




GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
实验环境: CentOS Linux release 7.6.1810 (Core) Oracle Database 18c Express |
GROUP BY 的基本使用
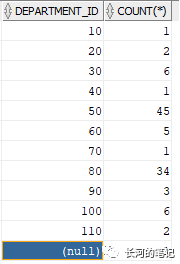
标准的group by 语句,一般都结合聚合函数使用,比如下面的sql, 按部门分组列出员工数量,显示部门ID。
select department_id,count(*) from hr.employeesgroup by department_id order by 1,2;
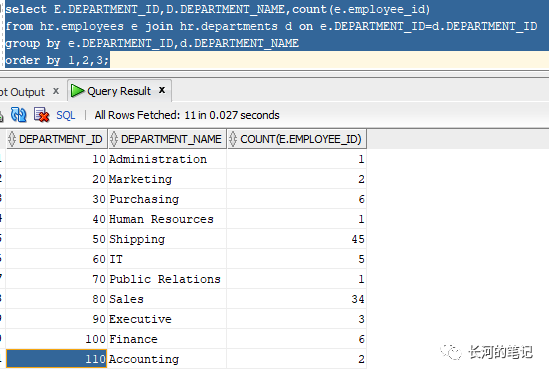
再扩展一些,同样按部门分组列出员工数量,联合多个表显示部门ID和部门名称。
注意Group by 后面接部门ID和部门名称。
select语句中的非聚合字段,必须出现在group by以后。
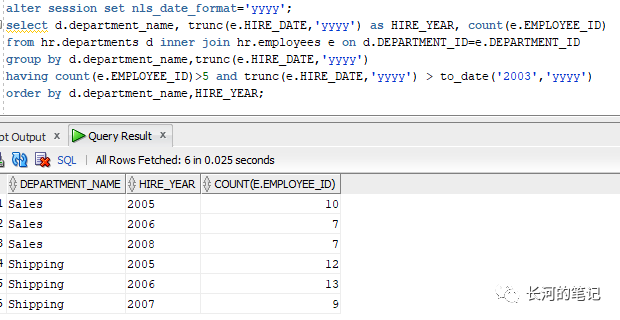
可以使用having子句对分组结果进行过滤, 注意having与where不同的是,where是对select结果进行过滤,发生在分组之前。having是对group by 以后的结果进行过滤,是在分组之后。
例如下面的2个sql, 按部门和出生年度分组列出员工数量,只统计员工数量大于5人的部门和2003年出生以后的人员。
只统计员工数量大于5人的部门这个需求,是group by以后产生的结果,所以必须使用having过滤。而统计2003年出生以后的人员这个需求,可以在group by 前,也可以在group by 以后,所以下面2个sql的结果是一样的。
alter session set nls_date_format='yyyy';select d.department_name, trunc(e.HIRE_DATE,'yyyy') as HIRE_YEAR, count(e.EMPLOYEE_ID)from hr.departments d inner join hr.employees e on d.DEPARTMENT_ID=e.DEPARTMENT_IDgroup by d.department_name,trunc(e.HIRE_DATE,'yyyy')having count(e.EMPLOYEE_ID)>5 and trunc(e.HIRE_DATE,'yyyy') > to_date('2003','yyyy')order by d.department_name,HIRE_YEAR;select d.department_name, trunc(e.HIRE_DATE,'yyyy') as HIRE_YEAR, count(e.EMPLOYEE_ID)from hr.departments d inner join hr.employees e on d.DEPARTMENT_ID=e.DEPARTMENT_IDwhere trunc(e.HIRE_DATE,'yyyy') > to_date('2003','yyyy')group by d.department_name,trunc(e.HIRE_DATE,'yyyy')having count(e.EMPLOYEE_ID)>5order by d.department_name,HIRE_YEAR;
从结果可以看到满足上述2个条件的部门只有sales 和 shipping部门,其它的都被过滤掉了。
GROUP BY 的扩展功能
1. CUBE
同样是上面的需求,让我们看看使用CUBE可以实现什么样的功能?
