






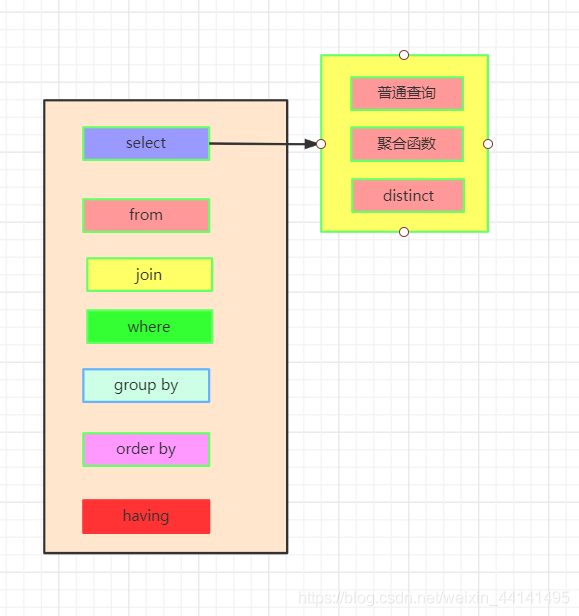
from 子句组装来自不同数据源的数据;
where 子句基于指定的条件对记录行进行筛选;
group by 子句将数据划分为多个分组;
使用聚集函数进行计算;
使用 having 子句筛选分组;
计算所有的表达式;
select 的字段;
使用 order by 对结果集进行排序。
SQL 语言不同于其他编程语言的最明显特征是处理代码的顺序。在大多数据库语言中,代码按编码顺序被处理。但在 SQL 语句中,第一个被处理的子句式 FROM,而不是第一出现的 SELECT。
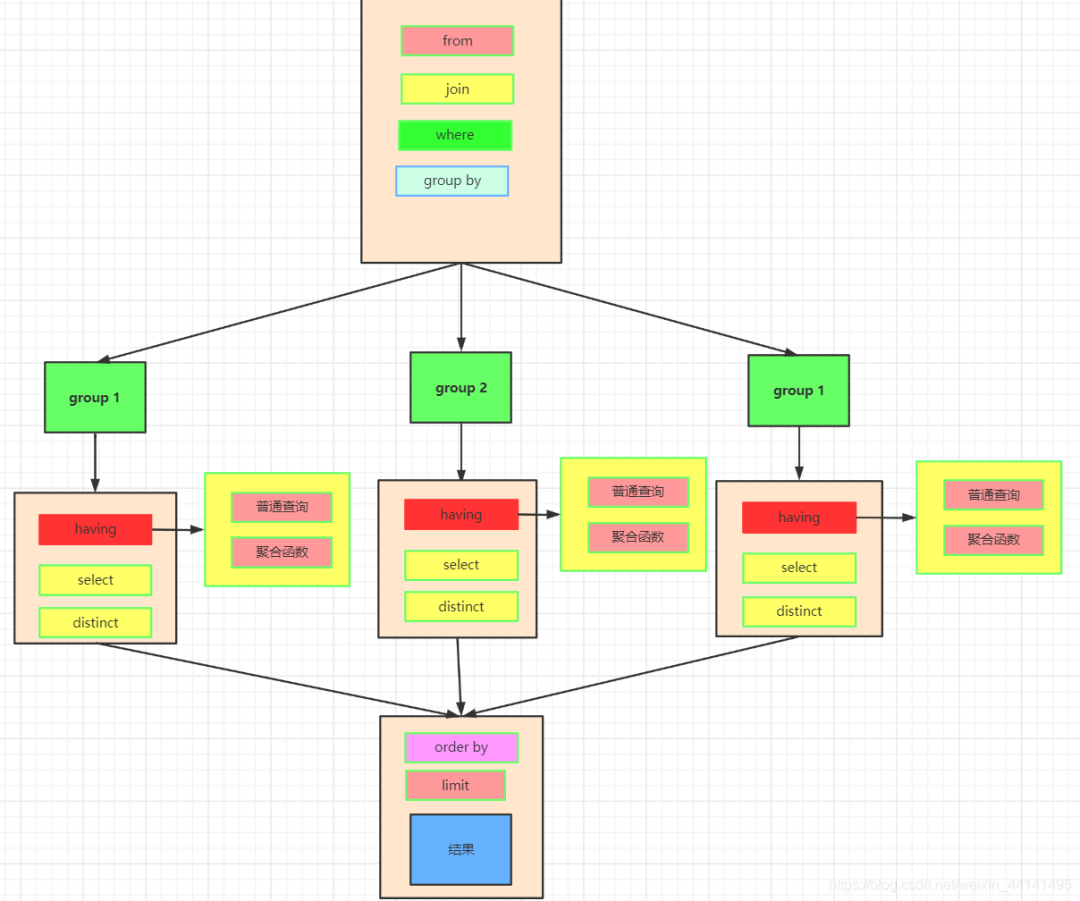
SQL 查询处理的步骤:
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
WITH {CUBE | ROLLUP}
HAVING <having_condition>
SELECT (9) DISTINCT
ORDER BY <order_by_list>
<TOP_specification> <select_list>
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应 用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句, 将跳过相应的步骤。
数据的关联过程
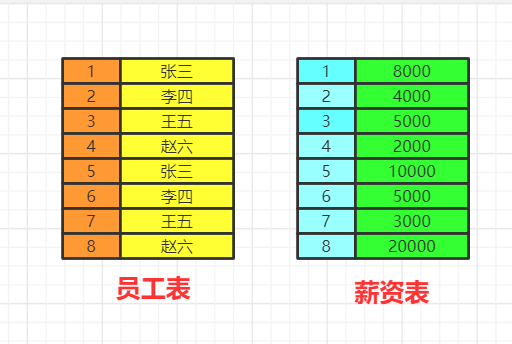
from&join&where
