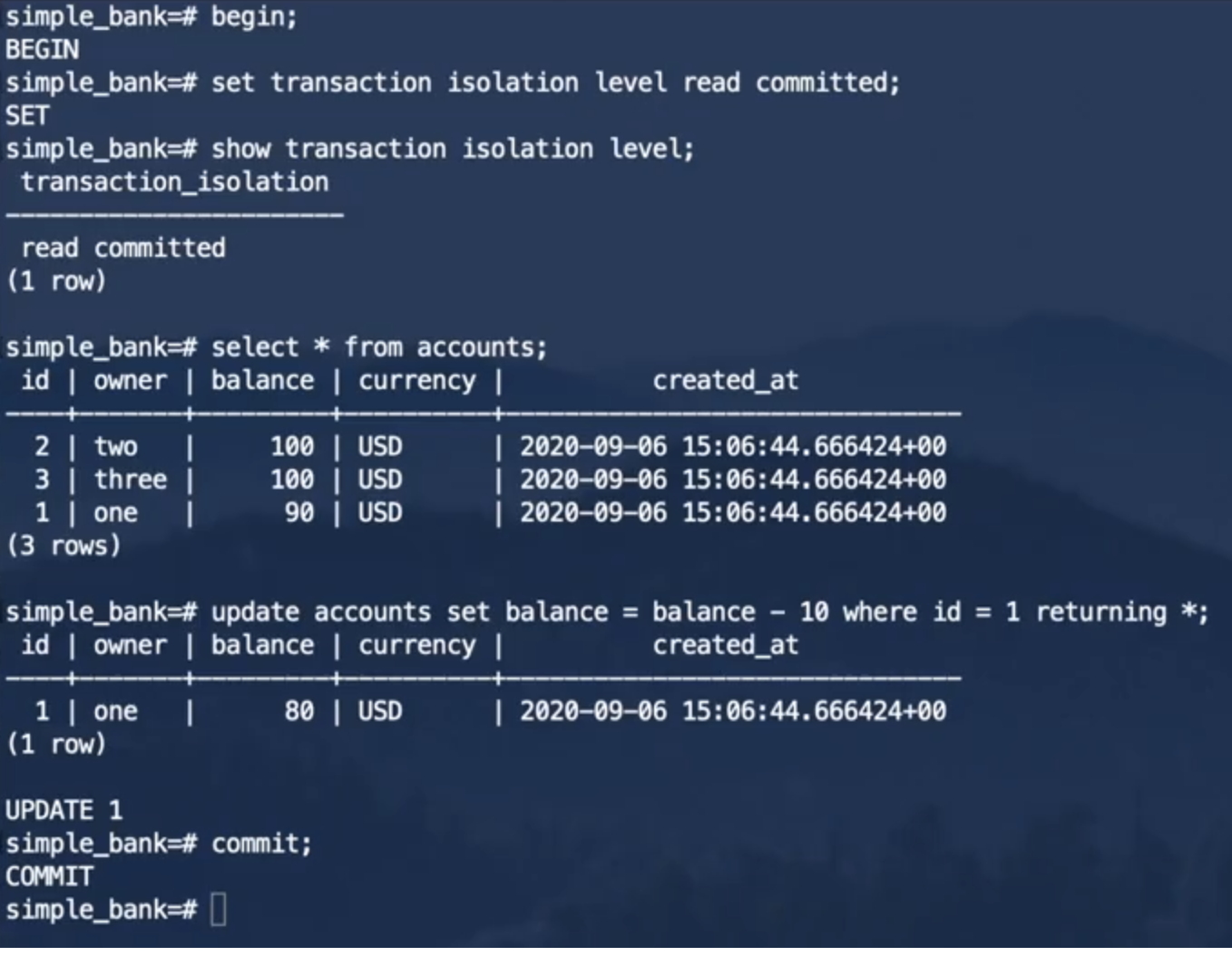
事务2:
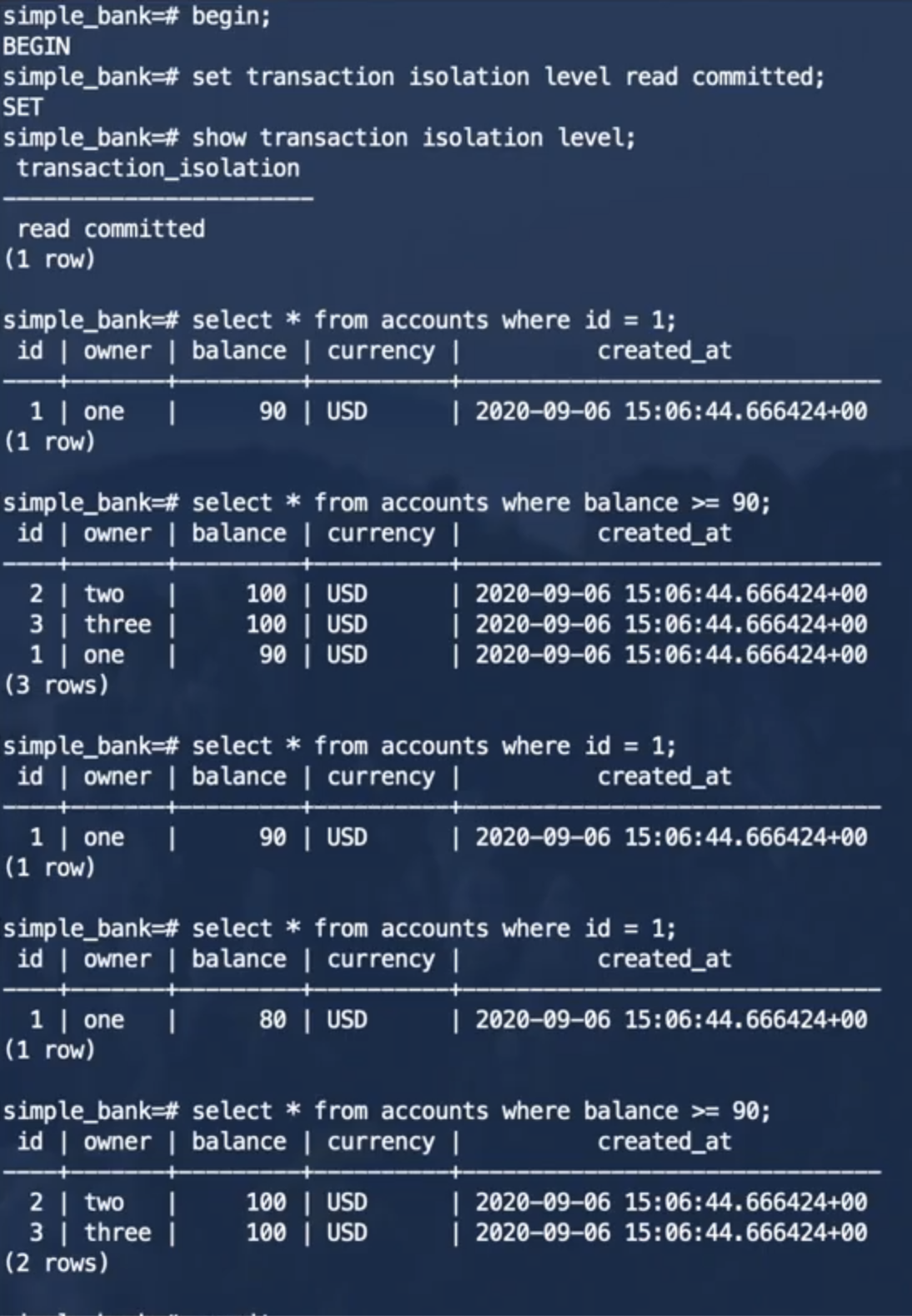
可以看到,事务2并不能读取事务1提交之前所做的修改,防止了脏读的发生,但是在事务1提交之前和提交之后,事务2做同样的查询,得到的结果确是不同的,也就是说,读已提交隔离级别并不能防止不可重复读的发生。
可重复读(REPEATABLE-READ)
可重复读隔离级别可以防止不可重复读的现象,但是不能防止幻读,同样执行事务1和2,这次将隔离级别设置为可重复读(REPEATABLE-READ),看如下两个事务:
| 事务1 | 事务2 |
