




UTF-8编码
- 环境变量
[root@db01 ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
[root@db01 ~]#
- 文件写入中文后保存退出
[root@db01 ~]# vi utf8.txt
董
[root@db01 ~]# cat utf8.txt
董
[root@db01 ~]# file utf8.txt
utf8.txt: UTF-8 Unicode text
[root@db01 ~]#
- 检查文件编码
为UTF-8
vi utf8.txt
:set fileencoding
# 输出为:fileencoding=utf-8
:set encoding
# 输出为:encoding=utf-8
fileencoding 通常指的是文本文件的当前字符编码。它用于指定正在编辑的文件的字符编码格式。这个设置在打开或保存文件时特别有用,因为它告诉vi编辑器如何正确地解释文件中的字符。
encoding 通常指的是终端或终端会话的字符编码。它用于控制终端会话中文本的显示和输入。设置正确的终端编码很重要,以确保终端能够正确地显示和处理各种字符,特别是非英语字符。
- 查看文件二进制存储内容
存储内容以16进制显示,显示结果中每行的头部8位为偏移量(偏移量是以八进制显示的)
[root@db01 ~]# od -xv utf8.txt
0000000 91e8 0aa3
0000004
[root@db01 ~]#
每行结尾显示的 “0a” 是一个表示换行符(newline)的十六进制值,它表示文本文件的行结束
可利用python进行验证
>>> data = b'\x0a'
>>> old = data.decode('gbk')
>>> print(f'1{old}1')
1
1
>>>
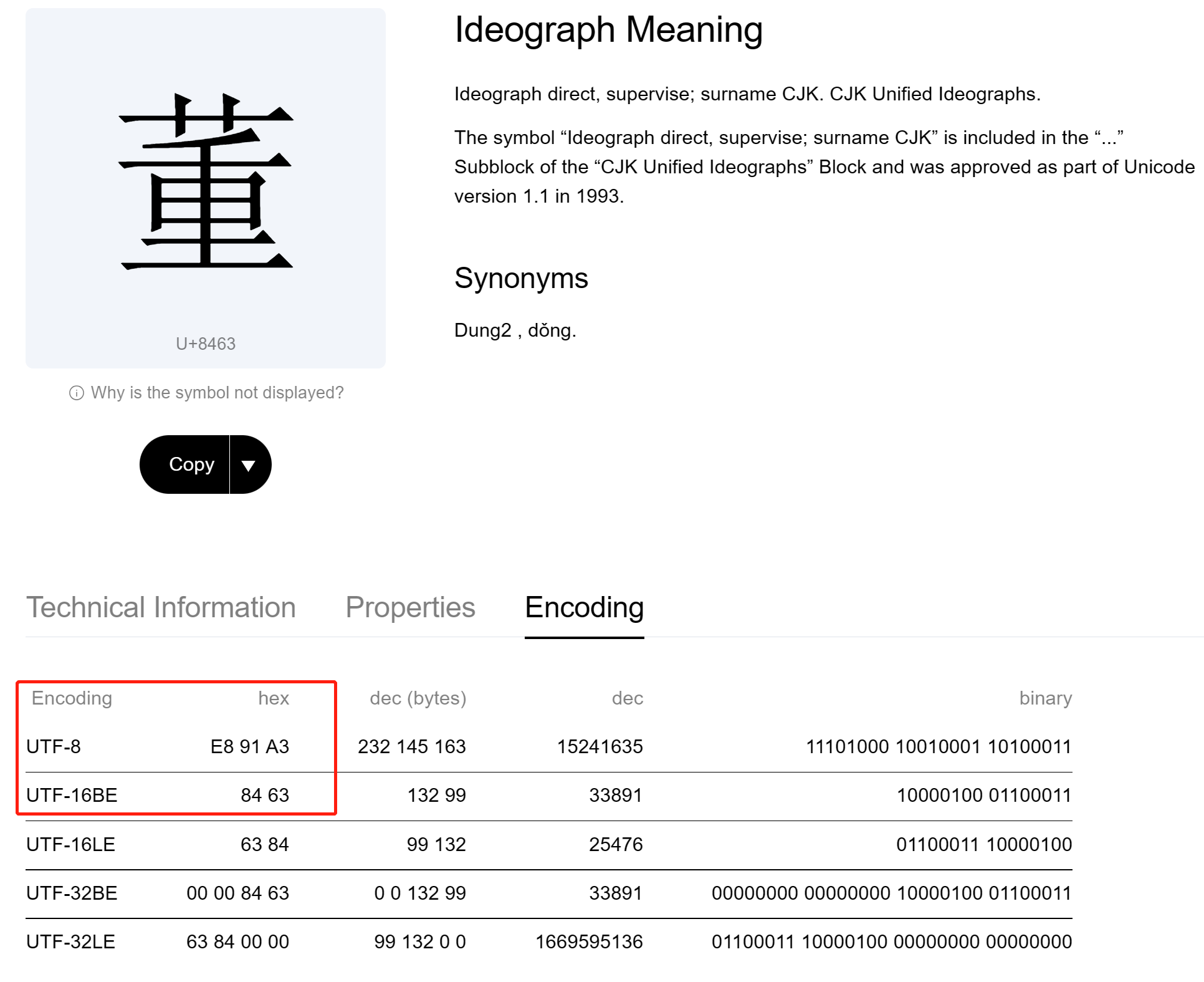
其中e891a3就是汉字董的UTF-8码值,占用3个字节
最后结束符占用1个字节,所以第一行共4个字节,所以第二行偏移量是4
https://symbl.cc/en/
GBK编码
- 确认操作系统安装支持GBK编码环境
[root@db01 ~]# locale -a |grep 'zh_CN.gbk'
zh_CN.gbk
[root@db01 ~]
- 设置操作系统编码并确认
[root@db01 ~]# LANG=zh_CN.gbk
[root@db01 ~]# locale
LANG=zh_CN.gbk
LC_CTYPE="zh_CN.gbk"
LC_NUMERIC="zh_CN.gbk"
LC_TIME="zh_CN.gbk"
LC_COLLATE="zh_CN.gbk"
LC_MONETARY="zh_CN.gbk"
LC_MESSAGES="zh_CN.gbk"
LC_PAPER="zh_CN.gbk"
LC_NAME="zh_CN.gbk"
LC_ADDRESS="zh_CN.gbk"
LC_TELEPHONE="zh_CN.gbk"
LC_MEASUREMENT="zh_CN.gbk"
LC_IDENTIFICATION="zh_CN.gbk"
LC_ALL=
[root@db01 ~]#
-
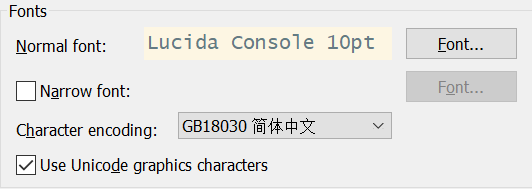
设置终端字符编码为GBK
-
文件写入中文后保存退出
[root@db01 ~]# vi gbk.txt
董
[root@db01 ~]# cat gbk.txt
董
[root@db01 ~]# file gbk.txt
gbk.txt: ISO-8859 text
[root@db01 ~]#
- 检查文件编码
这里测试修改文件编码失败,(iconv和:set fileencoding都不生效),暂时跳过,各位大佬有解决方法欢迎讨论。
即使windows中保存好的gbk字符编码文件,传输到Linux也是这个,区别就是windows和linux的换行符不一样