select rownum,a.* from (select d.department_name,trunc(HIRE_DATE,'yyyy') as HIRE_YEAR,count(e.employee_id) as cnt_emp,round(avg(salary)) as avg_salaryfrom hr.departments d inner join hr.employees e on d.DEPARTMENT_ID=e.DEPARTMENT_IDwhere trunc(e.HIRE_DATE,'yyyy') > to_date('2003','yyyy')group by cube(department_name,trunc(HIRE_DATE,'yyyy'))having count(e.EMPLOYEE_ID)>5order by 1,2) a;
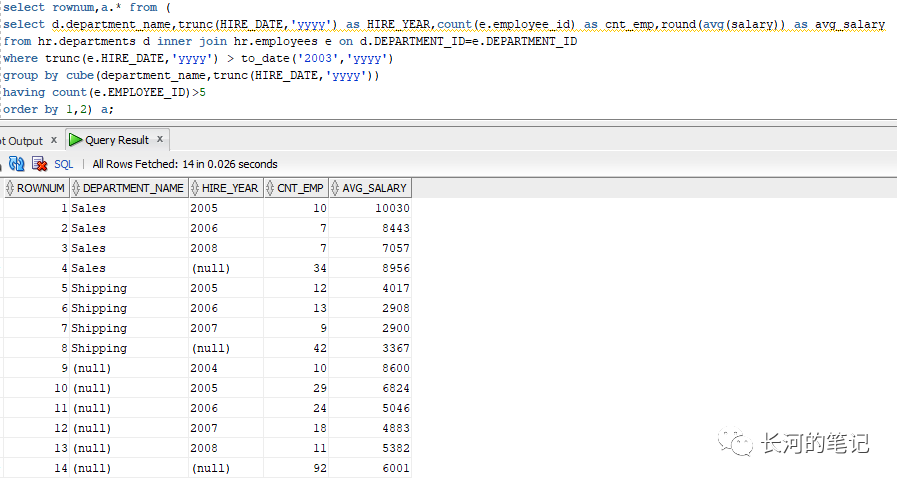
同样的sql, 在GROUP BY子句加入cube之后会发现多了几行,如上图的4,8,9,10,11,12,13,14行,
第4,8行分别显示了sales,shipping2个部门的员工数量和平均工资,其结果相当于group by department_name。
第9,10,11,12,13行分别显示了2004,2005,2006,2007,2008年出生的员工的数量和平均工资,结果相当于group bytrunc(HIRE_DATE,'yyyy')。
第14行显示了所有满足where条件(hire_date> 2003)记录的员工数量和平均工资,结果就是所有记录作为一组。
那么总结下CUBE的功能,在原有的group by结果基础上,它还实现了从多维度,即所有group by字段中的组合分组统计数据。使用CUBE会产生2^N个分组。
CUBE(a,b) 相当于 group by (a,b) + group by a + group byb + group by all returned rows
CUBE(a,b,c) 相当于 group by (a,b,c) + group by (a,b) +group by (a,c) + group by a + group by (b,c) + group by b + group by c+ groupby all returned rows
2. ROLLUP
下面的sql使用rollup实现了,按部门和岗位分组列出员工数量和平均工资。
select d.department_name,j.job_title,count(employee_id) as cnt_emp,round(avg(salary)) as avg_salaryfrom hr.employees e join hr.departments d on e.department_id=d.department_id join jobs j on e.job_id=j.job_idgroup by rollup(d.department_name,j.job_title)order by 1,2;