|---|---|
| begin; | begin; |
| select * from accounts; | select * from acounts where id = 1; |
| select * from accounts where balance >= 80; | |
| update accounts set balance= balance -10 where id =1; | |
| select * from accounts; | select * from accounts where id = 1; |
| select * from accounts where balance >= 80; | |
| commit; | |
| update accounts set balance= balance -10 where id =1; | |
| select * from accounts where id=1; |
在MySQL中的执行效果如下:
事务1:
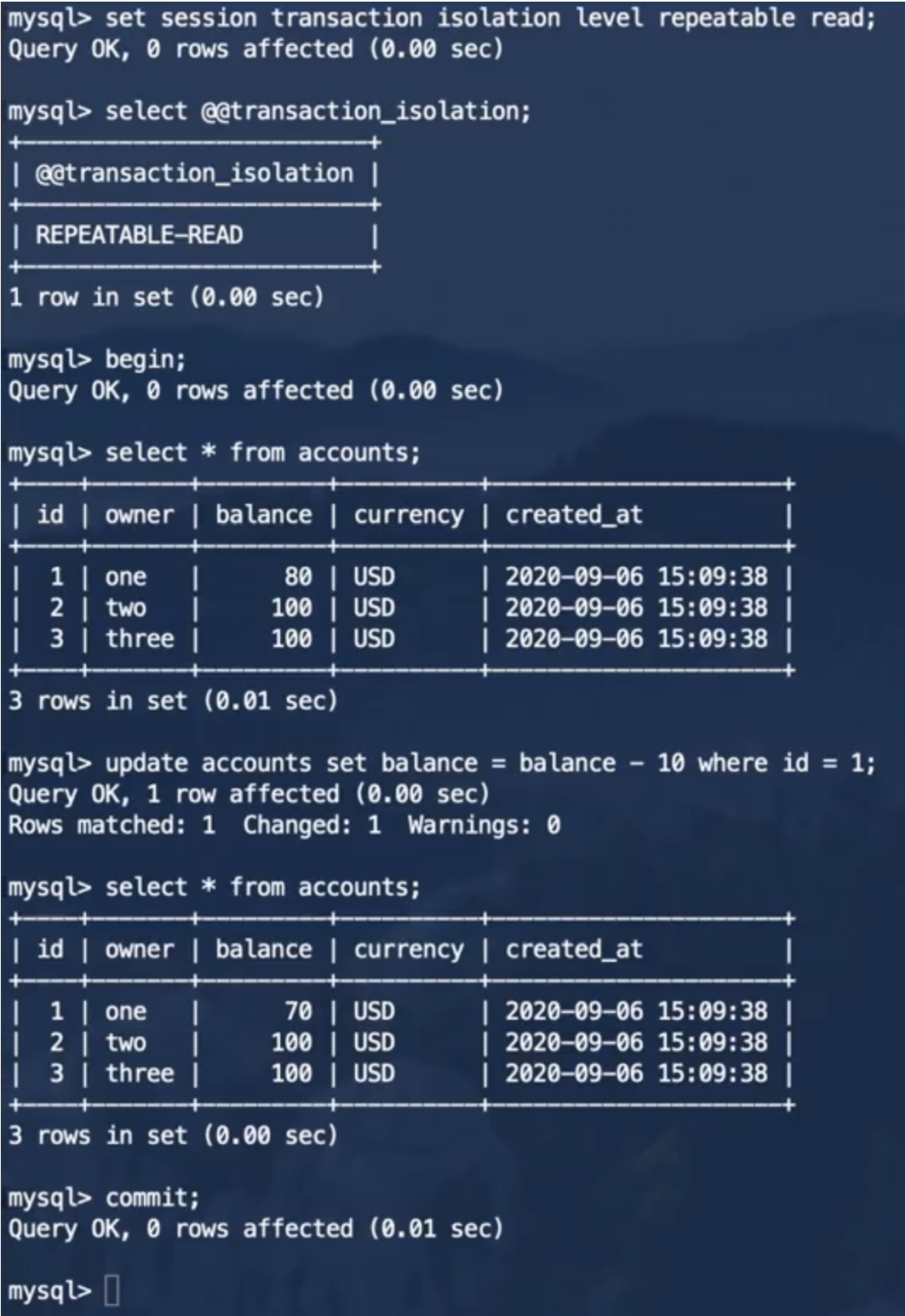
事务2:
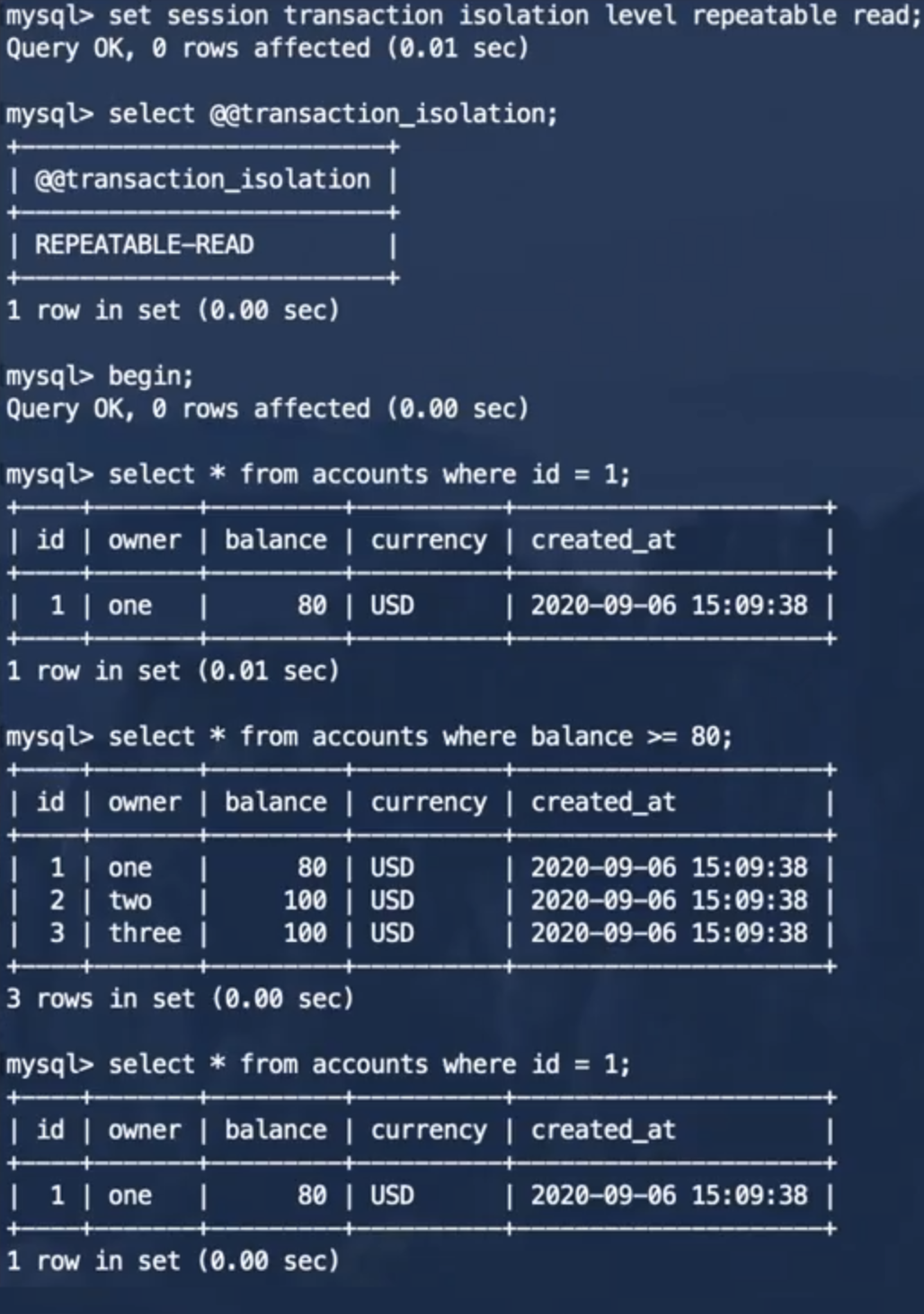
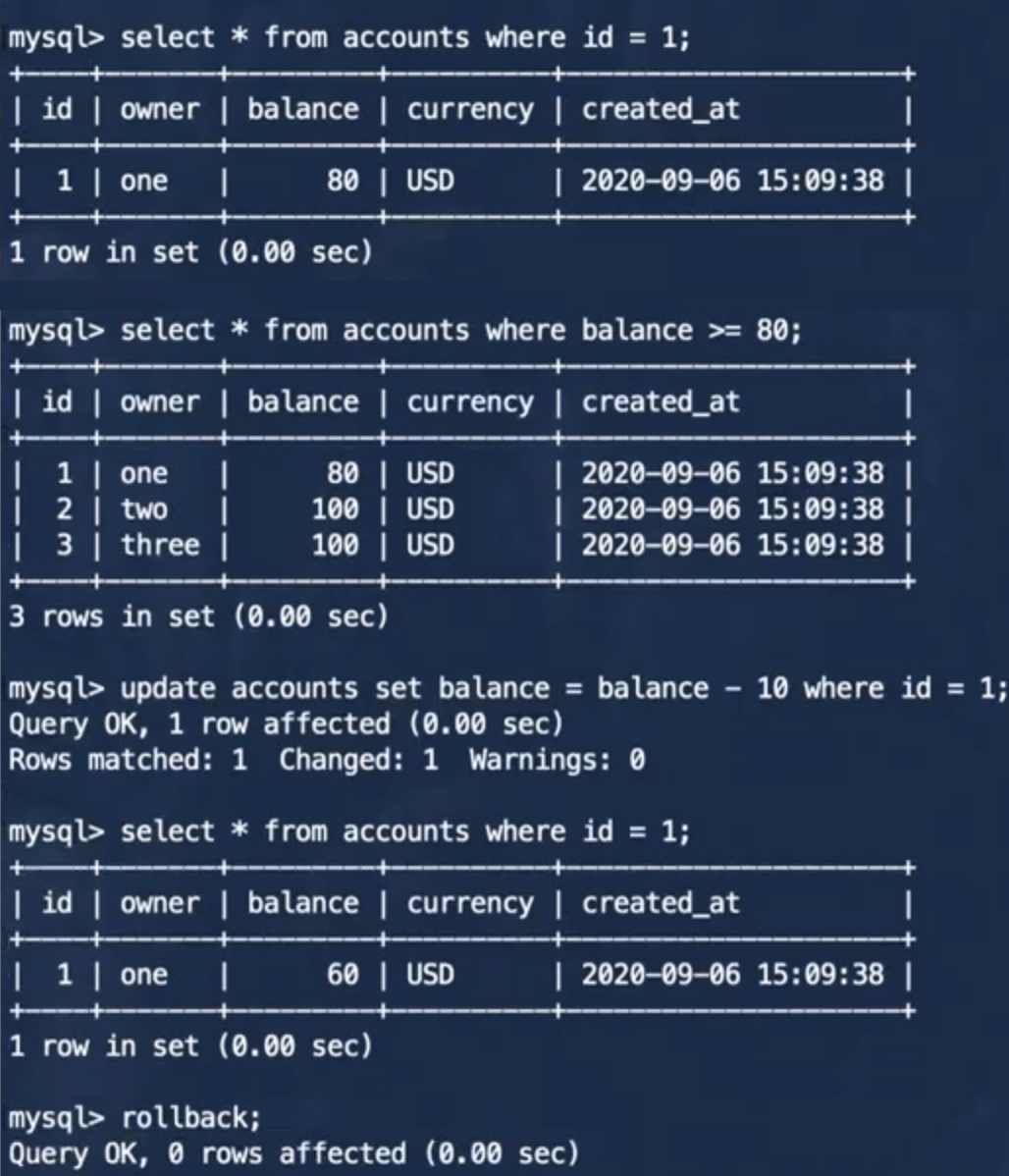