[root@db01 ~]# file gbk-win.txt
gbk-win.txt: ISO-8859 text, with no line terminators
[root@db01 ~]# cat gbk-win.txt
董[root@db01 ~]
[root@db01 ~]# od -xv gbk-win.txt
0000000 adb6
0000002
[root@db01 ~]#
ISO-8859 标准是一系列字符编码标准,每个标准都适用于特定的字符编码,其中包括 ISO 8859-1、ISO 8859-2、ISO 8859-3 等。这些标准通常被称为 Latin 字符编码,它们主要用于表示欧洲语言的字符。
文件打开编码是按照LANG环境变量来的,其中cp936就是GBK编码
vi gbk.txt
:set fileencoding
# 输出为空:fileencoding=
:set encoding
# 输出为:encoding=cp936
- 修改环境变量
如果此时修改LANG为UTF-8,则vi文件出现乱码,cat正常
因为cat使用的是终端的字符编码,终端的还是GBK,而vi使用的是文件编码和终端的字符编码,所以出现乱码
其中露颅是环境变量UTF-8编码下,终端为GBK字符编码的显示结果。
[root@db01 ~]# LANG=en_US.UTF-8
[root@db01 ~]# cat gbk.txt
董
[root@db01 ~]# more gbk.txt
董
[root@db01 ~]# vi gbk.txt
露颅
- 查看文件二进制存储内容
[root@db01 ~]# od -xv gbk.txt
0000000 adb6 000a
0000003
[root@db01 ~]#
http://www.mytju.com/classcode/tools/encode_gb2312.asp


其中b6ad就是汉字董的gbk码值,占用2个字节
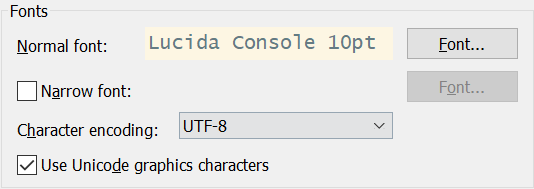
此时如果将终端字符编码改为UTF-8,环境变量也是UTF-8,则显示如下,cat和vi都是乱码的
[root@db01 ~]# cat gbk.txt
]0;root@db01:~[root@db01 ~]#
[root@db01 ~]# vi gbk.txt
¶
总结
UTF-8 是一种通用的Unicode字符编码,支持多种语言。业务系统全栈建议都采用UTF-8字符编码:应用程序端字符编码,数据库字符集,操作系统环境变量字符编码,终端工具字符编码都用UTF-8。
订阅号:DongDB手记
墨天轮:https://www.modb.pro/u/231198