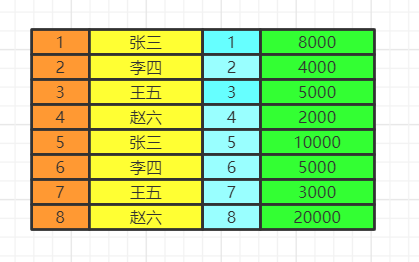
from table1 join table2 on table1.id=table2.id
from table1,table2 where table1.id=table2.id
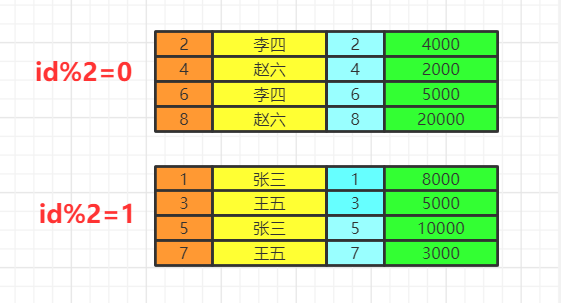
group by
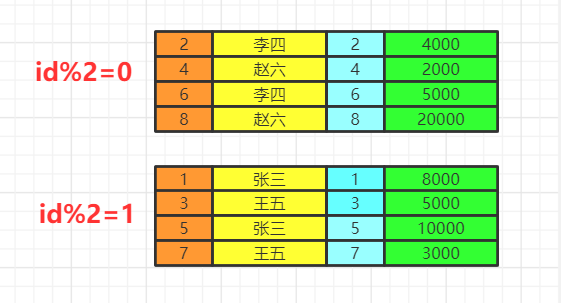
having&where
使用where再group by
使用group by再having
100/2=50,此时我们把100拆分
(10+10+10+10+10…)/2=5+5+5+…+5=50,只要筛选条件没变,即便是分组了也得满足筛选条件,所以where后group by 和group by再having是不影响结果的!
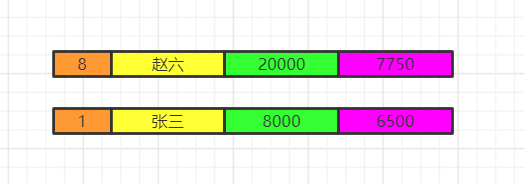
having salary<avg(salary)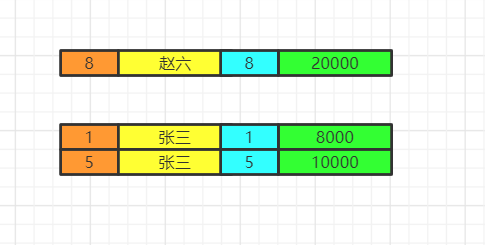
select
select employee.id,distinct name,salary, avg(salary)
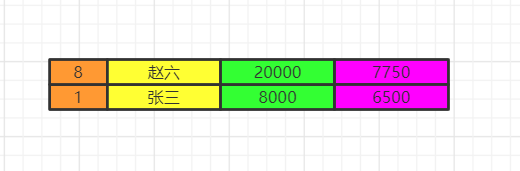
order by
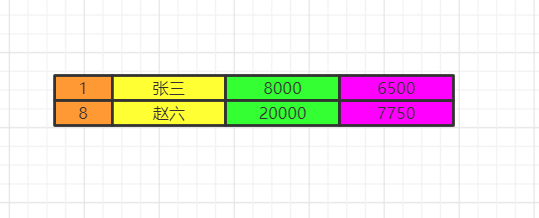
limit
更多精彩内容,关注我们▼▼

文章转载自数据与人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