从事务的执行结果我们可以看出,事务2并不会出现不可重复读的现象了,但是对于事务2来说,执行更新操作前查询出的id=1的账户余额为80,执行了一次将id=1的账户余额减少了10的更新操作之后,id=1的账户余额就变为60了,对于事务2来说,这个结果产生了混乱。
在He3DB中执行的效果如下:
事务1:
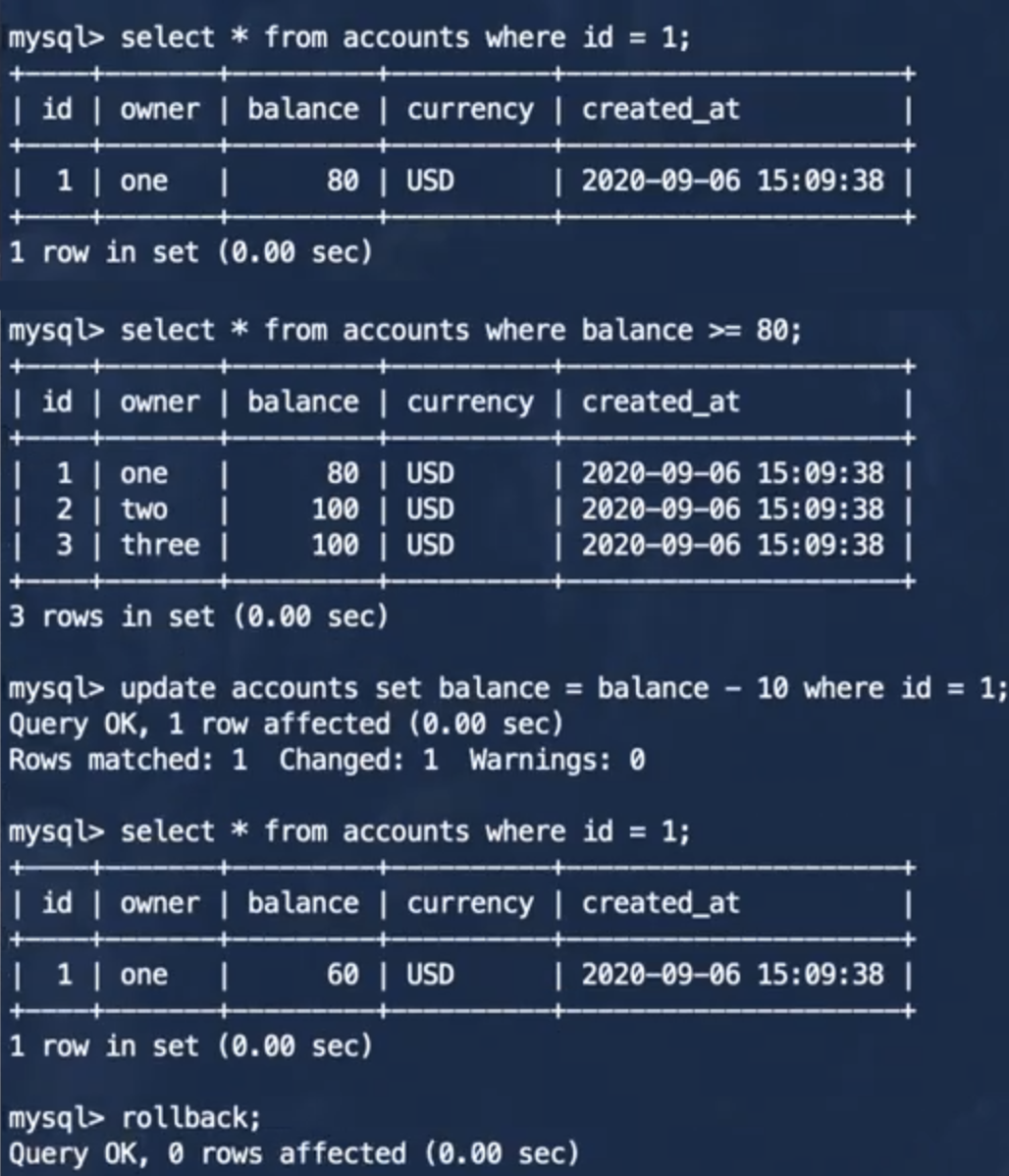
事务2:
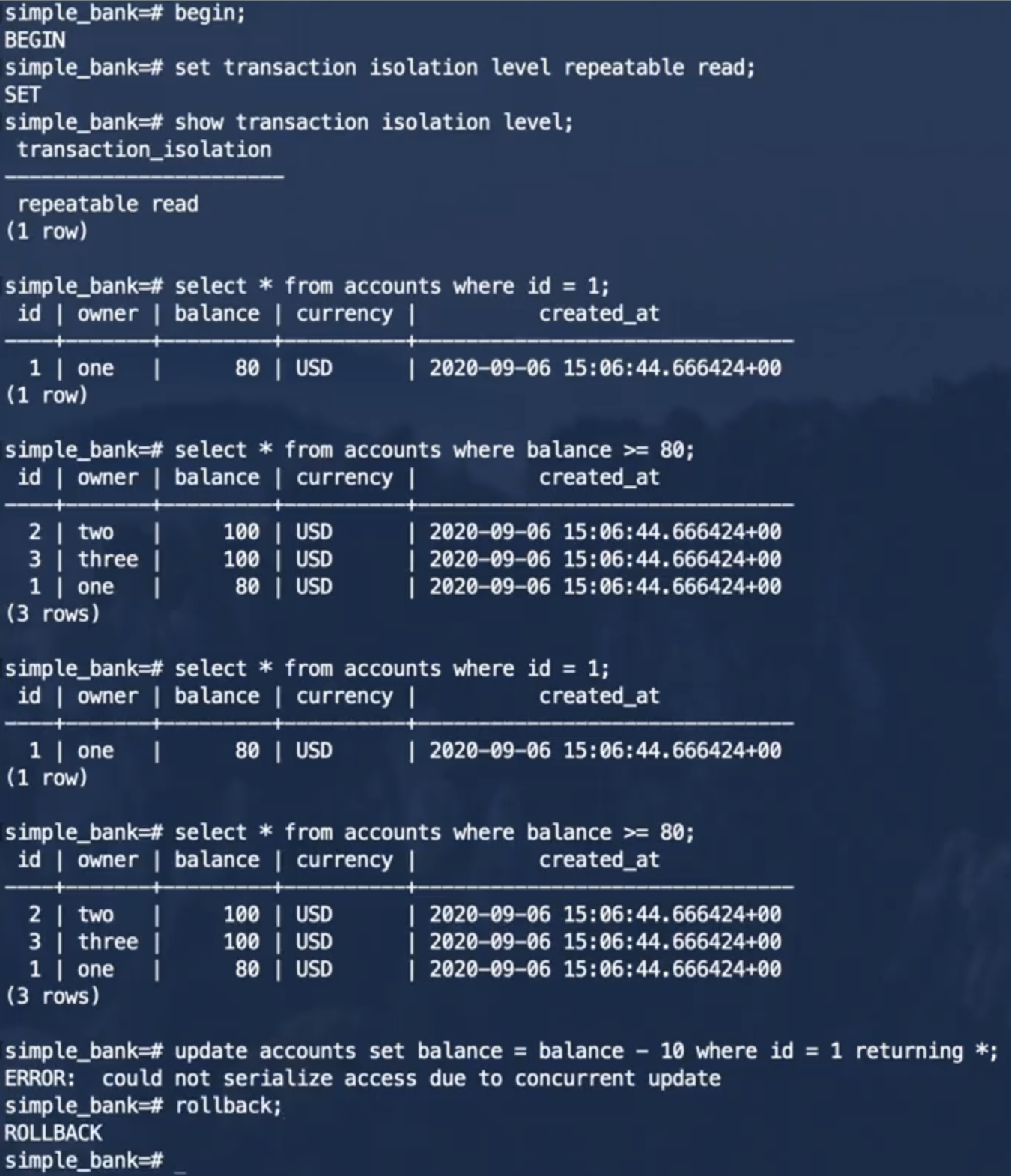
从事务的执行结果可以看出,He3DB不允许事务2进行更新操作,报错信息为:由于并发更新,无法序列化访问,从而避免事务2产生混乱状况,当应用接收到这个错误消息时,应该中断当前事务并且从开头重试整个事务。