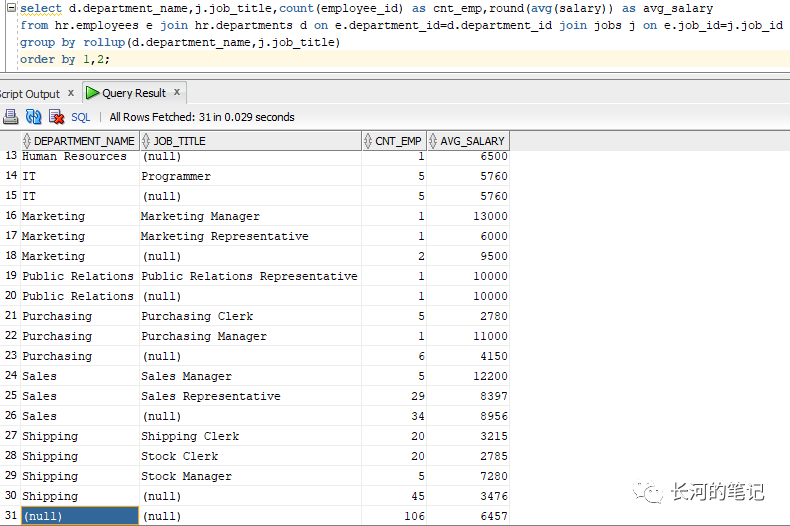
在GROUP BY后加入rollup会发现多了几行,如上图带有(null)的行都是rollup功能多出来的。
第15,18,20,23,26,30行分别显示了按部门分组的员工数量和平均工资,结果相当于group by department_name
第31行显示了所有员工数量和平均工资,因为没有where条件所以是所有,结果就是所有记录作为一组,相当于group by ()
那么总结下ROLLUP的功能,就是在原有的group by结果基础上,它还实现了多层递减的分组统计数据。 使用ROLLUP会产生N+1个分组。
rollup(a,b) 相当于 group by (a,b) + group by a + group byall returned rows
rollup(a,b,c) 相当于 group by (a,b,c) + group by (a,b) + group by(a) + group by all returned rows
3. GROUPING SETS
可以看到,上面的cube和rollup都给出了多种分组结果。grouping sets是可以自定义分组结果,比如说你觉得cube或rollup的分组结果太多,只想取其中的几种分组结果,那么就可以使用grouping sets。比如使用groupby grouping sets(A,B,C),则分别对A,B,C进行groupby,再比如使用group by groupingsets((A,B),C),则对(A,B)和C进行groupby。
使用grouping sets会产生N个分组。
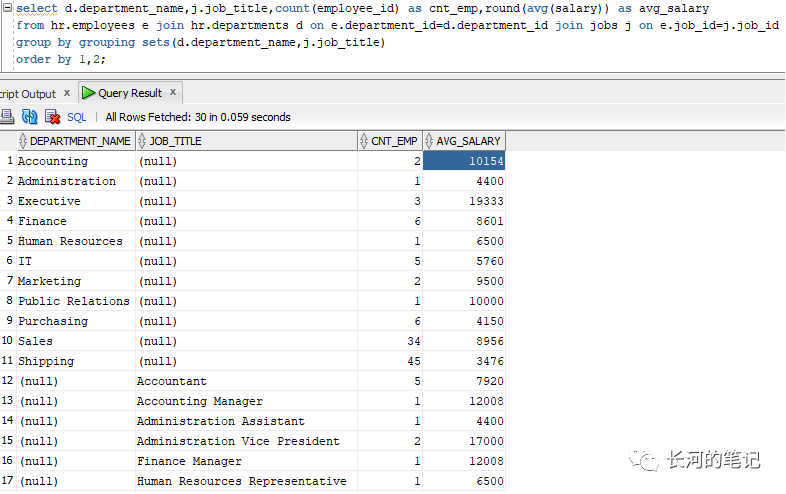
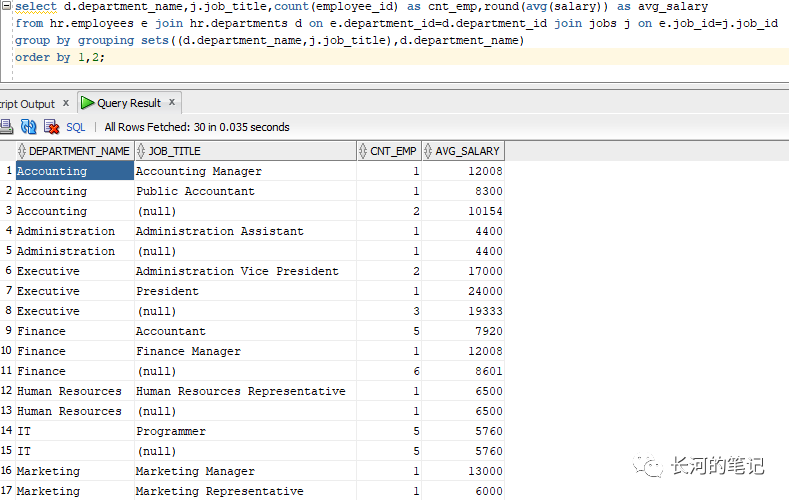
4. GROUPING()函数
可以看到,上面所有结果中有很多(null)的行,有时候这些行可能会给你带来混淆,利用grouping函数可以让你分辨出哪些行是数据库中本来的行,哪些行是grouping计算产生的行。Grouping()函数的返回值有2个, 0表示这行是数据库中本来的值,1表示这行是grouping计算后产生的行。Grouping()参数只能有一个,并且必须为group by中出现的某一列。
比如下面的sql显示了,按部门和岗位分组列出员工数量和平均工资,使用了rollup扩展,那么rollup功能所带来的额外的行就不属于数据库中本来的行。当这些行使用grouping()时,返回值就是1。我们使用decode函数,使这些行的显示不再是(null), 而是手工指定显示值"All departments" 和 "All Job",这样是不是更友好了呢。
select decode(grouping(d.department_name),1,'All departments',d.department_name) as department_name,decode(grouping(j.job_title),1,'All Job',j.job_title) as job_title,count(employee_id) as cnt_emp,round(avg(salary)) as avg_salaryfrom hr.employees e join hr.departments d on e.department_id=d.department_id join jobs j on e.job_id=j.job_idgroup by rollup(d.department_name,j.job_title);
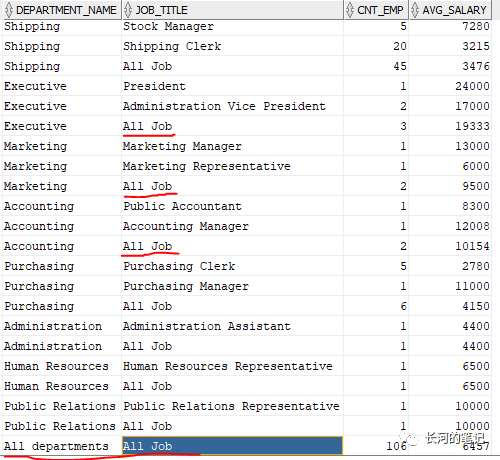
5. GROUPING_ID()函数
grouping_id()属于grouping()的改进型函数,只需要使用一个函数,就能完成上面使用多个grouping()才能完成的效果。grouping_id()函数可以有多个参数,它的返回值是一个二进制向量,还是以例子说明下。
select grouping_id(d.department_name,j.job_title) as grouping_ID,d.department_name,j.job_title,count(e.employee_id) as cnt_emp,round(avg(e.salary)) as avg_salaryfrom hr.employees e join hr.departments d on e.department_id=d.department_id join hr.jobs j on e.job_id=j.job_idgroup by rollup(d.department_name,j.job_title);
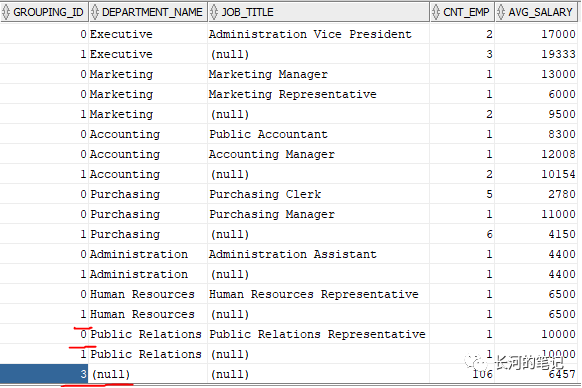
这里grouping_id返回的值有0,1,3。它是一个组合值。比如一行中grouping(a)返回值是0,grouping(b)返回值也是0,那么grouping_id(a,b)返回值是二进制的00,转换成十进制显示也是0。再比如一行中grouping(a)返回值是0,grouping(b)返回值是1,那么grouping_id(a,b)返回值是二进制的01,转换成十进制显示是1。同理grouping_id(a,b)返回值是二进制的11,转换成十进制显示的是3。通过这个返回代码我们只需要使用一次函数就可以对不同的分组方案进行标识,代码执行效率上要比grouping要高。
好了,目前为止我们学习了Oracle的基本group by用法和cube,rollup等扩展。现在让我们看看PG中有没有这些神奇的功能吧。
实验环境: CentOS Linux release 7.6.1810 (Core) PostgreSQL 10.10 |
基本的group by 和having子句PG都是支持的,这点与使用oracle时一样。
创建一个测试表:
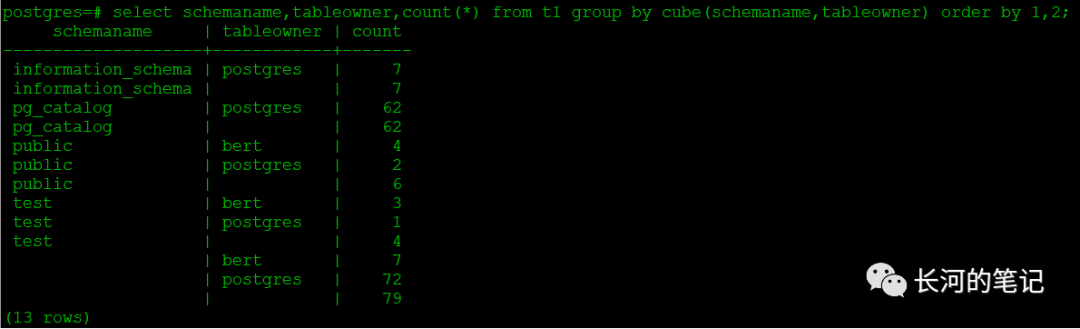