由上面运行结果可以看出,不管事务1是否提交,事务2都不能读取到事务1所做的修改操作,对于事务2来说,不会发生幻读现象,但是可重复读并不能解决序列化异常问题。
可序列化(SERIALIZABLE)
序列化异常场景:假设要计算所有账户余额的总和,然后用总余额创建一个新账户。在可重复读隔离级别下执行如下两个事务:
| 事务1 | 事务2 |
|---|---|
| begin; | begin; |
| select * from accounts; | select * from accounts; |
| select sum(balance) from accounts; | select sum(balance) from accounts; |
| insert into accounts (owner, balance, currency) values (‘sum’,270,‘USD’); | insert into accounts (owner, balance, currency) values (‘sum’,270,‘USD’); |
| select * from accounts; | select * from accounts; |
| commit; | commit; |
| select * from accounts; |
在mysql中:
事务1:
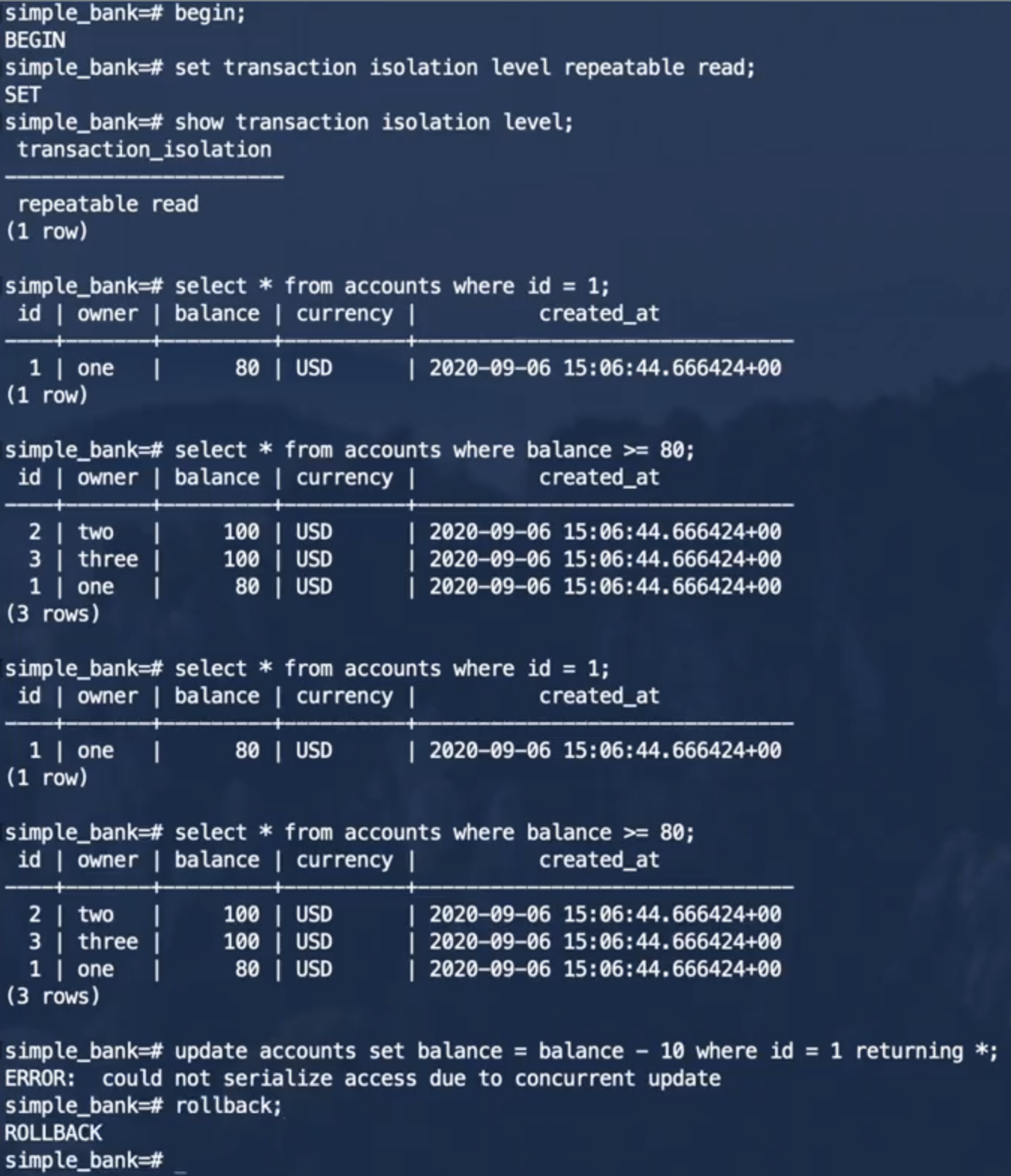
事务2:
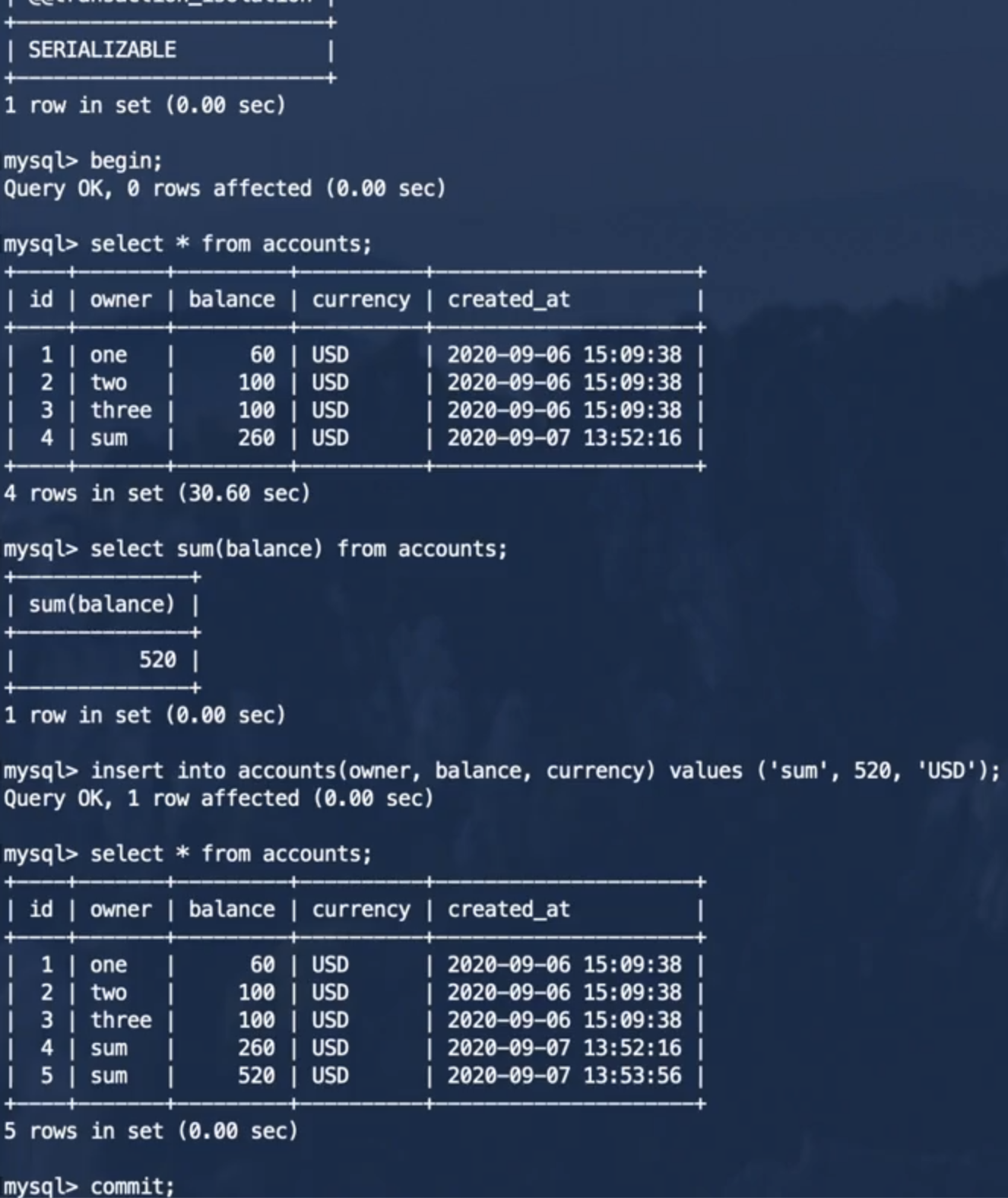
上面事务1中执行insert操作之后,在事务2中执行select操作将会被阻塞,直到事务1提交或者回滚之后,事务2的select操作会立刻产生结果。MySQL中用加锁的方式保证了事务的可序列化。
在He3DB中:
事务1:
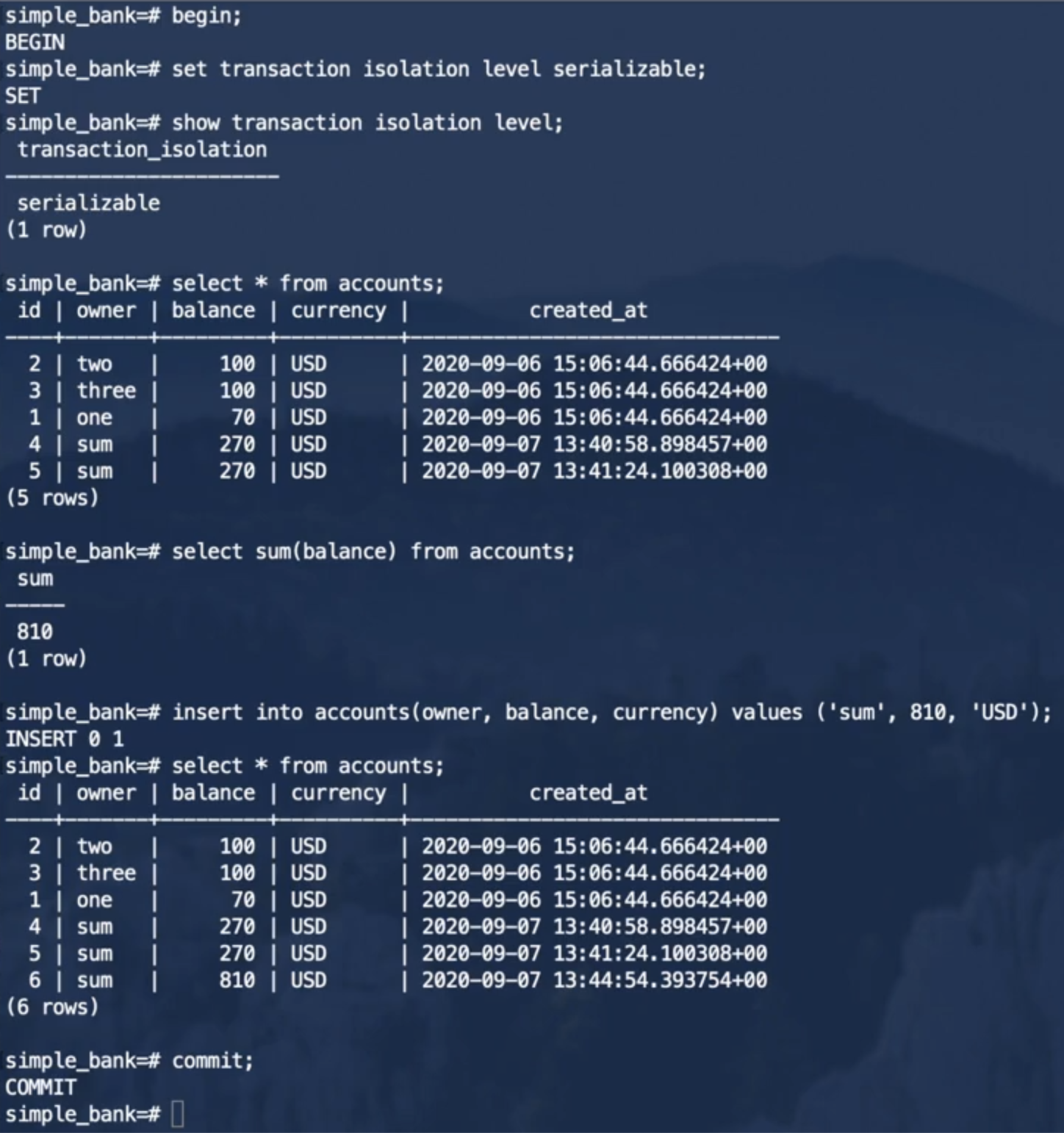
事务2:
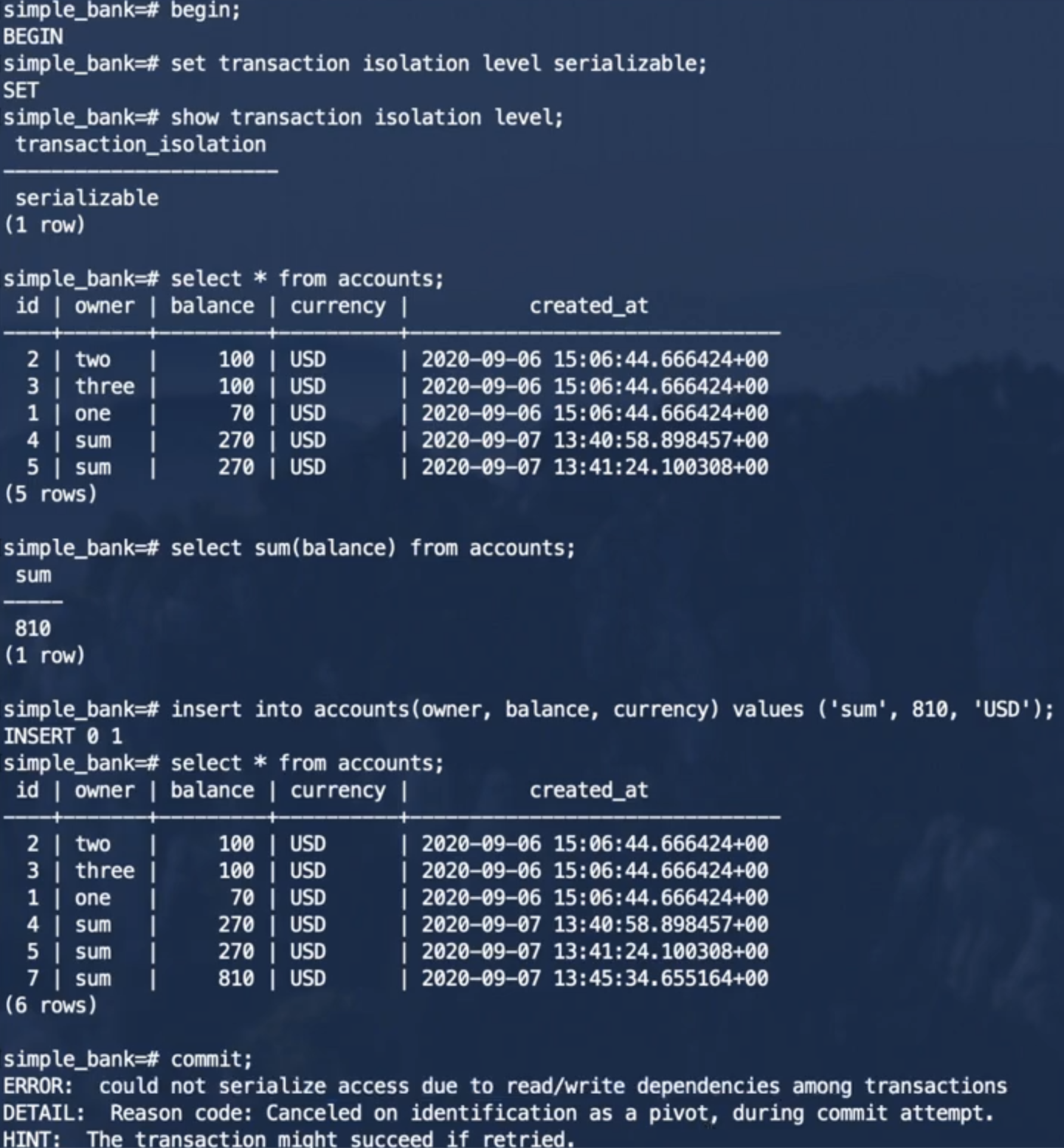
He3DB用抛出错误的方式就避免了序列化异常,两个并发事务并不会像以前那样创建重复记录。
总结
从上面我们可以总结出以下几点:
1、MySQL有四种隔离级别,而postgres只有三种隔离级别(它的读未提交和读已提交这两种隔离级别的效果是一样的)。
2、MySQL对于可重复读隔离级别的实现上可能出现对某个事务来说在逻辑上混乱的情况,而postgres在这种并发场景下会报错,避免产生逻辑上的混乱。
3、对于可序列化隔离级别,MySQL使用锁机制,而postgres使用了依赖检查机制,以检测潜在的读取现象并通过抛出错误来阻止它们。
4、使用高隔离级别时应该注意事务可能会有一些错误、超时甚至死锁,因此,我们应该谨慎的为我们的事务实施重试机制.