postgres=# create table t1 as select * from pg_tables;SELECT 79postgres=# \d t1Table "public.t1"Column | Type | Collation | Nullable | Default-------------+---------+-----------+----------+---------schemaname | name | | |tablename | name | | |tableowner | name | | |tablespace | name | | |hasindexes | boolean | | |hasrules | boolean | | |hastriggers | boolean | | |rowsecurity | boolean | | |postgres=# select schemaname,tableowner,count(*) from t1 group by schemaname,tableowner;schemaname | tableowner | count--------------------+------------+-------test | bert | 3public | bert | 4pg_catalog | postgres | 62public | postgres | 2test | postgres | 1information_schema | postgres | 7(6 rows)
1. CUBE
可以看到pg中同样也支持cube扩展,使用方法与Oracle一致。
postgres=# select schemaname,tableowner,count(*) from t1postgres=# group by cube(schemaname,tableowner);
2. ROLLUP
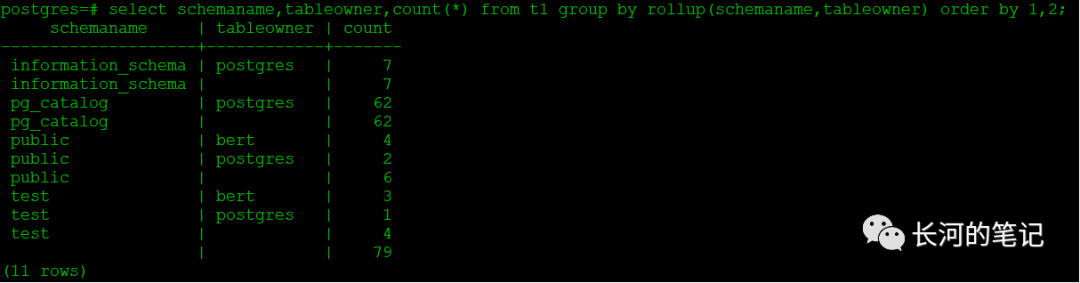
可以看到pg中同样也支持rollup扩展,使用方法与Oracle一致。
3. GROUPING SETS
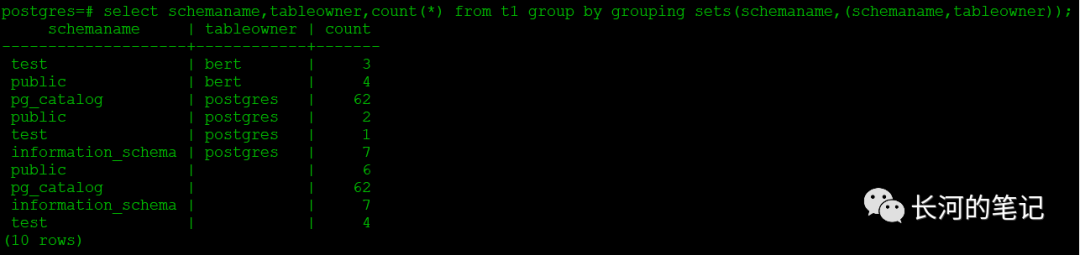
可以看到pg中同样也支持grouping sets扩展,使用方法与Oracle一致。
但是很遗憾,在PG中没有找到类似grouping_id()这样的函数,如果大家知道,还请告知。
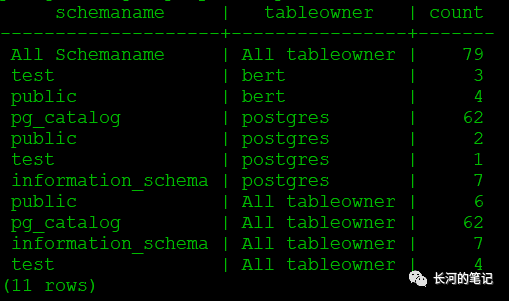
所以如果想用自定义的值替换null值,可以借鉴下面的sql
select(case when schemaname is null then 'All Schemaname' else schemaname end) as SchemaName,(case when tableowner is null then 'All tableowner' else tableowner end) as TableOwner,count(*)from t1group by rollup(schemaname,tableowner);
GROUP BY 使用限制
Group by 的使用限制,在group by子句中不能使用LOB, 嵌套表,数组和子查询。
END

